
SirixDB - A versioned NoSQL data store for XML and JSON
Feel free to contribute on GitHub 💚
Hi all,
I just created my first ever Vue.js project to build a web front-end for SirixDB and to learn about single page apps, TypeScript, D3.js, Vue.js and the front-end world in general.
Please bear with me, I just made the post much more readable :-)
I first wanted to say a few things about what the purpose of SirixDB is and why we need another (versioned) database system.
SirixDB
SirixDB is all about efficient versioning of your data (currently XML and JSON stored in a binary format).
That is on the one hand it reduces the storage cost of storing a new revision during each transaction-commit while balancing read- and write-performance through a novel sliding snapshot algorithm and dynamic page compression. On the other hand SirixDB supports easy time travel query capabilities for instance to open a specific revision by a timestamp or several revisions by a given timespan, to navigate to future or past versions of nodes in the tree-structure and so on. It basically never overwrites data, batches writes and syncs them sequentially. It's heavily inspired by ZFS and Git. It borrows some ideas and puts these to test on the sub-file level.
In stark contrast to other approaches SirixDB combines copy-on-write semantics with database page-level versioning and does not require a write-ahead-log for consistency (a new UberPage is created last, when a new revision is committed to persistent storage).
The storage engine has been written from scratch and a resource in a SirixDB database basically consists of many hash-array based tries underneath an UberPage, which is the main entry point.
It all started around 2006 as a university / Ph.D. project of Marc Kramis. I already worked on the project since 2007 and did my Bachelor's Thesis, Master's Thesis, the Bachelor and Master projects as well as several HiWi-Jobs on topics regarding the project and I'm still more eager than ever to put forth the idea of a versioned, analytics plattform to perform analytical tasks based on current as well as the history of the data.
 sirixdb
/
sirix
sirixdb
/
sirix
SirixDB facilitates effective and efficient storing and querying of your temporal data. Every commit stores a space-efficient snapshot. It is log-structured and never overwrites data. SirixDB uses a novel page-level versioning approach called sliding snapshot.


![]()


Download ZIP | Join us on Slack | Community Forum
Working on your first Pull Request? You can learn how from this free series How to Contribute to an Open Source Project on GitHub and another tutorial: How YOU can contribute to OSS, a beginners guide
SirixDB - An Evolutionary, Temporal NoSQL Document Store
Store and query revisions of your data efficiently
"Remember that you're lucky, even if you don't think you are, because there's always something that you can be thankful for." - Esther Grace Earl (http://tswgo.org)
We currently support the storage and (time travel) querying of both XML - and JSON-data in our binary encoding which is tailored to support versioning. Our index-structures and the whole storage engine has been written from scratch to support versioning natively. In the future, we might also support the storage and querying of other data formats.
Note: Work on a …
The following time-travel query gives an initial impression of what's possible:
let $doc := jn:open('database','resource', xs:dateTime('2019-04-13T16:24:27Z'))
let $statuses := $doc=>statuses
let $foundStatus := for $status in bit:array-values($statuses)
let $dateTimeCreated := xs:dateTime($status=>created_at)
where $dateTimeCreated > xs:dateTime("2018-02-01T00:00:00")
and not(exists(jn:previous($status)))
order by $dateTimeCreated
return $status
return {"revision": sdb:revision($foundStatus), $foundStatus{text}}
The query opens a database and therein a resource in a specific revision based on a timestamp (2019–04–13T16:24:27Z). It then searches for all statuses, which have a created_at timestamp, that has to be greater than the first of February in 2018 and did not exist in the previous revision. => is a dereferencing operator to dereference keys in JSON objects. You can access array values as shown with the function bit:array-values or through specifying an index, starting with zero: array[[0]], for instance, specifies the first value of the array.

