
The premise
Log management in modern organizations
In most enterprises today, big, and small, it is not uncommon to have a tech stack comprising 50 or more different technologies across their applications and infrastructure, and this number is likely to increase as companies embrace microservices, multi/hybrid clouds, and containerization.
All these individual components generate logs, and lots of the. These logs serve as invaluable sources of information, providing insights into the health of individual components, transaction details, timestamps, and other critical data. By analyzing these logs, SREs and DevOps engineers can gain a comprehensive understanding of their systems, diagnose issues promptly, and optimize performance. Development teams rely on these logs to understand and address issues before they affect customers and businesses.
Each log entry represents a specific event that happened at a precise moment in time, allowing for accurate tracking and analysis of system behavior. For instance, when a fault occurs, logs enable developers to identify errors and look for related logs, system performance metrics, and application traces and drill down to the exact line of code to troubleshoot.
Challenges in managing Terabyte and Petabyte scale logs
As more logs get generated, it quickly becomes a “storage” and “search” problem. Although individual logs are tiny – just a few Bytes, the cumulative volume of logs across your stack, multiplied over several days can quickly reach Terabytes or Petabytes. Efficient search and storage mechanisms become crucial for developers and engineers in handling this large log volume.
Log retention, defines how long the logs are stored and in turn determines the total log volume. Factors such as security, regulatory compliances and cost have to be taken into account, to arrive at an optimal log retention period. Striking a balance between cost-effectiveness and fulfilling operational, analytical, and regulatory needs is key to optimizing log storage.
However, retaining logs for extended periods, spanning months or years, introduces complications. The common approach of compressing and storing logs in cost-effective solutions like AWS Glacier hinders real-time log retrieval and search capabilities. While suitable for auditing, this method limits developers' ability to efficiently analyze and troubleshoot logs in a timely manner.
To overcome these limitations, engineers require a solution that allows quick access to archived logs without sacrificing real-time search functionality. This ensures developers can effectively analyze logs, even in long-term retention scenarios, enabling timely analysis and troubleshooting.
Introducing SnappyFlow's Secondary storage feature
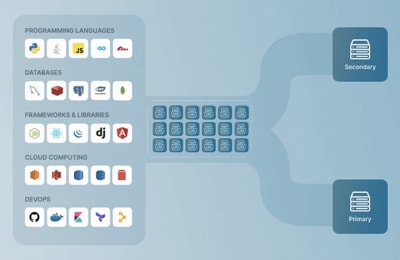
SnappyFlow provides an elegant solution to ingest, store and search large volumes of logs for extended periods of time using what we call the “Secondary Storage” feature. Secondary Storage allows massive streams of logs to be ingested and stored in a cost-efficient manner without losing the ability to easily search logs.
So, is there a Primary Storage?
Yes. By default, all logs sent to SnappyFlow are stored in a “Primary Storage”. Think of Primary storage as fast and responsive storage system capable of handling a large volume of searches at lightning-fast speeds. These are typically fast SSD-type storages and are as expected, expensive.
How does Secondary Storage work?
Different log sources can be configured to send logs to Primary Storage, Secondary Storage, or both.
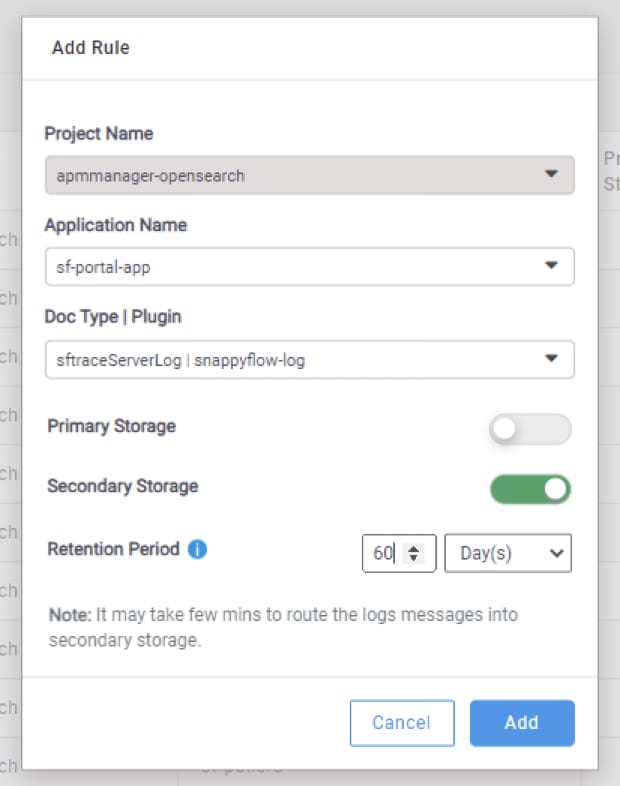
This is available under Log Management > Manage Logs. In the screenshot below, you can see a list of rules for the project apmmanager-opensearch. Note that in this example, you are looking at project-level rules. Similar views are available at Application and Profile levels.


