
Summary
Delivering application code at a high pace is possible using GitHub Actions. It lets you automate and manage CICD workflows directly from your GitHub repositories. By using GitHub Actions you can build, test, and deliver code automatically, fast, and safely. You can use any webhook to trigger events such as automatically building and testing code for each pull request.
In other words, you can create your CI pipelines with ease. Theoretically, everything looks fine but when it comes to practice “everything fails, all the time” as AWS CTO, Werner Vogels says.
Foresight is the missing observability piece of GitHub Actions! Foresight provides CI and test observability into your GitHub Actions workflows, helping you maintain their health and performance. In this post, we will cover the need for getting notified about the CI workflow or test failures and how Foresight helps.
What is the challenge?
Missing critical changes that may end up with production bugs is a huge FOMO. Nobody sits all day and monitors their software. But when something goes wrong, missing it can cause serious problems. Developers, DevOps, SREs, testers, QAs, and engineering leaders often face this challenge.
Pinpointing the root cause of errors in your CI workflows and tests as they occur might be vital on some occasions. For example when introducing a new feature to production, it might not have been well tested enough. Or you can easily introduce a bug into production because a flaky test passed and your build ended with success.
Some of the critical challenges that you can overcome by using proactive alerting such as Foresight “rules” are;
- Affected Users. Not being aware of errors, latencies or critical changes in your CI workflows or tests may let you introduce bugs to your production environment. Your end users can get badly affected due to this reason.
- Cost. Missing critical errors or latencies may cause high costs.
- Visibility. Existing APM or error tracking tools lack a holistic view of your test and CI workflows’ health and performance.
- Speed. Increased time-to-detect due to a lack of monitoring and observability across CI workflows and tests.
- Restoration. Higher mean-time-to-recover because of lacking CI observability and poor notification.
- Collaboration issues. Disparate tooling across the organization complicates cross-team collaboration.
Below is a solid use case that happens in an engineering team. In this use case; build times increase and developers don’t know the reason why. It starts impacting the developer productivity and their engineering manager finds a solution.

Anatomy of a rule
Rules lets you set up robust and customizable policies for your workflows and tests. You can receive notifications for fluctuations in key performance metrics as your workflows run.
The below gif showcases how to create a rule in Foresight for your workflows and tests.

Predefined rule templates
We’ve made some rule templates for you to easily set your rules for your workflows within a couple of clicks. We got inspired by our customers’ needs and requirements while creating these rule templates. Below are some examples of the templates we created for you.
- Increase in the duration of a workflow compared to the previous week.
Whenever the average duration of a workflow increases from 4mins to 5mins, you will get a notification.

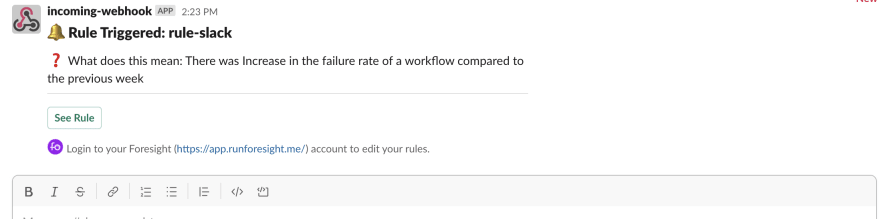
- Increase in the failure rate of a workflow compared to the previous week.
When the failure rate of a workflow increases from 10% to 30%, you will get a notification

- Workflow failure rate exceeds the limit set
When a failure rate of a workflow exceeds 10%, you will get a notification.

Notification Channels
Foresight rules are a powerful tool for ensuring your CI workflows’ integrity. Notification alerts let you filter on a number of different aspects of your CI workflows’ and tests’ behavior, tying multiple complex objects together behind a unifying rules interface that is both easy to use and high-powered.
You can connect your Foresight rules notifications with incident management tools like PagerDuty and Opsgenie. You can choose directly receive notifications to your email or Slack. Or else, you can connect them anywhere through webhook. With configurable rules, you can rely upon Foresight alerts to provide you with up-to-date information when things go wrong.

How to make your CI pipeline shine
With Foresight, you won’t miss any critical information such as a change, a failure, a latency, etc. from now on. You can receive notifications for fluctuations in your key CI performance metrics.
You can set your rules to get notified about critical changes, and flow them through your Slack, email, PagerDuty, OpsGenie, and more.
You can quickly remediate failing builds and performance regressions, allowing your teams to focus on developing new features. Just set up your alert rule to be notified when a test is longer than usual and optimize slow tests to speed up your pipelines.
Here’s what you can achieve by having an observable CI pipeline that notifies you correctly:
- Reliable Products. By being able to pinpoint any deficiencies or regressions as they occur, engineering teams can deliver more robust and reliable products.
- Faster delivery. Automating notifications over CI and test failures lead to faster test cycles, which accelerates deployment frequency.
- MTTR. Resolving deficiencies quickly before going to production drastically helps to decrease the mean time to resolution.
- Productivity. Developer productivity is boosted when their strings are not attached. Developers start spending more time on innovation and improving the customer experience and less time putting out fires.
- Easier Audits. You can log your notifications and actions taken afterward, enabling post-incident review.
- Executive Trust and Confidence. Because incidents are resolved quickly with little customer impact, executives no longer lose sleep at night and trust that CICD pipelines will stay up and available.
To get started, all you have to do is to install Foresight’s GitHub application and signup for Foresight to get your account. It is FREE for open-source projects and has a very generous free plan for small and medium sized organizations.


TL;DR
Foresight’s “rules” feature brings the ability to stay on top of any changes in your CI pipelines. Missing critical changes that may end up with production bugs is a huge FOMO. To overcome this, we came up with “rules” that make it possible to define potential scenarios and automated actions when prerequisites are met.
To be more precise, you can say “Send an alert notification with a high severity to my PagerDuty when my xyz CI pipeline’s failure rate exceeds 10%”.
Or you can make comparisons such as “Send a notification to my Slack when there’s an increase in the average duration of my xyz workflow compared to the previous week”.
Go ahead and take action to improve your developer productivity. If you realize your current setup isn’t providing enough control over your CI metrics, try using Foresight to proactively monitor your CI workflows and tests.
Up on the horizon, we’ll be coming up with much more advanced querying and alerting capabilities of Foresight “rules”. We’ll be happy to listen to your ideas and needs to facilitate success in your CI workflows using Foresight.
For more information about configuring our integration, refer to our docs. Please submit your requests to support@runforesight.com or come to our Discord community and let’s chat. You can sign up for Foresight or see the live demo to see Foresight in action.





Top comments (0)