In part one of this series, we looked at the object database. We learned that a commit it is a type of object, as are blobs, trees and tags. A commit references a tree and a tree references other trees and blobs.
We also learned that objects are referenced by a hash, but we have not learned a lot about these hashes. Let's find out how these hashes are determined, and why it matters.
Content based addressing
So how is this hash determined? Git uses a technique that is called content based addressing. The contents (the thing you see when you use git cat-file -p) of the object are the only factor that determines the hash. This goes for all types of object: blobs, trees, commits, and tags.
This matters for two reasons: repository size and performance. Think about how commits contain a reference to a tree and this tree contains the full directory structure for the repository at the moment of the commit. The commit is essentially a snapshot of the repository. If we have thousands of commits, that means we have thousands of snapshots of the repository. All this history should take up a lot of space, right?
Content based addressing helps a lot with this. Let's see what happens when we try to add a new file to the repository we created in part one:
$ echo 'exit' > script.sh
$ git add script.sh
$ git commit -m 'Add script'
[master 5b5f50a] Add script
1 file changed, 1 insertion(+)
create mode 100644 script.sh
We can use git cat-file to take a look at the contents of the tree1:
$ git cat-file -p 5b5f50a^{tree}
100644 blob a5c19667710254f835085b99726e523457150e03 README
100644 blob a3abe50906e1a7234d71453aaa367b0f8d7a9c2d script.sh
As expected we see the newly added file is also referenced by this tree. But take a look at the first entry and compare it with the tree of the previous commit:
$ git cat-file -p head~^{tree}
100644 blob a5c19667710254f835085b99726e523457150e03 README
It references exactly the same object. Since the contents of the README have not changed, its address has not changed. Trees have the same property. If none of the files in the tree have changed, the contents of the tree have not changed, and the tree will have the same hash. If objects have the same hash that references them, the object only has to be stored once.
We can visualize this to make it more clear. In this graph, the top commit is the latest and it references its parent. Both commits have their own tree, but both trees point to exactly the same blob for the README file. Even if the second commit renamed the README file, the tree would have been different, but it would still point to the same blob.

Another interesting example is what would happen if we moved the README into a docs folder instead.
$ mkdir docs
$ mv README docs/README
$ git commit -a -m 'Move README into docs'
[master c9ab7dd] Move README into docs
Date: Tue May 7 12:10:39 2019 +0200
1 file changed, 0 insertions(+), 0 deletions(-)
rename README => docs/README (100%)
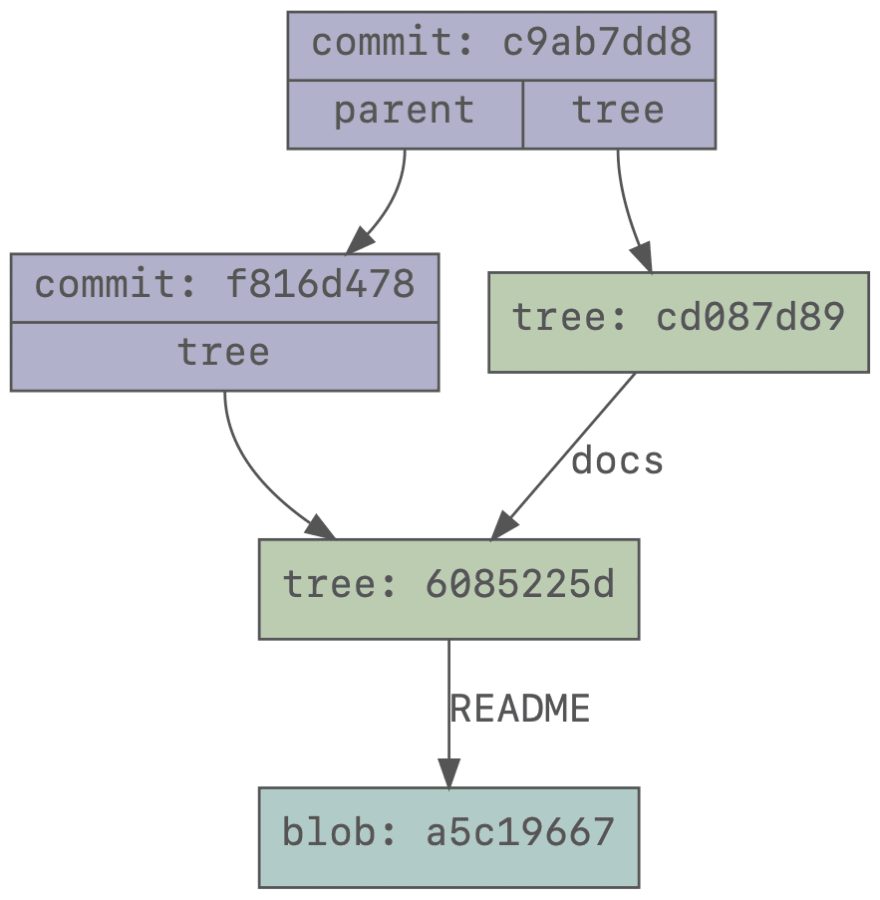
In this commit, the docs folder is exactly the same as the root folder was in the first commit. A new tree has been created for the root folder of the new commit, but the tree of the original commit has been re-used.
