
In Data Engineering we have large sets of data that will be queried to obtain meaningful results. SQL is heavily used and it will be a crucial skill for a one to write and execute complex queries.
We have various non-relational databases such as MySQL,SQL Server, PostgreSQL, Oracle Database and many others. The good thing is they all use SQL query language for their queries, so they do not differ too much. In this post I will use PostgreSQL to write queries. PostgreSQL is an advanced, enterprise-class, and open-source relational database system. PostgreSQL supports both SQL (relational) and JSON (non-relational) querying.
Fundamentals in PostgreSQL
- Select, Column Aliases, Order By, Select Distinct, Where, Limit, Fetch, In, Between, Like, Is Null, Table Aliases.
- Joins, Inner Join, Left Join, Self-Join, Full Outer Join, Cross Join, Natural Join
- Group By, Union, Intersect, Having, Grouping Sets, Cube, Rollup, Subquery, Any, All, Exists
- Insert, Insert Multiple Rows, Update, Update Join, Delete, Delete Join, Upsert
The SELECT statement has the following clauses:
- Select distinct rows using DISTINCT operator.
- Sort rows using ORDER BY clause.
- Filter rows using WHERE clause.
- Select a subset of rows from a table using LIMIT or FETCH clause.
- Group rows into groups using GROUP BY clause.
- Filter groups using HAVING clause.
- Join with other tables using joins such as INNER JOIN, LEFT JOIN, FULL OUTER JOIN, CROSS JOIN clauses.
- Perform set operations using UNION, INTERSECT, and EXCEPT.
SELECT
select_list
FROM
table_name;
SELECT first_name, last_name, goods_bought FROM customer;
To select data from all columns of the customer table:
SELECT * FROM consumer_reports;
However, it is not a good practice to use the asterisk (*) in the SELECT statement when you embed SQL statements in the application code. It is a good practice to explicitly specify the column names in the SELECT clause whenever possible to get only necessary data from the database.
A column alias allows you to assign a column or an expression in the select list of a SELECT statement a temporary name. The column alias exists temporarily during the execution of the query.
SELECT column_name AS alias_name
FROM table_name;
SELECT
first_name || ' ' || last_name AS full_name
FROM
consumer_reports;
The ORDER BY clause allows you to sort rows returned by a SELECT clause in ascending or descending order based on a sort expression.
SELECT
select_list
FROM
table_name
ORDER BY
sort_expression1 [ASC | DESC],
...
...
sort_expressionN [ASC | DESC];
SELECT
first_name,
last_name
FROM
consumer_reports
ORDER BY
first_name DESC;
The DISTINCT clause is used in the SELECT statement to remove duplicate rows from a result set. The DISTINCT clause keeps one row for each group of duplicates. The DISTINCT clause can be applied to one or more columns in the select list of the SELECT statement.
SELECT
DISTINCT column1, column2, column3, column4
FROM
table_name;
SELECT
DISTINCT shape,
color
FROM
records
ORDER BY
color;
The SELECT statement returns all rows from one or more columns in a table. To select rows that satisfy a specified condition, you use a WHERE clause. WHERE clause filters rows returned by a SELECT statement.
SELECT select_list
FROM table_name
WHERE condition
ORDER BY sort_expression
To form the condition in the WHERE clause, you use comparison and logical operators:
AND -- Logical operator AND
OR -- Logical operator OR
IN -- Return true if a value matches any value in a list
BETWEEN -- Return true if a value is between a range
of values
LIKE -- Return true if a value matches a pattern
IS NULL -- Return true if a value is NULL
NOT -- Negate the result of other operators
SELECT
last_name,
first_name
FROM
consumer_records
WHERE
first_name = 'Brian' AND
last_name = 'Kamau';
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name IN ('Brian','Kelvin','Martin');
PostgreSQL LIMIT is an optional clause of the SELECT statement that constrains the number of rows returned by the query.
