
I am taking a short break from the Blockchain Programming series and writing this post because I found it pretty interesting.
The other day I found a tweet( which unfortunately I forgot to bookmark and can’t find it anymore) about visualizing python modules in Neo4J. Guido, the Python creator had responded to that tweet. That tweet got stuck in my mind and I thought it a great excuse to explore Neo4j. I had been thinking of exploring some Graph Databases other than Neo4j. For some weird reason, I had been ignoring Neo4j for a long time, most probably because of the Java thing which I do not like at all. I tried Arangodb but it’s GUI but somehow its GUI is not smooth enough. Anyways, before I move further, this is how it looks like:
You can say that this demo is a stripped version of pip show command.
Before I move to the actual work, let’s discuss in brief Neo4j and Graph Databases.
What is Graph Database
According to Wikipedia:
..a graph database (GDB) is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data.[1] A key concept of the system is the graph (or edge or relationship). The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes.
Neo4j defines it as:
Very simply, a graph database is a database designed to treat the relationships between data as equally important to the data itself. It is intended to hold data without constricting it to a pre-defined model. Instead, the data is stored like we first draw it out — showing how each individual entity connects with or is related to others.
Basically, a graph database is all about telling about data and its relationship. Graph Databases are based on Graph Algorithms which themselves are based on Graph Theory.

Why Graph Databases
There could be several reasons but some of them are:
- Connectedness:- In RDBMS, you usually store data in tables. Often times you do not need a relationship and data is stored as a single entity. For instance list of countries etc. If your project does not require too much relationship then Graph Database is useless. In my case, the same thing could be done in RDBMS too but it goes more efficient too in Graph Database since all the required info is available at the node level and all is just needed to fetch relationships between nodes.
- Change Frequency:- In the RDBMS world, if you want to add a new piece of info, you would have to alter the table for adding a column. This is not the case in graph databases since information is added in the form of attributes.
You can read further about it over the web. Let’s move forward and set up our development environment. I am using the docker version.
Development Setup
Start Docker and execute the command docker pull neo4j to pull the Neo4j docker image.
In order to run it, execute the following command:
docker run --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data neo4j
and you will see something like the below:

And when you visit d it shows something like the below:
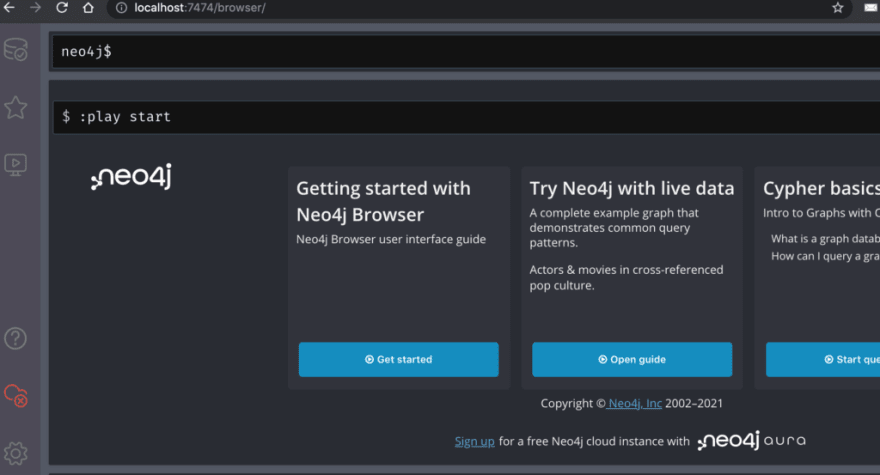
Neo4j uses Cypher Query Languag e for different operations. Let’s discuss a few Cypher queries
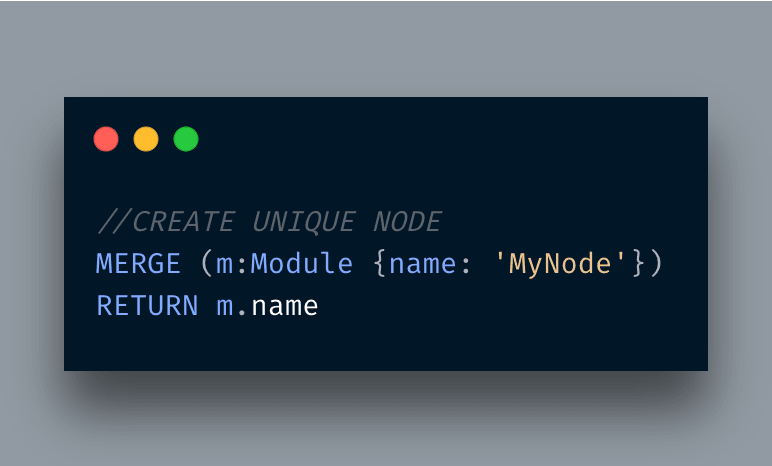
Creating a node
In order to create a node of a certain type you will be executing the following command:

