
There’s a simple trick for determining if a book is the appropriate reading level for a child called the “five finger rule.” It works like this: have them open a book and choose a page at random.
-If there are between one and five words on that page that they aren’t familiar with, then that book is at the right reading level.
-If they know all the words, the book probably won’t help them grow as a reader. Anything more than six words is probably too advanced.
I have no idea how this rule originated. A cursory Google search indicated the rule is very popular among teachers and education researchers alike, however, not many agree on how many words made a book too difficult or too easy. Moreover, the five finger rule may not make a difference at all when it comes to vocabulary acquisition.
But I think I get why the five finger rule is so wide-spread. It’s easy to remember, doesn’t require any special training, and usually takes less than a minute.
It’s the rule I purported to parents every year at the end of my Open House presentation. The trouble is, I’m not sure if it made much of a difference. In my experience, Lexile levels--the popular framework for measuring reading growth--fluctuated at the start of the school year before improving dramatically over the third and fourth quarters.
But education is a strange chimera: scientific best practices are often at odds with hard human truths.
Tiered Vocabulary
As an educator, I was always looking for ways to make my work more efficient. For quizzes, I cut holes in my answer sheet so I could quickly match up multiple choice questions with the correct answers. I tracked field trip participation with Google Sheets calculations and let the computer handle bus count logistics. There were a few areas that I was sure to devote more time to and one of those was reading instruction.
Unlike the five finger rule, there’s more training involved in identifying tiered vocabulary. Basically, words of a text are broken up into three categories: common words, general academic words, and domain-specific words.
Take, for example, this excerpt from a report by the Common Core State Standards for English Language Arts & Literacy.

Although most parents and children would have a pretty easy time identifying the everyday words used in this text, the line becomes blurred when differentiating between tier 2 and 3 words. On top of that, tier 3 words are specific to that subject (words like lava, beaker, mitochondria for Science, plot, mood, and juxtaposition for English).
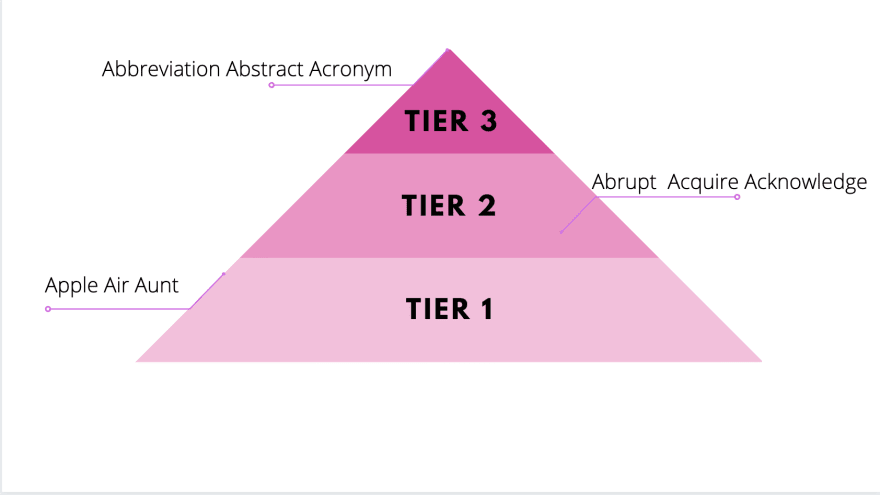
Yet, perhaps the most important takeaway is the key word among those keywords. The researchers identify that the word determined is essential for understanding the rest of the text. But it could easily be mistaken as an everyday word.
According to the researchers, common words are “not considered a challenge to the average native speaker, though English language learners of any age will have to attend carefully to them.”
Determined would fit in that category, yet here it is the nuance of the word takes precedence. This is what catapults determined to a Tier 2 word. The word determined can appear throughout informational, technical, and creative texts and encapsulate its own meaning in all of these different forms.
Whenever I considered using a new text in my class, I’d sit down and circle the tier 2 and 3 words. The process was almost clairvoyant: my years of experience gave me insight into the types of words my middle school students would likely understand and the types they wouldn’t.
I’d ask students repeat the same process I used (albeit, without the tiers involved) and be pleasantly surprised each time they identified the same word I had ahead of time.
I enjoyed the process of combing through texts and selecting the best candidates for vocabulary learning. It put me in the shoes of my students and allowed me to empathize with their journey as readers. But again, I wondered, could even this process be expedited by technology?
Natural Language Processing
Natural Language Processing (NLP) is a computer’s attempt to make sense of human language. If you’ve ever had a computer compose a line of text for you, or asked Alexa to set a timer for you, you’ve used NLP.
NLP was already used in my classroom in a variety of instances, including the fact that it scored writing for standardized testing.
But my question was how can NLP help teachers at an everyday level and could those programs actually supplant reading teachers in the long run?
RAKE (Rapid Automatic Keyword Extraction) is a keyword extraction package in Python.
