
C++ Tricks is a series of posts on core libraries for game engines and language experiments shared as the Kahncode Core Libraries.
As introduced in the first post of these series, I will share the first piece of KCL: an implementation of RTTI and Dynamic Cast. The code can be found on GitHub.
If you don't know what dynamic casting is, then I suggest you read some online resources before diving into this article.
I will avoid debating whether or not you need RTTI. Some say that it correlates with bad architectural choices and violates the SOLID principles. However in practice most game engines have an extensive RTTI and introspection system and make wild use of it. Unreal Engine solves this issue using code generation in their object system.
Following the philosophy of KCL, our RTTI system will fulfill the following requirements:
- Must support at least: dynamic cast, multiple inheritance, and retrieving the type name as a string.
- As elegant syntax as possible. Only two macros are necessary. A one macro version is possible as well.
- No code generation, use only the preprocessor and compiler.
- Minimalist: there are less than 350 lines of code including all comments.
- Efficient: one of the main complaints about STL RTTI and dynamic_cast is that is it slow. We must outperform the STL at least in runtime performance.
- Avoid polluting the global namespace except for our version of dynamic_cast and the necessary macros.
The Solution
Before diving into the code, let's explain how we are going to solve this problem.
To better understand the following part, I will clarify some terminology. We will build the following:
- TypeID: a unique identifier for a single type.
- TypeData: the necessary information to perform a dynamic cast
- TypeInfo: a structure which contains the TypeID, the type name and the TypeData
Plan of action:
- We must add at least one virtual method to a polymorphic type, in order to retrieve the type information at runtime. This is unavoidable.
- The type info itself should contain enough information to identify the type, its name, and all the necessary information to perform dynamic cast. The entirety of the information must be contiguous in memory for best performance, we will therefore avoid linked lists and pointers of any kind.
- The cost of a dynamic_cast will therefore be that of calling a virtual method, loading the type info, and iterating over a contiguous region of memory.
TypeInfo breakdown
First let's create the TypeId by assigning one unique integer identifier for each type. For most programs 16 bits should be enough, so the typedef allows you to adjust the memory footprint of the RTTI system.
static typeId_t GenerateId()
{
static typeId_t theTypeIdCounter = 0;
return ++theTypeIdCounter;
}
We could build the TypeInfo as a simple array of all the Type IDs of the type and its base types. However there is one more information necessary to perform dynamic casts.
In a multiple inheritance scenario, the dynamic cast of a pointer may actually change the value of the pointer due to pointer adjustment. In order to understand this mechanic, let's take an example:
class A
{
int i;
};
class B
{
int j;
};
class C : A, B
{
int k;
};
C* pC = new C;
A* pA = (A*)pC; // No offset adjustment, pA == pB
B* pB = (B*)pC; // Offset adjustment, pB != pA
The pointer difference can be explained when examining the memory layouts of these objects. In order to return a valid pointer to an instance of B, the compiler must return the adress of B in the memory layout of C.

The compiler may also introduce padding between the types, so the offset of B* is not necessarily A* + sizeof(A).
We will use the compiler itself to determine the offset accurately:
template<typename Derived, typename Base>
static ptrdiff_t ComputePointerOffset()
{
Derived* derivedPtr = (Derived*)1;
Base* basePtr = static_cast<Base*>(derivedPtr);
return (intptr_t)basePtr - (intptr_t)derivedPtr;
}
Here is the final TypeInfo info design we come up with, containing all the necessary information. The data array is later implemented as TypeData<T>.

The data starts as a TypeID string with a size and an array of TypeIDs. The first type is the current type's TypeID. In the cases of multiple inheritance, it follows with more TypeID strings as well as their pointer offset adjustment information.
We can observe that the first list does not have an offset. This is because all first bases can be casted without pointer offset adjustment. We can therefore perform a slight optimization by omitting this offset value.
As none of the following lists should have 0 as pointer adjustment value, this allows us to treat a null offset value as the end marker to the chain.
The recursive nature of the TypeInfo will allow algorithms to walk through the data structure and extract the necessary information during dynamic cast.