Here a node was created of type Module with the attribute name in it. I used this initially but I wanted to make sure that all nodes are unique and do not create if exists so I used this query then
Creating Relationship between nodes
Creating a relationship between nodes is not difficult either.

The query matches a couple of nodes based on name attribute, if found, it creates a directional relationship with the label USED_BY. -> is used to tell that the relationship begins from a to b.
Neo4j Python integration
OK, we know what are the queries that are needed to create both node and relationship. Our purpose is to communicate with neo4j from Python. For that purpose, I am using the neo4j Python driver.
First, we need a list of all installed modules on my machine
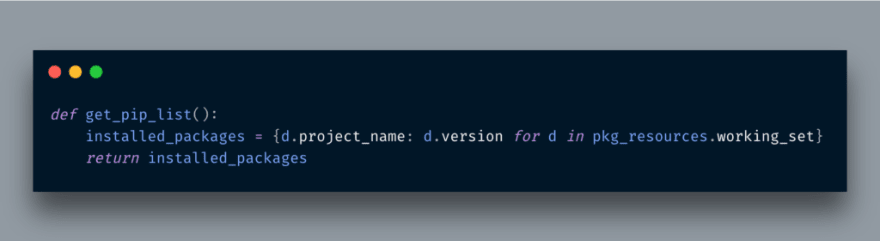
I imported pkg_resources to get all installed modules. Next, I need to grab an individual installed module information. For that purpose, I will be using pip show command.