By using content based addressing, Git only has to store the files and trees that have changed. Those thousands of commits and thousands of snapshots take up a lot less space now. We only change a small part of the codebase in each commit.
The second advantage of content based addressing is performance when you are diffing two commits. Say we have a commit with the following tree:
040000 tree 356a192b7913b04c54574d18c28d46e6395428ab huge-directory
100644 blob da4b9237bacccdf19c0760cab7aec4a8359010b0 small-file
The huge-directory has a lot of subfolders and lots of files. Another commit has the following tree:
040000 tree 356a192b7913b04c54574d18c28d46e6395428ab huge-directory
100644 blob 77de68daecd823babbb58edb1c8e14d7106e83bb small-file
If we diff those two commits, looking at every file that is stored in huge-directory would take a lot of time. Luckily, we don't have to. If you look at the SHA's for the huge-directory in both trees, they are the same. This must mean that they contain the same contents. Thus, the only thing we need to diff is small-file.
Branching without branches
One concept that seems to be essential to Git is branches. Branching is very important to any version control system and you cannot do this without branches, right? Turns out, you can. Using just commits it is perfectly possible to do branching, it's just not very convenient.
Let us take another look at our example repository. We now have two commits: the initial commit and the commit that adds script.sh. We will create two commits, but we will reset back to the second commit in between.
$ echo 'Hello, world!' > README
$ git commit -a -m 'Shout in README'
[master 3bf75bf] Shout in README
1 file changed, 1 insertion(+), 1 deletion(-)
$ git reset --hard head~
HEAD is now at 5b5f50a Add script
$ echo 'Hello, world?' > README
$ git commit -a -m 'Question in README'
[master 00e9f1c] Question in README
1 file changed, 1 insertion(+), 1 deletion(-)
And we will merge two commits directly, fixing the merge conflict that we just created:
$ git merge 3bf75bf
Auto-merging README
CONFLICT (content): Merge conflict in README
Automatic merge failed; fix conflicts and then commit the result
$ echo 'Hello, world!?' > README
$ git commit -a --no-edit
[master ec9c76d] Merge commit '3bf75bf'
So now we have created three new commits, two simple changes and one merge commit. The merge commit also has a tree that contains the state of the repository after the merge, including the resolution of the merge conflicts.
This is what it looks like visually. The trees and blobs are no longer shown to make the graph simpler.
