What is GraphQL?
GraphQL is not a library. It is a syntax that describes how to ask for data and it is generally used to load data from a server to a client. GraphQL has three main characteristics:
-It lets the client specify EXACTLY what data it needs.
-It makes it easier to aggregate data from multiple sources.
-It uses a type system to describe data.
GraphQL is like a middle layer between our data and our clients, and it can be considered as an alternative to REST API or maybe even an evolution.
We can find in this flexibility also an improvement phase of the API: in fact, the addition of fields returned to our structure will not impact the existing clients.
GraphQL is strongly typed: each query level matches a given type, and every type describes a set of available fields. Thanks to this feature, GraphQL can validate a query before running it, and in case of error, GraphQL can also return descriptive error messages.
What are the pros of GraphQL over rest?
With GraphQL, the client is able to make a single request to fetch the required information rather than constructing several REST requests to fetch the same.
This makes the app faster since you only have to wait for a single request to finish.
What are the cons of using GraphQL ?
-A lot of boilerplate and schema code at both frontend and backend.
-You need to learn how to set up GraphQL. The ecosystem is still rapidly evolving so you have to keep up.
-Nested queries in GraphQL can lead to circular queries and can crash the server. Extra care has to be taken.
-Rate limiting of calls becomes difficult because now the user can fire multiple queries in one call.
-Cache at Network Level: Because of the common way GraphQL is used over HTTP (a POST in a single endpoint), cache at network level becomes hard. A way to solve it is to use Persisted Queries.
When should I use GraphQL?
You have an app that needs to get lots of complex data from a backend.
Let's say data with multiple nested hierarchical levels. With a REST API you can achieve it, but it will take you several for loops, data synchronization, and API calls to the backend to get the result you need. This translates into long wait times for the calls to finish and overall diminished user experience. With GraphQL only one endpoint is needed in the backend for all the needs the frontend might have. And also you can get exactly all the data you need in only one call. No over-fetching and no under-fetching. This reduces drastically the latency time and bandwidth
What is the best GraphQL library I can use in .Net Core?
In .Net there are 2 libraries you can use to implement a GraphQL server:
-graphql-dotnet (please don't use this one. Please)
-hotchocolate
graphql-dotnet is old and it is not being actively maintained. Besides, it consumes more memory and it is slower than Hotchocolate.
Hotchocolate is way more flexible. It has a faster release cycle and it also has unique features like sorting and filtering thru the use of directives
although HotChocolate has good documentation I found several orthographic/grammatical errors. I sent several pull requests with corrections but the author didn't update the docs so far.
There are four key concepts in GraphQL:
- Schema
- Resolver
- Query
- Mutation
A GraphQL schema consists of object types that define the type of objects that are possible to receive and the type of fields available.
The resolvers are the collaborators that we can associate with the fields of our scheme which will take care of recovering data from these fields.
Considering a typical CRUD, we can define the concept of query and mutation.
The first one will deal with the information reading, while the creation, modification, and deletion are tasks managed by mutation.
How do I use HotChocolate in .Net Core?
First of all, we need to get the nugets required:
- HotChocolate.AspNetCore
- HotChocolate.AspNetCore.Playground
What is Playground?
If you ever used Swagger for rest APIs, then you will find Playground familiar. Playground is the swagger of rest APIs, It has 2 panels. It lets you write GraphQL queries on the left, click play, and then receive the result on the right, It also has code completion and automatic scheme documentation. It is an excellent tool to test your code and queries.
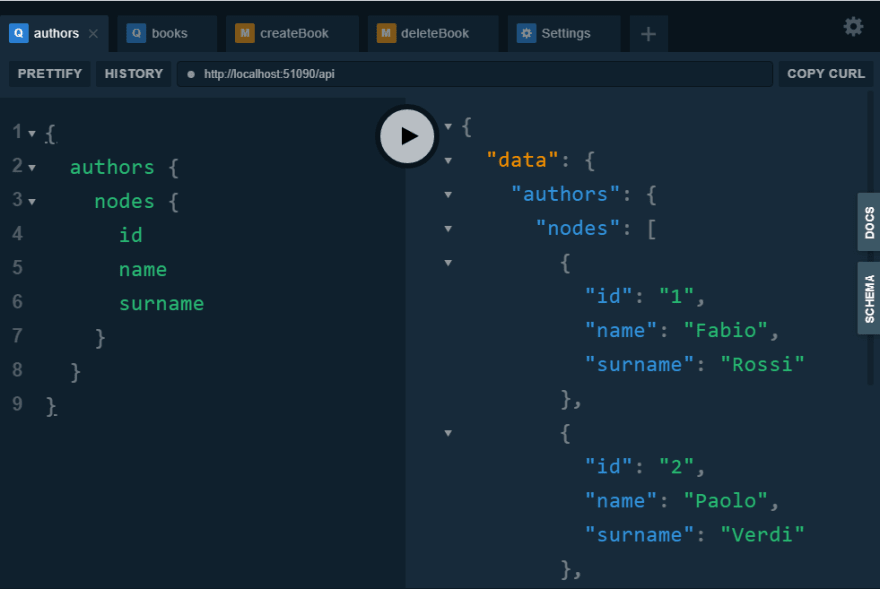
If you want to play with Playground you can take a look at it at https://localhost:[port]/playground/ when debugging your app.
remember to register it in the startup first.