Building the type info
The TypeInfo struct must not be templated, and contains all the necessary API to access the RTTI. A pointer to the static instance of this TypeInfo will be returned by the virtual function on the object.
struct TypeInfo
{
const char* myName;
const char* GetName() const
const char* GetTypeData() const
typeId_t GetTypeId() const
intptr_t CastTo(intptr_t aPtr, typeId_t aTypeId) const
{
const char* data = GetTypeData();
size_t byteIndex = 0;
ptrdiff_t offset = 0;
while (true)
{
typeId_t size = *(typeId_t*)(data + byteIndex);
byteIndex += sizeof(typeId_t);
for (typeId_t i = 0; i < size; i++, byteIndex += sizeof(typeId_t))
{
if (*(typeId_t*)(data + byteIndex) == aTypeId)
return aPtr + offset;
}
offset = *(ptrdiff_t*)(data + byteIndex);
if (offset == 0)
return 0;
byteIndex += sizeof(ptrdiff_t);
}
}
};
The TypeInfo contains the name, and assumes that is it followed in memory by the Type Data as described above. The type data starts with the current type's TypeID, which is returned by GetTypeId. The CastTo method iterates through the type data and tries to find the TypeID we are trying to dynamic cast to. If it is found, it performs the offset adjusment and returns the new pointer value.
The most complex part is still ahead of us: we must use the compiler to compute this Type Data. Variadic templates will allow us to fill the Type Data recursively:
template<typename T>
TypeData<T> : public TypeDataImpl<T, BaseTypes...>
Simple Type
Let's start with the most simple type, which does not inherit from anything:
template<typename Type>
struct TypeDataImpl<Type>
{
TypeDataImpl() : mySize(1), myTypeId(GenerateId()), myEndMarker(0)
const char* GetData() const
typeId_t mySize;
typeId_t myTypeId;
ptrdiff_t myEndMarker;
};
We simply generate a new TypeID for this type and set the size to 1 and the end marker.
Single Inheritance
Let's examine now the case of a type with single inheritance:
template<typename Type, typename Base>
struct TypeDataImpl
{
TypeDataImpl()
{
myTypeId = GenerateId();
myBaseTypes.FillBaseTypeData<Type>(0 /* No offset with first base */, mySize);
mySize++; // Size is the base's size + 1 to account for current type id
myEndMarker = 0;
}
const char* GetData() const
typeId_t mySize;
typeId_t myTypeId;
BaseTypeData<Base> myBaseTypeData;
ptrdiff_t myEndMarker;
};
Again we build the type data starting with a size and a fresh TypeID. However we will follow it by the type data of the base type. Therefore the size of the first TypeID list in the array is one more than the base type as we include the new type's Type ID.
In order to generate BaseTypeData we retrive the TypeDataImpl of the base type and iterate through it. Don't worry, this is the most complex part of the whole thing.
template<typename Base>
struct BaseTypeData<Base>
{
void FillBaseTypeData(ptrdiff_t aOffset, typeId_t& outHeadSize)
{
// Retrieves the TypeData<Base> instance, explained below in the article
const TypeData<Base>* baseTypeId = (TypeData<Base>*)(GetTypeInfo<Base>::Get()->GetTypeData());
// return size of head list
outHeadSize = baseTypeId->mySize;
const char* data = baseTypeId->GetData();
size_t byteSize = baseTypeId->mySize * sizeof(typeId_t);
// copy type list
memcpy(myData, data, byteSize);
size_t byteIndex = byteSize;
ptrdiff_t offset = *(ptrdiff_t*)(data + byteIndex);
while (offset != 0)
{
// fill next offset and add pointer offset
*(ptrdiff_t*)(myData + byteIndex) = offset + aOffset;
byteIndex += sizeof(ptrdiff_t);
// fill next size
const typeId_t size = *(typeId_t*)(data + byteIndex);
*(typeId_t*)(myData + byteIndex) = size;
byteSize = size * sizeof(typeId_t);
byteIndex += sizeof(typeId_t);
// copy types
memcpy(myData + byteIndex, data + byteIndex, byteSize);
byteIndex += byteSize;
offset = *(ptrdiff_t*)(data + byteIndex);
}
}
// We only need the previous type data array, but not its size or end marker as we will insert them ourselves
char myData[sizeof(TypeData<Base>) - sizeof(ptrdiff_t) - sizeof(typeId_t)];
};
This code iterates through the base type's data and fills the derived type's data. It finally stops when the offset found is 0, which denotes the end.