SELECT select_list
FROM table_name
ORDER BY sort_expression
LIMIT row_count
In case you want to skip a number of rows before returning the row_count rows, you use OFFSET clause placed after the LIMIT clause as the following statement:
SELECT select_list
FROM table_name
LIMIT row_count OFFSET row_to_skip;
This query will display the first 20 rows from our film table, which will be ordered in descending order.
SELECT
film_id,
title,
release_year
FROM
film
ORDER BY
film_id DESC
LIMIT 20;
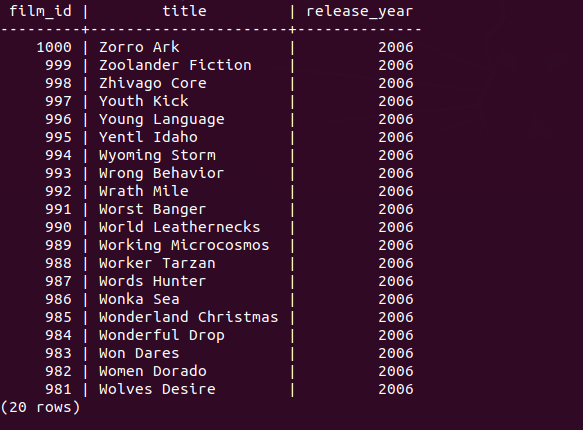
This query will skip 15 rows then proceed to display the next 20 rows only.
SELECT
film_id,
title,
release_year
FROM
film
ORDER BY
film_id
LIMIT 20 OFFSET 15;
To constrain the number of rows returned by a query, you often use the LIMIT clause. However, the LIMIT clause is not a SQL-standard. To conform with the SQL standard, PostgreSQL supports the FETCH clause to retrieve a number of rows returned by a query.
Syntax of the PostgreSQL FETCH clause:
OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ row_count ] { ROW | ROWS } ONLY
In this syntax:
ROW is the synonym for ROWS, FIRST is the synonym for NEXT, you can use them interchangeably.
The start is an integer that must be zero or positive.
The row_count is 1 or greater.
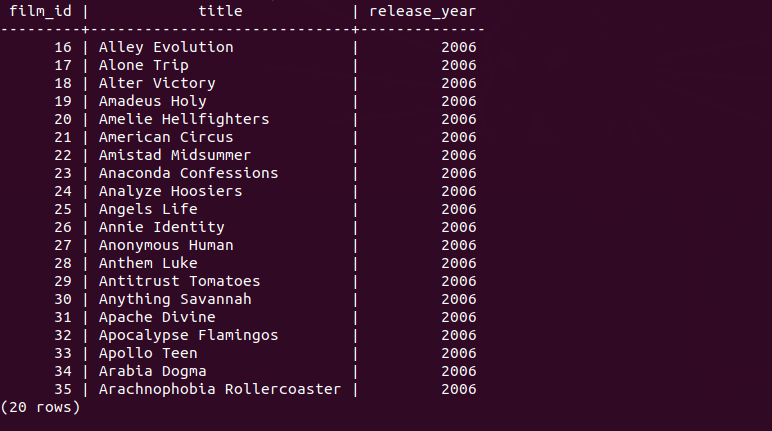
This query will skip the first 20 rows then proceed to display the next 20 rows.
SELECT
film_id,
title
FROM
film
ORDER BY
title
OFFSET 20 ROWS
FETCH FIRST 20 ROWS ONLY;
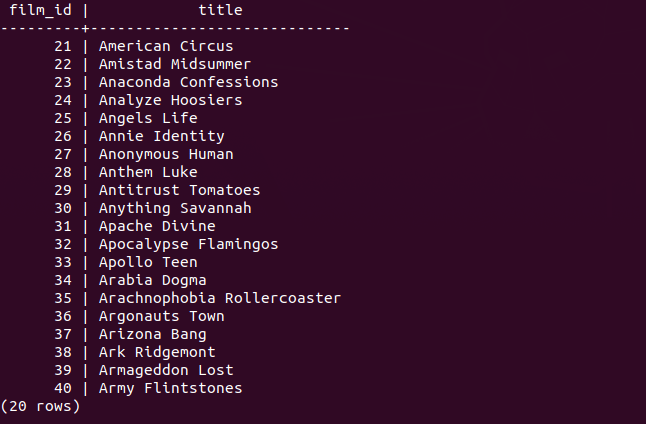
You use IN operator in the WHERE clause to check if a value matches any value in a list of values.