The default rules are set to send all logs to both Primary and Secondary storage with a retention period of 7 days and 30 days respectively. New rules can be added using the Add Rule button and it takes a couple of minutes for these rules to get activated.

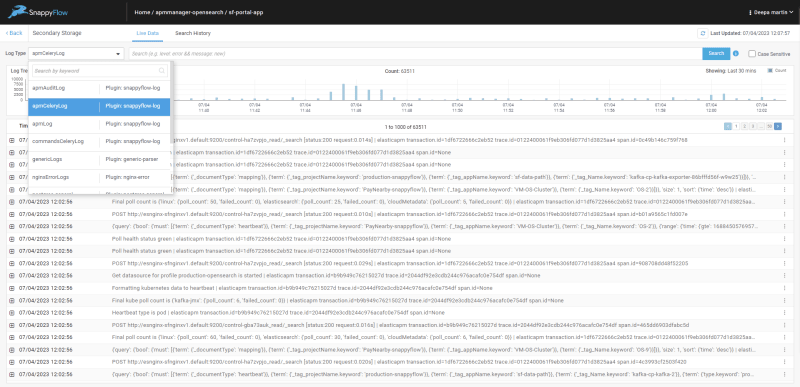
Searching logs in Secondary Storage
Search for logs in secondary storage is available under the respective applications. To access go to any application and select Log Management > Secondary Storage
In the Secondary Storage page, live search is available for data from the last 30 minutes. Logs can be filtered using the log type or using simple search strings. The Search History tab allows you to create search jobs and these jobs run in the background. Once a search job is completed, the search results can be accessed instantly any time.
Limitations
All logs in secondary storage can be searched in real-time (only the last 30 minutes) or search jobs can be set up and the indexed results can be accessed instantly.
It is not possible to create dashboard out of logs in secondary storage.
Secondary storage logs are not part of the usual log workflow i.e trace to log
An illustration of the benefit of using secondary storage for log management
Secondary storage can compress logs by upto 40 times the original size and can provide significant cost benefits. Consider a medium-sized SnappyFlow deployment with an average daily ingest volume of 1 TB with a retention of 15 days. At any given time, 15 TB of primary storage is required simply to hold this data. If we were to use Secondary storage to move say 60% of all the logs, we would need to incrementally store only 400 GB of logs on a daily basis and this works out to 6 TB of primary storage.
At the time of writing, the cost of EBS storage on AWS is
15 TB, GP3 - $2001/mo
6 TB, GBP - $800/mo
Here, there is a straightforward reduction in monthly costs of $1200 simply by routing 60% of logs to Secondary storage. Do note that there will be an additional cost of storing data in Secondary Storage but this is significantly lower as we will be using an object-based storage service like S3.
With a compression factor of 40x and a log retention period of 60 days, total log volume in secondary storage will be (1 TB/day * 60% * 60 days) / 40 = 0.9 TB
S3 storage cost is just $20 for ~1TB of compressed logs.
Explore Secondary Storage today!
Secondary Storage features are available to all SaaS and Self Hosted Turbo customers. Secondary Storage is the easiest and simplest way to control your logs storage costs and stay compliant to long term regulatory and security requirements. What’s more? This feature comes at no extra cost.
To try SnappyFlow, start your 14-day free trial today.

Top comments (0)