Interesting things to note:
- It doesn't simply copy the data but it will add an extra potential offset to the base's data to account for pointer offset adjustment. This is why in the single inheritance example, we passed an offset of 0.
- The size of the buffer constructed is based on the base types TypeData structure, of which we only need the internal array. We have added our own size and end markers in the TypeDataImpl above.
Multiple Inheritance
In a multiple inheritance scenario, we use variadic templates to build the BaseTypeData recursively:
template<typename Type, typename... BaseTypes>
struct TypeDataImpl
{
TypeDataImpl()
{
myTypeId = GenerateId();
myBaseTypeData.FillBaseTypeData<Type>(0 /* No offset with first base */, mySize);
mySize++; // Size is the base's size + 1 to account for current type id
myEndMarker = 0;
}
const char* GetData() const
typeId_t mySize;
typeId_t myTypeId;
BaseTypeData<BaseTypes...> myBaseTypeData;
ptrdiff_t myEndMarker;
};
The base type data is built taking into account pointer offset. We can calculate it as the base types are unpacked in the variadic expansion, and the final derived type is passed as a template parameter to FillBaseTypeData. This is why we needed to use a static method and not a constructor. The sizes of the following lists are not incremented as no Type ID is added.
template<typename FirstBase, typename SecondBase, typename... Next>
struct BaseTypeData<FirstBase, SecondBase, Next...>
{
template<typename Derived>
void FillBaseTypeData(ptrdiff_t aOffset, typeId_t& outHeadSize)
{
myFirst.FillBaseTypeData<Derived>(ComputePointerOffset<Derived, FirstBase>(), outHeadSize);
myOffset = ComputePointerOffset<Derived, SecondBase>();
myNext.FillBaseTypeData<Derived>(myOffset, mySize);
}
BaseTypeData<FirstBase> myFirst;
ptrdiff_t myOffset;
typeId_t mySize;
BaseTypeData<SecondBase, Next...> myNext;
};
One word of warning: this technique may be compromised by the compilers. Padding may be added which will not keep the type data contiguous in memory and the algorithms will fail. We can however prevent that using #pragma pack which is supported by most compilers, or other compiler-specific packing options.
Here is the mechanic visualized:
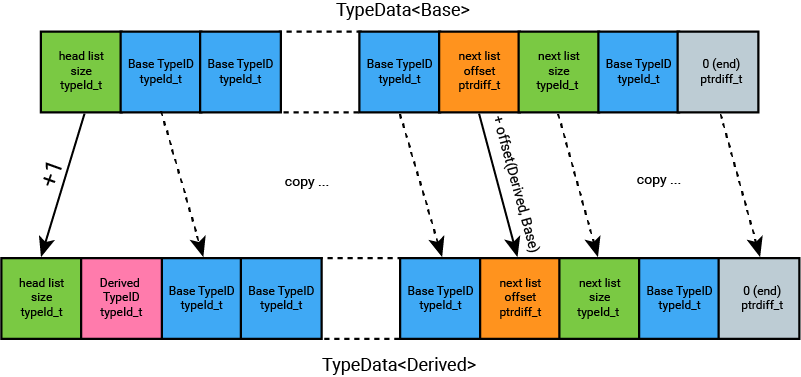
Registering a type
With the TypeDataImpl and TypeInfo taken care of, it is now time to implement the mechanic to instanciate these and retrieve them.
We need to assemble a TypeInfo with the name of the type followed by its TypeData<T>:
template<typename T>
struct TypeInfoImpl
{
const TypeInfo myInfo;
const TypeData<T> myData;
};
We can now use this in a type registration macro. The macro is needed to trigger template specialization and therefore trigger the instanciation of this TypeInfoImpl. Conveniently, we also use the macro to retrieve the type name.
First we declare tye TypeData<T> type, using macro expansion tricks to extract the first argument and inherit from TypeDataImpl<Type, BaseTypes...>.
#define KCL_RTTI_REGISTER(...) \
template<> \
struct TypeData<KCL_FIRST_ARG(__VA_ARGS__)> : public TypeDataImpl<__VA_ARGS__> ; \
// continued...
Finally the static instance of the TypeInfo (contained in the TypeInfoImpl) is accessed through a static method on the specialization of the GetTypeInfo stuct.