Design Goals 🔥
Some of the most important core principles and design goals are:
- Concurrent
- SirixDB contains very few locks and aims to be as suitable for multithreaded systems as possible
- Asynchronous
- operations can happen independently; each transaction is bound to a specific revision and only one read/write-transaction on a resource is permitted concurrently to N read-only-transactions
- Versioning/Revision history
- SirixDB stores a revision history of every resource in the database without imposing extra overhead
- Data integrity
- SirixDB, like ZFS, stores full checksums of the pages in the parent pages. That means that almost all data corruption can be detected upon reading in the future, we aim to partition and replicate databases in the future
- Copy-on-write semantics
- similarly to the file systems Btrfs and ZFS, SirixDB uses CoW semantics, meaning that SirixDB never overwrites data. Instead, database-page fragments are copied/written to a new location
- Per revision and per page versioning
- SirixDB does not only version on a per revision, but also on a per page-base. Thus, whenever we change a potentially small fraction of records in a data-page, it does not have to copy the whole page and write it to a new location on a disk or flash drive. Instead, we can specify one of several versioning strategies known from backup systems or a novel sliding snapshot algorithm during the creation of a database resource. The versioning-type we specify is used by SirixDB to version data-pages
- Guaranteed atomicity (without a WAL)
- the system will never enter an inconsistent state (unless there is hardware failure), meaning that unexpected power-off won't ever damage the system. This is accomplished without the overhead of a write-ahead-log (WAL)
- Log-structured and SSD friendly
- SirixDB batches writes and syncs everything sequentially to a flash drive during commits. It never overwrites committed data
Contributions
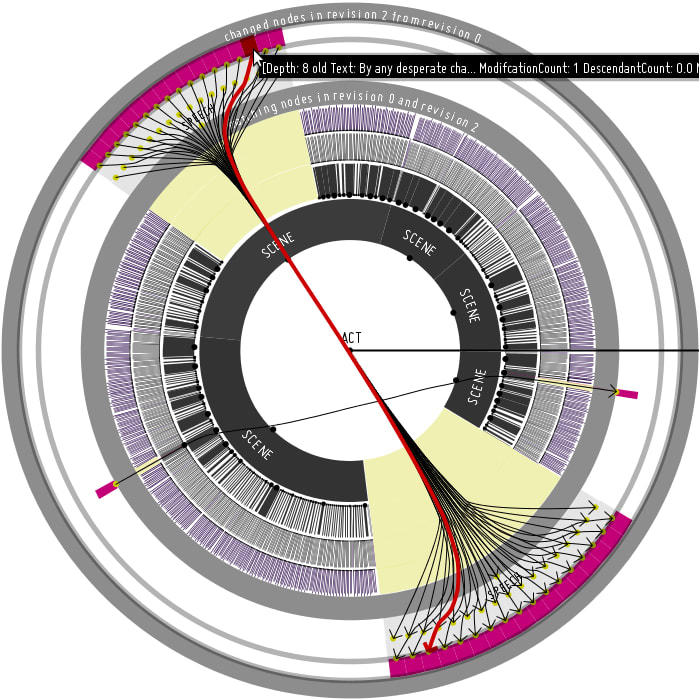
I have added #hacktoberfest labels to some open issues, but I guess the most interesting part now will be the web frontend. I envision certain interaction possibilities as for instance simply querying SirixDB and displaying the result, but also interactive visualizations to display what has changed between revisions of a resource stored in SirixDB (comparing XML and JSON basically). Maybe even a bunch of visualizations which are in synch with each other.
I've implemented some ideas in a Java Swing GUI and embedded visualizations built with processing (YouTube Screencast whereas you can find detailed explanations and screenshots in my Master's Thesis). As some of you told me, fof the web frontend I like to use d3js in combination with Vue.js, but I'm really new to the front-end stuff.
Let me know what you think :-) a community effort would be the most awesome thing ever. Would you be eager to help? Especially as I'm usually a backend engineer and might struggle a lot of times.
BTW: Another idea for the near future is scaling SirixDB with a distributed log, most probably via Apache BookKeeper directly or Apache Pulsar instead of Kafka.
Feel free to contribute on GitHub
Kind regards
Johannes





Top comments (10)
Love the project, I would love to contribute possibly later today (apparently your in germany so it will be tomorrow for you
I'll try to add support for retrieving the full revision history metadata of a resource on saturday (also for the REST-API... might simply be a GET host/database/resource/history route).
Maybe then in the first step for the web interface I'd like to read this information into a table, for instance, the author (name, ID), the revision number + revision timestamp and an optional commit message.
Then in the next step I might add the possibility to open a specific revision by clicking on one of the table rows :-)
I can definitely help with the REST api. and maybe the web UI.
Thanks a million times... I've built a non-blocking REST API with Vert.x, Kotlin (Coroutines) and Keycloak. It's in the repository in bundles/rest-api :-)
I just added persisting the user-information for each revision a few days ago (if the data store is not used as an embedded Java library). I'll add the possibility to get a list of this info in the Java-API next and then in the REST-API. Should be done in no time (hopefully ;-))
But I guess I need every kind of help for the upcoming web-UI where we start from a green field, yay ;-)
Oh, thank you so much... :-)
Hey, I'd be in for Vue. Any issues for frontend in particular?
Wow, yeah, I'm a backend engineer but would love to learn some frontend stuff. As of now we just have a plain simple table displaying the history metadata of a resource (and even only Metadata). Just started the project on saturday I guess.
I've added some issues to the github.com/sirixdb/sirix repository, but should have moved them to the new repository.
I think first we'd need a way to upload a directory of either XML or JSON files to SirixDB (thus that it can build a database and create resources therein -- importing and shredding the stuff into a binary tree-structure).
Then we'd probably need a tree to display the databases and underneath the resources stored underneath.
I think the contents of the resources (either JSON or XML documents) then need to be displayed in another table where you can also insert nodes and commit the data back to SirixDB.
However the most interesting parts will be the comparison of revisions of resources stored in SirixDB (for that we can use a tree-diffing algorithm which is already implemented).
So I envision two pretty printed resources, maybe loaded on demand side by side (as they in theory can be Gigabytes of data), as you scroll down. And then a way to display the differences from the diffs you get from the REST-API :-)
Hey Johannes!
This projects seems really interesting! Looking forward to contributing here :)
Oh, thank you so much :-)