Software projects tend to become very complex and difficult to maintain. With the help of refactoring, the code can be made relatively easy to understand. However, in a real-world project, it seems impossible to have a very high code quality everywhere.
For the hotspots of a program, the locations with a high complexity and change rate, the refactoring efforts will most likely have the highest return on investment. This blog post explores a way how they can be identified in a Java project.
Apache Wicket was chosen as an example project. For its analysis, the open-source tools SonarCube, Code Charta, and Code Maat, and Python scripting are being used. The complexity is measured with SonarCube's Cognitive complexity metric and the change rate by the number of commits for a particular file.
Environment
The steps below are done in a DigitalOcean droplet, except of the final visualization.
- Ubuntu 18.04
- Pre-installed Docker
Preparation
Download of required repositories
The following repositories will be required along they way:
mkdir ~/src && cd ~/src
git clone https://github.com/apache/wicket.git
git clone https://github.com/adamtornhill/code-maat.git
git clone https://github.com/experimental-software/code-analytics.git
Tool setup
A SonarCube server can be started with this docker run instruction:
docker run --env ES_JAVA_OPTS="-Xms750m -Xmx750m" -d -p 9000:9000 -p 9092:9092 sonarqube
We will also need a couple of system tools later:
apt update && apt install maven npm leiningen unzip -y
Code Charta needs to be installed via the Node Package Manager:
npm install codecharta-analysis -g
npm install codecharta-visualization -g
For Code Mate there is no binary distribution, we need to compile it by ourselves:
cd ~/src/code-maat
lein uberjar
mkdir ~/bin
cp target/code-maat-1.1-SNAPSHOT-standalone.jar ~/bin/code-maat.jar
By installing the sonar-scanner CLI tool, we can import a Java project without changing it's configuration:
cd ~/bin
curl https://binaries.sonarsource.com/Distribution/sonar-scanner-cli/sonar-scanner-cli-3.3.0.1492-linux.zip \
> sonar-scanner-cli-3.3.0.1492-linux.zip
unzip sonar-scanner-cli-3.3.0.1492-linux.zip
PATH="$PATH:~/bin/sonar-scanner-3.3.0.1492-linux/bin"
Analysis
Now we can actually start the code analysis. The first step is to import the Java project into SonarCube:
cd ~/src/wicket
mvn install
sonar-scanner -Dsonar.projectKey=wicket \
-Dsonar.source=. -Dsonar.java.binaries=. \
-Dsonar.exclusions='**/*.js,**/*.xml'
curl http://localhost:9000/api/ce/task?id=AWrweUgHuDEJjgfjbZpz \
| jq '.task.status'
Next, we extract the data from SonarCube into a JSON file which is the basis of the final code visualization:
ccsh sonarimport http://localhost:9000 wicket > /tmp/sonar.json
The counting of the number of commits for each file will be done with Code Maat which takes the git log as input:
cd ~/src/wicket
git log --since="1 year" --all --numstat --date=short \
--pretty=format:'--%h--%ad--%aN' --no-renames \
> /tmp/gitlog.txt
java -jar ~/bin/code-maat.jar --log /tmp/gitlog.txt \
--version-control git2 --analysis revisions \
> /tmp/codemaat-revisions.txt
Then we can enrich the sonar.json file with the information extracted by Code Maat with a little helper script:
cd ~/src/code-analytics
python enrich_codecharta_data.py --sonar-json /tmp/sonar.json \
--codemaat-csv /tmp/codemaat-revisions.txt
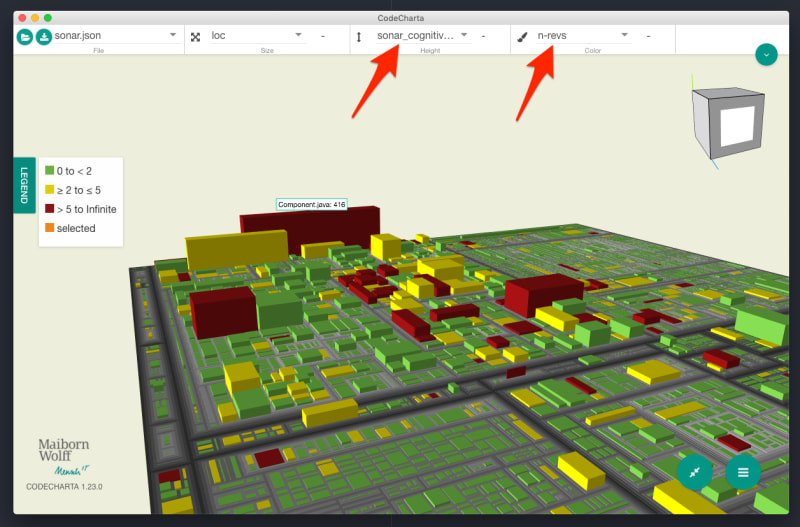
Finally, we can start the Code Charta visualization, load the sonar.json in its GUI and select the metrics we want to visualize.
codecharta-visualization
Result





Top comments (1)
Also see c2.com/doc/SignatureSurvey/