
El phishing es una técnica utilizada para suplantar sitios legítimos incitando a usuarios finales a introducir credenciales, tarjetas de pago u otros datos sensibles. A día de hoy sigue siendo una de las amenazas principales en materia de seguridad informática. Muchos usuarios no son expertos en su detección, y es comprensible dado que cada vez son más sofisticados.
Los mecanismos más comunes a través de los cuáles se propaga un phishing suelen ser los SMS (indicando cancelaciones de tarjetas de pago o extractos bancarios que requieren revisiones con urgencia, o un pago para desbloquear un paquete retenido en aduanas...) y el correo electrónico (cargos pendientes a Hacienda, etc.).
Contexto
Por lo general, los ciberdelincuentes utilizan técnicas como typosquatting para intentar engañar al ojo humano, al que le puede costar diferenciar https://google.com de https://gooogle.com. Algunos se aprovechan de subdominios muy largos para parecer reales, al estilo http://tramites.mi-area-de-gestion-privada.nombredebanco.<nombre-de-web>.com, si se da el caso de que los atacantes infectan un sitio existente y aprovechan para plantar ahí su página falsa. Otros pueden emplear acortadores de enlace, muy comunes en la propagación por SMS, y los más espabilados pueden intentar usar punycode [1] para que al mostrar el enlace en la barra de navegación no se diferencie a simple vista del original, aunque sean realmente distintos.
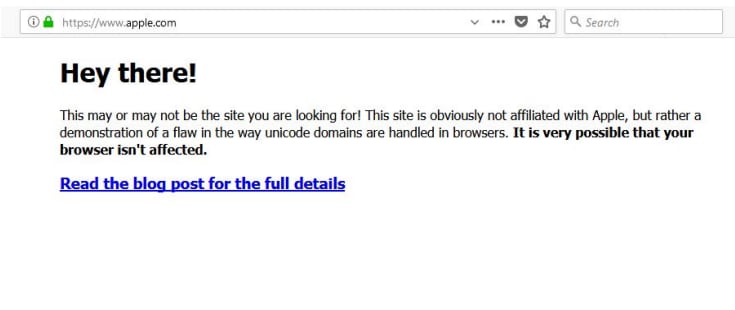
En el ejemplo de arriba, la página web que se está mostrando realmente es https://www.xn--80ak6aa92e.com/, pero en la barra de navegación parece https://apple.com/, incluyendo certificado SSL. Este dominio está registrado con caracteres cirílicos correspondientes al alfabeto ruso, y los navegadores los muestran de forma similar a los caracteres del alfabeto latín al que estamos acostumbrados.
Entender cómo funciona este tipo de ataques desde "el lado oscuro" puede ayudar a crear mecanismos para facilitar su detección. Con este propósito en mente, he dedicado varias semanas a desarrollar un proyecto relacionado con esto.
Presentando PELUSA
PELUSA, acrónimo para Predictive Engine for Legitimate & Unverified Site Assessment, es una aplicación que utiliza Machine Learning para clasificar un enlace como malicioso o legítimo.
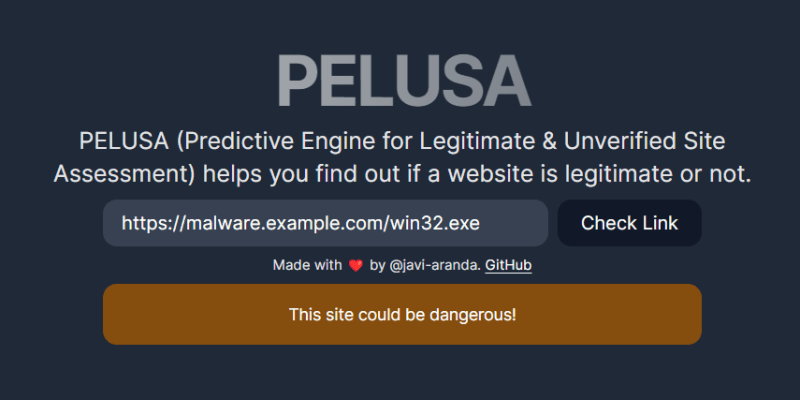
Para el entrenamiento del modelo, he utilizado un conjunto de datos de elaboración propia. Gracias a un fichero de sitios activos catalogados de PhishTank y a una serie de muestras seleccionadas de forma aleatoria de varias colecciones de Kaggle he obtenido 30.000 webs, la mitad clasificadas como maliciosas y la mitad seguras para navegar. Sobre dicho conjunto he aplicado un analizador estático, escrito en Python, para extraer características como pueda ser la longitud del dominio, si utiliza algún acortador de enlace, la presencia de palabras sospechosas en la URL, etc.