The syntax of the IN operator is as follows:
value IN (value1,value2,value3, value4, ..., valueN)
This query will return the first 15 rows that has customer id of 1 and 2.
SELECT customer_id,
rental_id,
return_date
FROM
rental
WHERE
customer_id IN (1, 2)
ORDER BY
return_date DESC
FETCH FIRST 15 ROWS ONLY;
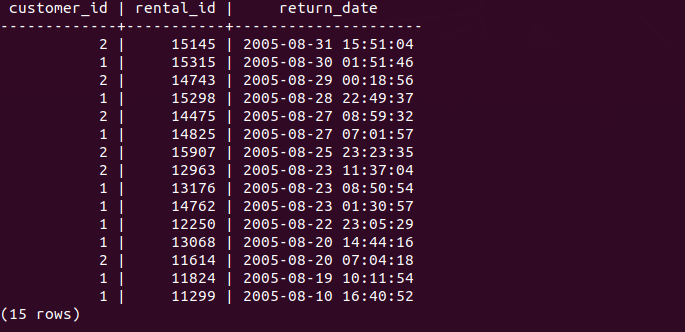
You can combine the IN operator with the NOT operator to select rows whose values do not match the values in the list.
The following query finds all rentals with the customer id is not 1 or 2.
SELECT
customer_id,
rental_id,
return_date
FROM
rental
WHERE
customer_id NOT IN (1, 2)
FETCH NEXT 20 ROWS ONLY;

You use the BETWEEN operator to match a value against a range of values. The syntax of the BETWEEN operator:
value BETWEEN low AND high;
To check if a value is out of a range, you combine the NOT operator with the BETWEEN operator as follows:
value NOT BETWEEN low AND high;
Often used the BETWEEN operator in the WHERE clause.
This query will return the first 20 rows where the price is between 10 and 12.
SELECT
customer_id,
payment_id,
amount
FROM
payment
WHERE
amount BETWEEN 10 AND 12
FETCH FIRST 15 ROWS ONLY;
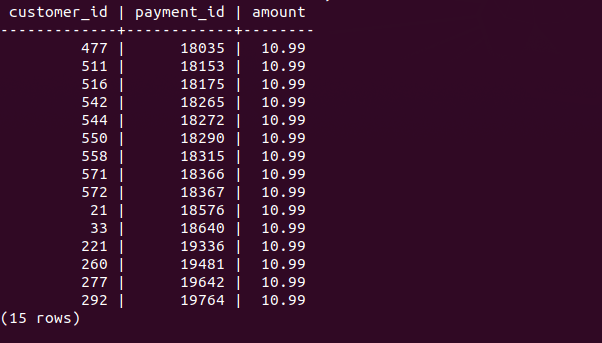
This query returns the first 15 rows that do not meet the condition in the where clause.