The __main__ function now looks like below:
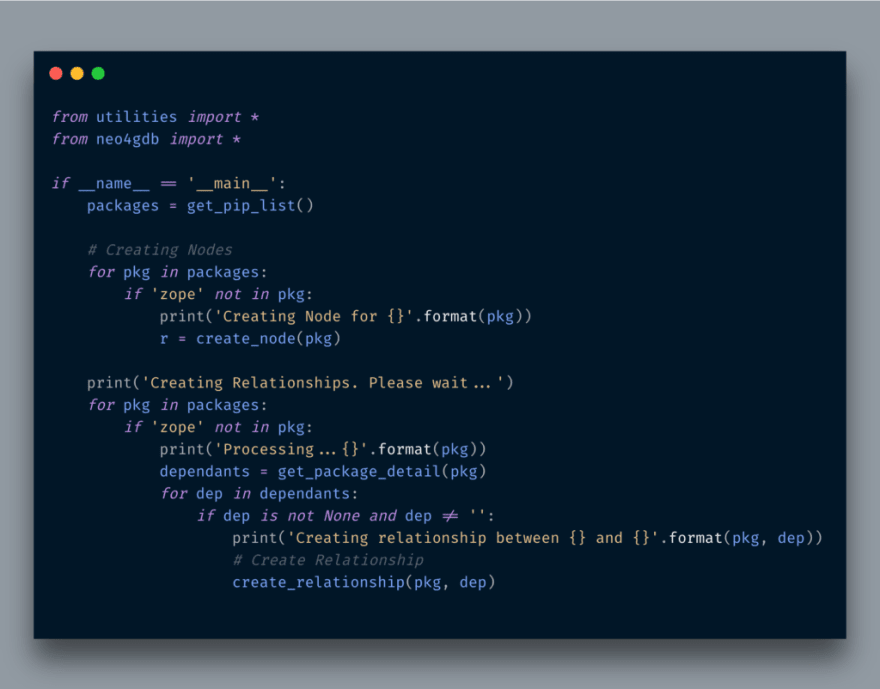
Now it’s time to visualize nodes.
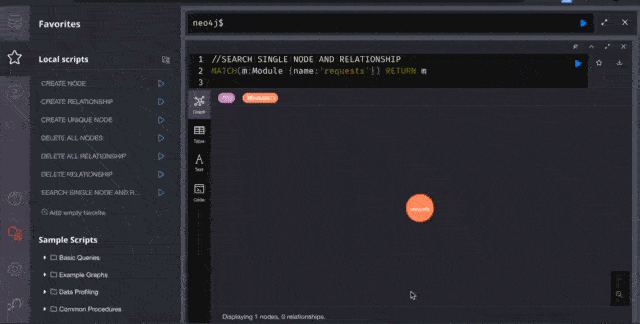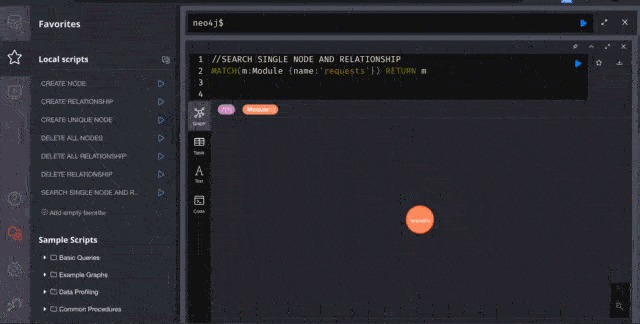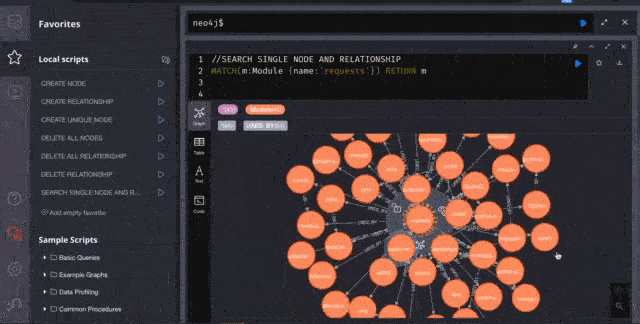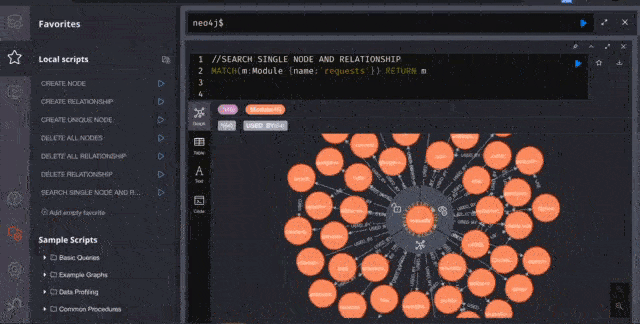
Here I am visualizing the famous requests library for HTTP. It looks beautiful, No?
Conclusion
In this post, you learned how easy it is to ingest data in the neo4j graph database and visualize the relationship between entities. I have covered just the gist of neo4j. You should explore it further for the optimized search queries and using the returned result in your apps. Like always, the code is available on Github.
Originally published at http://blog.adnansiddiqi.me on August 18, 2021.





Top comments (0)