// continuation... TYPE is the type being registered
template<> \
struct GetTypeInfo<TYPE> \
{ \
static const TypeInfo* Get() \
{ \
static TypeInfoImpl<TYPE> ourInstance = ; \
return &ourInstance.myInfo; \
} \
};
We can now retrieve the TypeInfo at compile time, but we also need it at runtime. For this we must use a virtual method.
This is declared in a second macro that must be used within the derived type declaration scope:
#define KCL_RTTI_IMPL() \
\
virtual const TypeInfo* KCL_RTTI_GetTypeInfo() const \
{ \
typedef std::remove_pointer<decltype(this)>::type ObjectType; \
return GetTypeInfo<ObjectType>::Get(); \
} \
Dynamic Cast
The goal is finally within our reach. We have built all the type information necessary to perform a dynamic cast and we can access it at runtime on an instance of a registered type.
However, there are still a few subtleties in the dynamic cast implementation:
- We must not forget to handle the case of a null pointer. Interestingly, the pointer offset is not performed when the parameter of static_cast or dynamic_cast is called.
- We can avoid the expensive dynamic_cast logic if we can safely call static_cast instead. We will use if constexpr here but SFINAE can be used as polyfill.
- The offset present in the TypeData<T> is relative to the canonical pointer of the object, that is the pointer to an instance of its most derived type. If we hold a pointer to this object at an offset, we must perform the dynamic cast from the canonical this pointer. Fortunately the final overrider rule in the standard allows us to do this using a virtual method.
Here is the final implementation of dynamic_cast:
//continuation of KCL_RTTI_IMPL, this method is declared in the object and allows to always begin from the canonical "this" pointer
virtual intptr_t KCL_RTTI_DynamicCast(typeId_t aOtherTypeId) const \
{ \
typedef std::remove_pointer<decltype(this)>::type ObjectType; \
return GetTypeInfo<ObjectType>::Get()->CastTo((intptr_t)this, aOtherTypeId); \
}
//Implementation of dynamic_cast in the global namespace
template<typename Derived, typename Base>
Derived kcl_dynamic_cast(Base* aBasePtr)
{
static_assert(std::is_pointer<Derived>::value, "Return type must be a pointer");
typedef std::remove_pointer<Derived>::type DerivedObjectType;
if constexpr (std::is_base_of<DerivedObjectType, Base>::value)
return static_cast<Derived>(aBasePtr);
else if (aBasePtr)
return reinterpret_cast<Derived>(aBasePtr->KCL_RTTI_DynamicCast(GetTypeId<DerivedObjectType>()));
else
return nullptr;
}
And there we have it. The real implementation is slightly more complex to ensure more type safety and avoid polluting the global scope, but the principle is essentially the same.
Benchmark
We have done our best to design a RTTI system by packing all the information in a contiguous region of memory accessible at the cost of one virtual method call.
Let's see how it performs against the standard implementation and confirm that ours is indeed faster.
Each benchmark runs 3000000 dynamic_casts, and the measure is taken 10 times. Tests have shown that increasing those numbers significantly yields similar results so we will consider this enough to take conclusions.
Single Inheritance
Here we tested downcasting to the most derived type of a single inheritance chain of varying levels.

We can see the cost of dynamic_casting increasing with the number of base types. KCL performs better on all compilers.
Multiple Inheritance
Similar results can be obtained when examining multiple inheritance. The nested multiple inheritance case is interesting as some of its second bases themselves have second bases. This validates the pointer offset adjustment logic and is assumed to be one of the most complex cases for linked-list implementations to follow.