HotChocolate has 2 approaches: code first and schema first. In order to make this article as short as possible we'll use code first.
We define the Author and Book, which will be the types exposed by our API.
public class Author
{
public int Id { get; set; }
public string Name { get; set; }
public string Surname { get; set; }
}
public class Book
{
public int Id { get; set; }
public string Title { get; set; }
public decimal Price { get; set; }
}
At this point, we can create the class Query, starting with defining the authors.
public class Query
{
private readonly IAuthorService _authorService;
public Query(IAuthorService authorService)
{
_authorService = authorService;
}
public IQueryable<Author> Authors => _authorService.GetAll();
}
After adding the nugets to our solution, we add the necessary statements to configure GraphQL in the Startup.cs file
namespace Demo
{
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddGraphQL(s => SchemaBuilder.New()
.AddServices(s)
.AddType<Author>()
.AddType<Book>()
.AddQueryType<Query>()
.Create());
}
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
if (env.IsDevelopment())
{
app.UsePlayground();
}
app.UseGraphQL();
}
}
}
With the annotation [UsePaging], we are instructing GraphQL so that the authors returned by the service will have to be made available with pagination.
This way, by starting the application and going to the playground, we can make the following query and see the result.
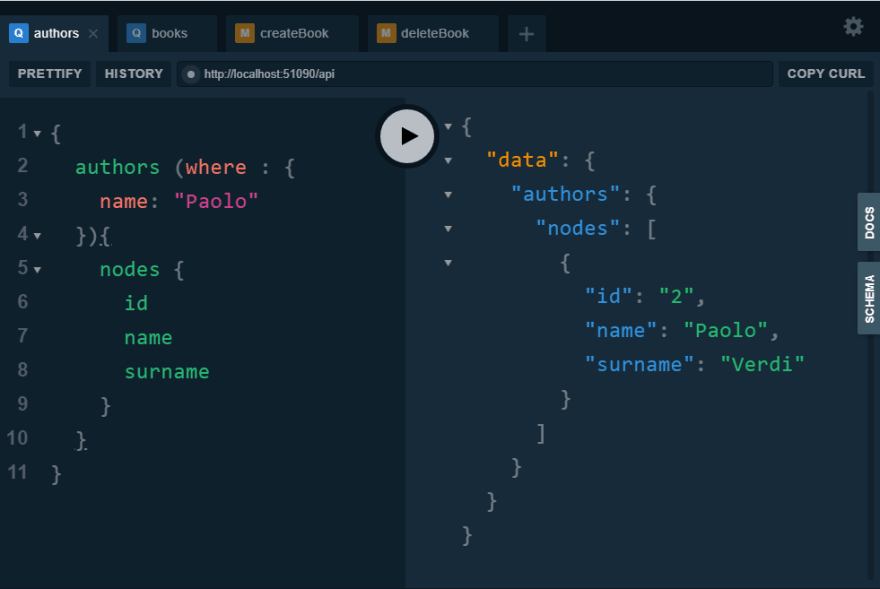
By adding the HotChocolate.Types and HotChocolate.Types.Filters nuget you can add a new annotation to enable filters.
[UsePaging]
[UseFiltering]
public IQueryable<Author> Authors => _authorService.GetAll();
Persisted Queries?
Persisted queries are a great way to improve the performance of your GraphQL server.
Persisted queries are validated once no matter if your server restarts or your cache is cleared.
Persisted queries are stored close to your server either in the file system or in a Redis cache. This helps to reduce request sizes since your application can send in a query key instead of the whole query.
Hot Chocolate supports out of the box two flows on how to handle persisted queries.
- Ahead of time query persistence
- Active Query Persistence
The first approach is to store queries ahead of time (ahead of deployment of your application). This can be done by extracting the queries from your client application, hashing them, and pushing them to the query storage.
Active query persistence builds upon the query persistence pipeline and adds the ability to store queries on the fly.
Conclusion
GraphQL and HotChocolate are a great alternative to REST APIs if you care about performance, latency, and bandwidth. It has some drawbacks like all the boilerplate required to make it work and also the learning curve required to build a production-ready API, but It is worth the time trying.
In my next post I'll be analyzing GRPC Apis, and comparing it to GrapqhQL and REST.
My Name is Javier Acrich,
I work as a software engineer at Mobomo.
I hope you liked this article!





Top comments (0)