Tras obtener las características más relevantes y dividir el conjunto de datos en entrenamiento y test, probé con varios modelos, entre los que despuntaban Random Forest [2] y XGBoost con un 94% de precisión frente a un modelo de Regresión Logística con el que solo tenía un 84% de precisión. Finalmente decidí utilizar Random Forest porque su tiempo de entrenamiento era algo más corto y ofrecía resultados similares. Este clasificador, a diferencia de otros que dependen de un solo modelo para tomar decisiones, se basa en una estrategia de "sabiduría colectiva", combinando las predicciones de múltiples modelos individuales para producir una predicción general más sólida y precisa.
Una vez finalizado el entrenamiento del modelo, al pasarle las características extraídas de varios enlaces, tanto legítimos como maliciosos, devolvió unas predicciones correctas. Sin embargo, hay casos en los que cualquier URL que tenga un número largo de caracteres puede ser detectado como malicioso. Este tipo de comportamientos es normal dado el tamaño de entrenamiento y las características disponibles, y quiero mejorarlo en el futuro.
Próximos planes
En la parte de mi tiempo libre que dedico a trabajar en PELUSA, pienso en nuevas características que incorporar al analizador para elaborar un conjunto de datos aún más completo, y que ya detallaré en próximas iteraciones. Algunas de estas ideas incluyen:
- Fecha de creación y expiración del dominio.
- Validar si el dominio de una URL se encuentra indexado en motores de búsqueda.
- Qué registros DNS hay asociados al dominio.
- Si la web dispone de SSL, así como la confianza de la Entidad Certificadora (CA) que emita el certificado.
Cómo usar PELUSA
En este momento, PELUSA funciona únicamente de forma local. Mediante Docker se pueden desplegar fácilmente tanto un Frontend [3] escrito en React como el Backend [4], que utiliza FastAPI y PostgreSQL para almacenar las predicciones realizadas. De esta forma, el Backend queda desacoplado para que se pueda integrar con otras herramientas y así tener un apoyo extra en la detección de phishing.
Conclusiones
Las brechas de seguridad que múltiples compañías sufren día a día terminan exponiendo muchos datos que los ciberdelincuentes pueden aprovechar para dirigir ataques personalizados, por eso hay que tener especial cuidado cuando introducimos datos, ya sea a través del móvil, ordenador, tablet o cualquier dispositivo. Internet es un ente que crece por momentos. No hay consenso real en cuántos sitios nuevos aparecen cada día, ya que las estimaciones varían entre 200.000 [5] a 500.000. Las probabilidades de que ninguno termine siendo utilizado por ciberdelincuentes son remotas, por lo que disponer de herramientas que ayuden de forma automática a realizar esta labor puede aportar un grado extra de seguridad.
Referencias
[1] https://fraudwatch.com/what-is-punycode-phishing-part-1/
[2] https://es.wikipedia.org/wiki/Random_forest
[3] https://github.com/javi-aranda/pelusa-react
[4] https://github.com/javi-aranda/pelusa-server
[5] https://www.statsfind.com/how-many-websites-are-there-in-the-world-a-daily-calculator/

Top comments (2)
Thanks for sharing!
Your project is very cool, and the concept applies easily to other security flows
I think that by changing the database, other predictions would be interesting
I'll take a closer look at the project. Thanks for your contribution
Nice initiative. I'll be on the lookout for it