- It splits up a document into a list of separate words called an array and cleanses the list of punctuation.
- Using a list of stop words (think common words like the, they, and), it extracts a number of phrases and keywords that are between these stop words.
- Those words and phrases then become candidates and are ranked by degree and frequency.
We go from here: 'The quick brown fox jumps over the lazy dog.'
To here: ['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']
To here: ['quick', 'brown', 'fox', 'jumps'], ['lazy', 'dog']
To here: ('quick brown fox jumps', 16.0), ('lazy dog', 4.0)
There are other NLPs besides RAKE, but RAKE was the most accessible and appropriate for a small passage of text.
RAKE vs Tiered Vocabulary
I was curious to find out how RAKE compared to the tiered vocabulary method. Could RAKE identify the same words as a team of educational researchers had, and would it rank those words highly?
After setting up the program by following Alyona Medelyan’s keyword extraction tutorial, I ran RAKE from my terminal using the following commands:
import rake
import operator
rake_object = rake.Rake("SmartStoplist.txt", 5, 3, 4)
sample_file = open("data/docs/fao_test/bus.txt", 'r')
text = sample_file.read()
keywords = rake_object.run(text)
print("Keywords:", keywords)
To make the comparison easier, I exported the results onto a spreadsheet.
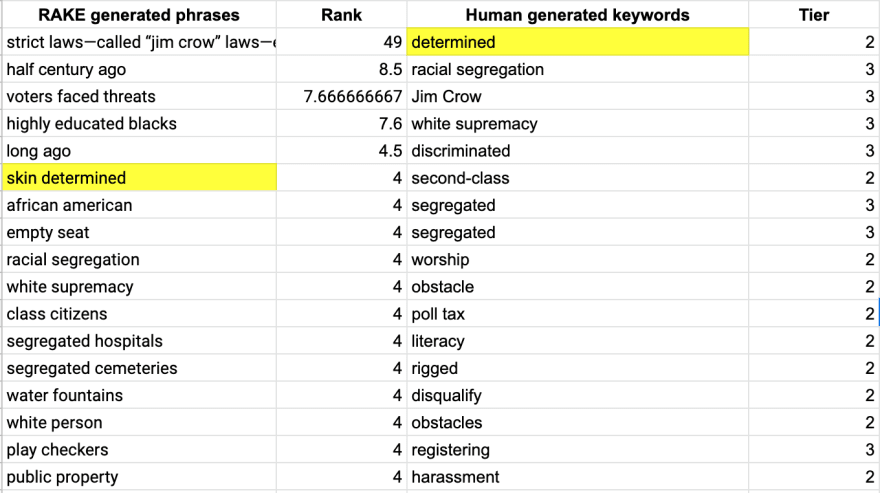
As you can see, the key word determined is now skin determined and is not nearly as highly ranked as strict laws—called “jim crow” laws—enforced. Yet, all human identified keywords are present on the RAKE generated list in some form or another.
There are, of course, many other words generated by the computer. Words like water fountains and play checkers seem to have the same weight as racial segregation and white supremacy.
This may be an unfair comparison, however.
RAKE and the tiered vocabulary method are incredibly different. The tiered vocabulary method is context driven and not meant to be completely exhaustive. Moreover, it’s used for vocabulary instruction. RAKE is not context-based and attempts to grasp the controlling idea of the passage.
Still, I can think of a few uses for RAKE and tired vocabulary in tandem. Given texts of a certain length and at a certain level, RAKE is a solid tool for generating a word list for prediction exercises.
Most students would be able to grasp the main idea of the passage by looking over the RAKE list. It’s good as a jumping off point, an introduction, and a wordbank for summarizing. Tiered vocabulary is the deep dive, the cross-curricular discussions, the words that spark a thesis.
Conclusion
I tried RAKE out with a few other passages I taught in the past. None of results seemed to be as meaningful as the “It Happened in Montgomery” passage. But I could see a teacher, starved for time, using RAKE (or something similar) to extract a keyword list to generate main idea talking points. RAKE also performed better than a couple of free vocabulary generating applications I found online.
When I sat down to write this, I imagined a science fiction-like scenario of feeding a text to a machine and getting back a customized list of keywords for each student at their level. But it’s difficult to imagine RAKE, or other technologies, performing this task right now.
If you’re a reading teacher, a parent, or a student yourself, I say use RAKE. At the very worst, it’ll spit out some word soup that you can use for main idea generation. And it’s easy to use, requires only a bit of special training and usually takes less than a minute!





Top comments (2)
It comes down to what you're trying to teach.
If you're trying to introduce new vocabulary by ensuring that it can be inferred from context, minimizing the number of new words is a reasonable strategy.
If you're trying to produce a more generalized grapholexical model, then you want the amount of new vocabulary to be too large to memorize one by one.
As always, you cannot judge the effectiveness of a method without an understanding of the goal.
So I would start by leading with the goal, and from there everything else should follow.
Great advice. Sounds like this is something that could be explore in depth further.