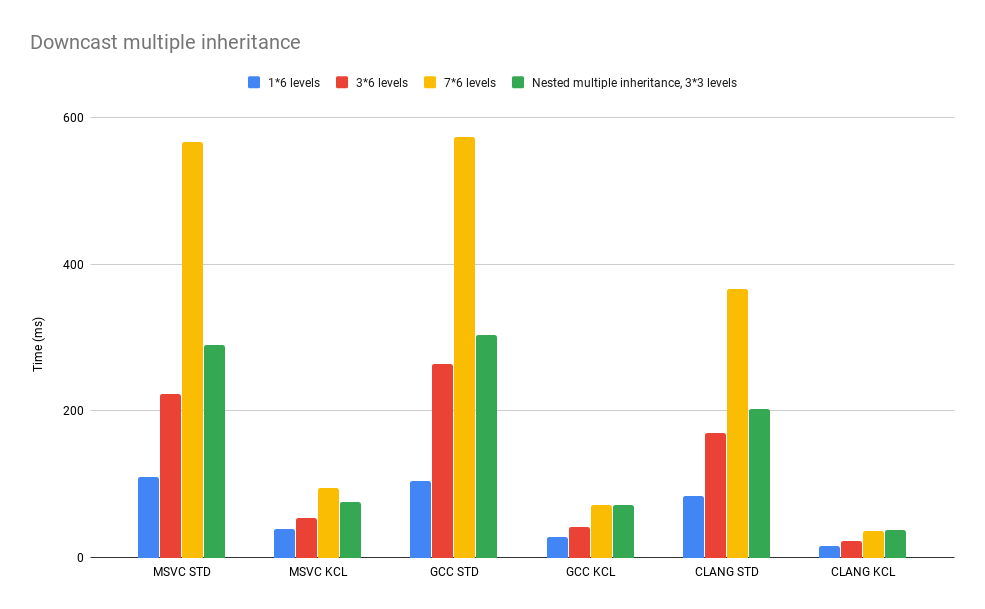 Once again KCL is dramatically faster in all scenarios.
Once again KCL is dramatically faster in all scenarios.
Wrong casts
Here let's examine the cost of dynamic_cast to a type that is not part of the type's hierarchy. This is the very worst case as the algorithm has to iterate through the entire type information before failing to cast.
We will also test casts with a nullptr input value.
 The results are similar again, KCL performs better and the speed gain is higher the more complex hierarchies are traversed. Nullptr cast is virtually the same except for MSVC where it is up to 5 times slower at 10ms!
The results are similar again, KCL performs better and the speed gain is higher the more complex hierarchies are traversed. Nullptr cast is virtually the same except for MSVC where it is up to 5 times slower at 10ms!
Findings
- Averaged over all the results, KCL performs more than 3.5 times faster with MSVC, more than 4.5 times faster with GCC, and more than 6 times faster with clang!
- The cost of the standard implementations dramatically increases with the size of the hierarchy. For KCL it only increases linearly.
- The initial cost of a dynamic_cast is always lower with KCL. We can assume retrieving the TypeInfo is more complex in the standard implementation.
- clang performs consistently better than GCC and MSVC.
- Interestingly, the compilers with the fastest implementation of dynamic cast also seem to perform better optimizations of KCL which results in an even bigger spead increase over their own implementation.
- I did not report the metrics of upcasts that can be optimized with static_cast. This is because all compilers perform this successfully as well as KCL, compiling down to the exact same code.
Limitations and possible improvements
Our approach has some caveats and limitations as opposed to the standard library's dynamic cast. Let's try to list them all:
- The TypeInfo is created on first access in the static method call. This means the startup performance should be less than the standard, which can compute embed all type info in the executable.
- This is not thread safe. There could be race conditions in which the TypeID of a type is generated twice at the same time. This can be alleviated in various ways.
- The static mechanic used to build the TypeID make this not safe to pass across module boundaries. This could be improved by generating a TypeID using a hash of the symbol name.
- The TypeData architecture duplicates some information by design, and therefore uses more executable space than is stricly necessary. Using linked lists we could theoretically use less space but the runtime performance would be impacted significantly.
- The design relies on compiler tricks and assumptions that may not hold true, especially with regards to padding. More static asserts, unit testing and instrumentation could be added to validate the integrity of the memory layout.
- Behaviors related to std::bad_cast exception is not supported as opposed to the standard. If you really need it, it can be added.
- In addition, we do not support dynamic casting references. This is because references should never be null, therefore a failed cast could break otherwise correct assumptions. The standard dynamic cast uses exceptions which we cannot use. This is however not a big issue as pointer logic can always be substituted.
- You may have noticed I am using the std type traits. This is to allow you to easily port the code. If you do not want to depend on std at all you can reimplement this easily and better manage your compilation times.
As far as I'm concerned, these tradeoffs are worth the performance boost, and most of the issues can be alleviated by building upon this base.
If you find more issues with my code, please reach out to me, or better send a pull request!
I hope you enjoyed this breakdown of a possible RTTI implementation as much as I enjoyed making it. More is coming for KCL, so stay tuned for the next article.




Top comments (0)