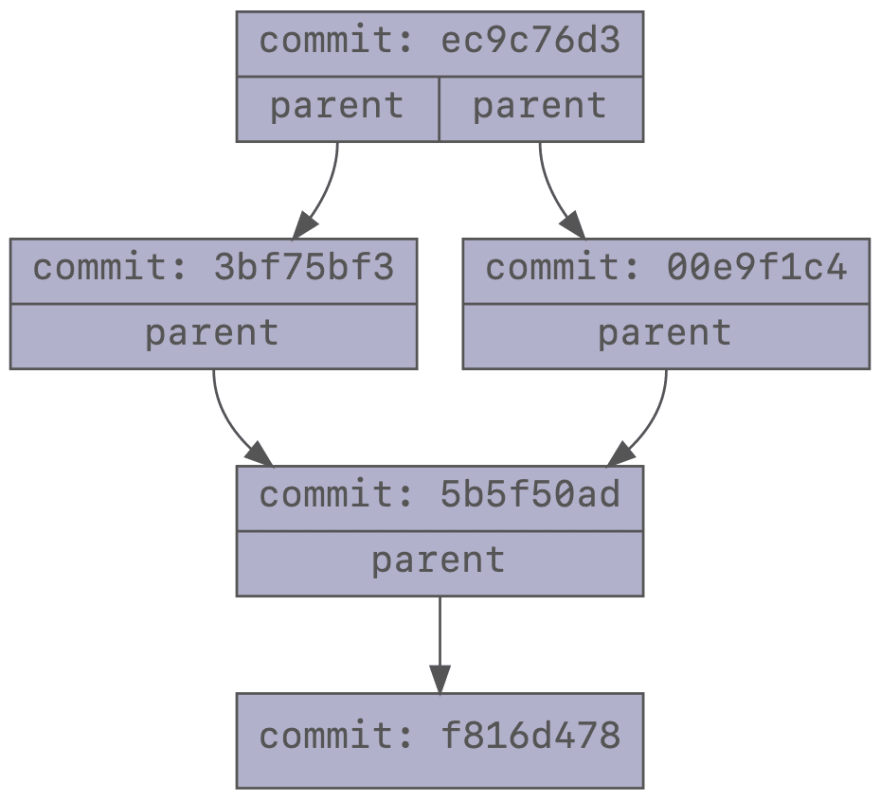
Again, the top commit is the latest. There are now two commits with 5b5f50ad as parent. This is where the branching has happened, there are now two distinct histories from this point on. The latest commit, ec9c76d3 merges these two branches, so that now the changes made in 00e9f1c4 and 3bf75bf3 are both applied.
And this is essentially what branching is. Notice how there are absolutely no branches in this picture. In fact, to get to this point, we did not create a new branch. The only branch we have is master.
What do branches and tags add?
If we can do branching without having branches, what do these branches add? So far, we have referenced every commit by its SHA. While this works, it is not very convenient even for such a small repository. Once we have hundreds or even thousands of commits, it will become impossible to keep track of all commits.
This is what we can use both branches and tags for: to have an easy reference to commits. Internally, they are nothing more than a reference to a commit. Let us take a look at what the master branch looks like. Remember that .git directory we discussed in the first part? Branches are also stored in there. We can find all branches in .git/refs/heads, so far it only contains a master file. This is what the contents of that file are:
$ cat .git/refs/heads/master
ec9c76d3b3eaea9b3ac57e1ac74ddd5189267341
That is the SHA of the latest commit. So every branch just references its latest commit, also known as its head. If you are currently on a branch2 and you create a new commit, the branch file in .git/refs/heads will also be updated to point to the new commit.
We will create a new branch and create a commit on that branch. This is the result of that:
$ git checkout -b my-awesome-branch
Switched to a new branch 'my-awesome-branch'
$ echo 'Awesome Hello World!?' > README
$ git commit -a -m 'Awesome commit'
[my-awesome-branch 3cf54d4] Awesome commit
1 file changed, 1 insertion(+), 1 deletion(-)
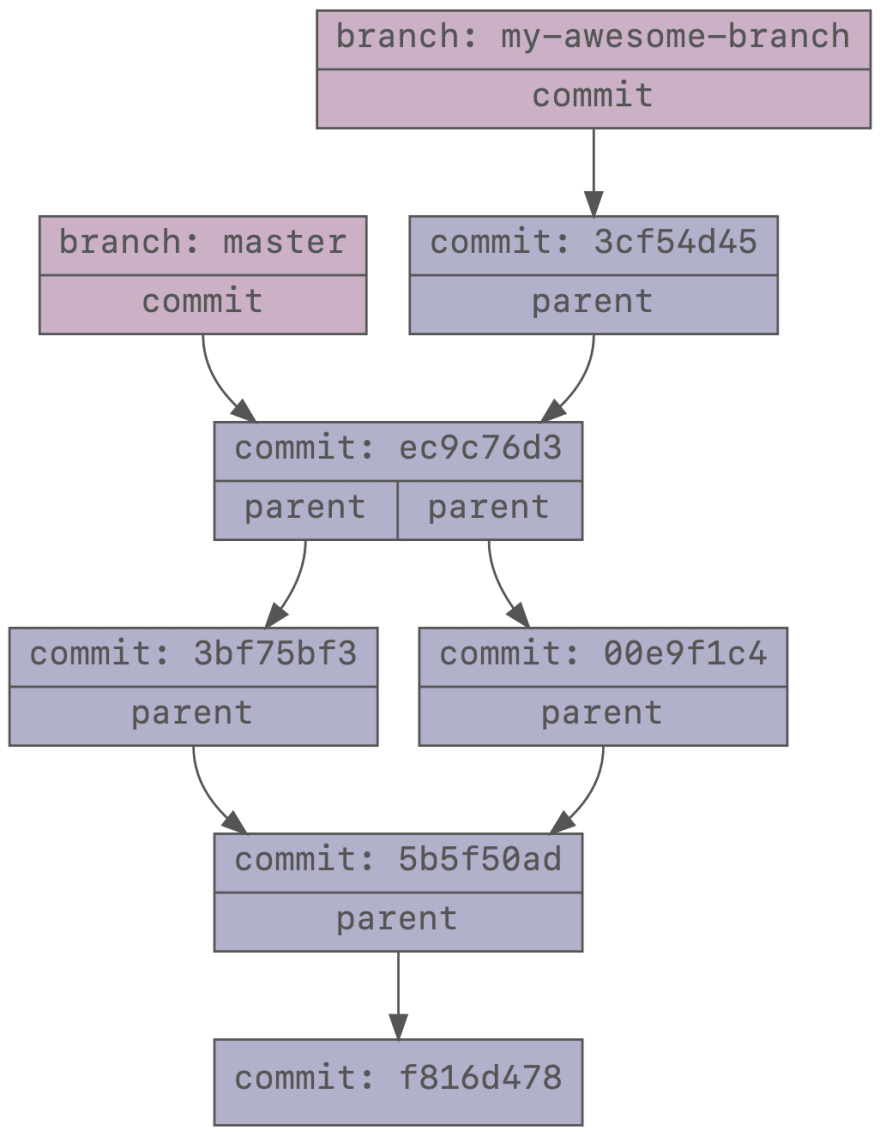
Tags are very similar to branches. The only difference is that when you check out a branch, git will remember that and move the branch along when you create new commits, while checking out a tag simply means you check out the commit that tag references. A tag will never change unless you explicitly tell Git to do so.
Git distinguishes between two types of tags: annotated tags and lightweight tags.
Lightweight tags are just a reference to a commit, exactly like a branch. They are stored in the .git/refs/tags directory, and just like branches the file name is the name of the tag and the file contains a SHA of a commit 3.
An annotated tag is an actual object that Git creates and that carries some information. For instance it has a message, tagger, and a tag date. Since these objects can not be easily found, for instance when you run git tag, a lightweight tag pointing to your annotated tag is also created.
This was how both forms of tagging look:
$ git tag my-lightweight-tag
$ cat .git/refs/tags/my-lightweight-tag
ec9c76d3b3eaea9b3ac57e1ac74ddd5189267341
$ git tag -a my-annotated-tag -m 'This tag has a message'
$ cat .git/refs/tags/my-annotated-tag
370cba29377db4129a9445c3c309ed596666e20a
$ git cat-file -p 370cba29
object ec9c76d3b3eaea9b3ac57e1ac74ddd5189267341
type commit
tag my-annotated-tag
tagger John Doe <john.doe@example.com> 1557144396 +0200
This tag has a message
This is what our graph looks like when both tags are created:

Conclusion
Now we know how the basics of Git work. In first part we learned how Git stores its most basic data: commits, blobs, and trees. In this part we learned how contents based addressing helps Git be very efficient in storing this data. We also learned how the basic objects can be used to do branching and what branches and tags are.
In the last part of the series, we will see some practical uses of this new knowledge.
-
We are using a syntax to get straight to the tree of a commit. Check out the man pages for git-rev-parse if you want to learn more about how you can specify revisions. ↩
-
We won't go into the details of this, but the "branch you are on" is stored in
.git/HEAD. Normally, it stores the name of a branch, likeref: refs/heads/master. If you are in headless mode, it contains the SHA of a commit. ↩ -
Despite the fact that almost every tag points to a commit (or an annotated tag that points to a commit), this is not strictly necessary. A tag can also point to blobs and trees, so you might use tags to keep a reference to blob containing whatever data you like. ↩


Top comments (0)