SELECT
customer_id,
payment_id,
amount
FROM
payment
WHERE
amount NOT BETWEEN 10 AND 12
FETCH FIRST 15 ROWS ONLY;
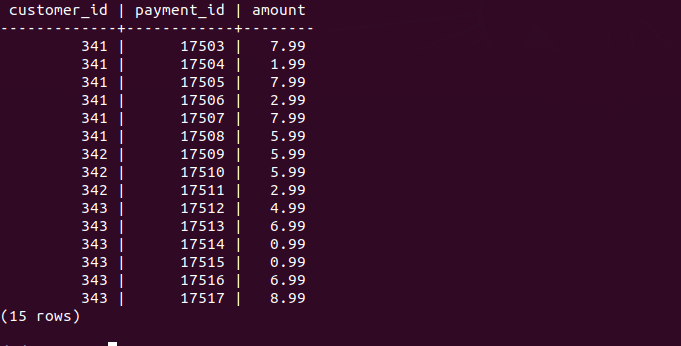
To construct a pattern by combining literal values with wildcard characters and use the LIKE or NOT LIKE operator to find the matches. PostgreSQL provides you with two wildcards:
- Percent sign ( %) matches any sequence of zero or more characters.
- Underscore sign ( _) matches any single character.
value LIKE pattern
PostgreSQL supports the ILIKE operator that works like the LIKE operator. In addition, the ILIKE operator matches value case-insensitively.
This query will return all the first name which have 'er' in between the name, then skips 5 rows then fetches the next 20 rows which are ordered according to first_name.
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE '%er%'
ORDER BY
first_name
OFFSET 5 ROWS
FETCH FIRST 20 ROWS ONLY;

In database, NULL means missing information or not applicable. NULL is not a value, therefore, you cannot compare it with any other values like numbers or strings.
To check if a value is not NULL, you use the IS NOT NULL operator:
value IS NOT NULL
Table aliases temporarily assign tables new names during the execution of a query.
table_name AS alias_name;
Inner Join
In a relational database, data is typically distributed in more than one table. To select complete data, you often need to query data from multiple tables.Let us understand to combine data from multiple tables using the INNER JOIN clause.
Suppose that there are two tables car and manufacturer. The table car has a column model whose value matches with values in the make column of table manufacturer. To select data from both tables, you use the INNER JOIN clause in the SELECT statement as follows:
SELECT
model,
year,
make,
origin
FROM
Car
INNER JOIN manufacturer ON model = make;
To join table car with the table manufacturer, you follow these steps:
- First, specify columns from both tables that you want to select data in the SELECT clause.
- Second, specify the main table for example table car in the FROM clause.
- Third, specify the second table (table manufacturer) in the INNER JOIN clause and provide a join condition after the ON keyword.
How the INNER JOIN works.
For each row in the table car, inner join compares the value in the model column with the value in the make column of every row in the table manufacturer:
If these values are equal, the inner join creates a new row that contains all columns of both tables and adds it to the result set.
In case these values are not equal, the inner join just ignores them and moves to the next row.

This query returns the customer with id of 3 and the amount and date which it is paid.
SELECT
c.customer_id,
first_name,
last_name,
amount,
payment_date
FROM
customer c
INNER JOIN payment p
ON p.customer_id = c.customer_id
WHERE
c.customer_id = 3;

Left Join
There are two tables, car and manufacturer table. Each row in the table car may have zero or many corresponding rows in the table manufacturer while each row in the table manufacturer has one and only one corresponding row in the table car .
To select data from the table car that may or may not have corresponding rows in the table manufacturer, you use the LEFT JOIN clause.
SELECT
model,
year,
make,
origin
FROM
Car
Left JOIN manufacturer ON model = make;
To join the table car with the manufacturer table using a left join:
- First, specify the columns in both tables from which you want to select data in the SELECT clause.
- Second, specify the left table (table car) in the FROM clause.
- Third, specify the right table (table manufacturer) in the LEFT JOIN clause and the join condition after the ON keyword.
- The LEFT JOIN clause starts selecting data from the left table. For each row in the left table, it compares the value in the model column with the value of each row in the make column in the right table.
If these values are equal, the left join clause creates a new row that contains columns that appear in the SELECT clause and adds this row to the result set.
In case these values are not equal, the left join clause also creates a new row that contains columns that appear in the SELECT clause. In addition, it fills the columns that come from the right table with NULL.
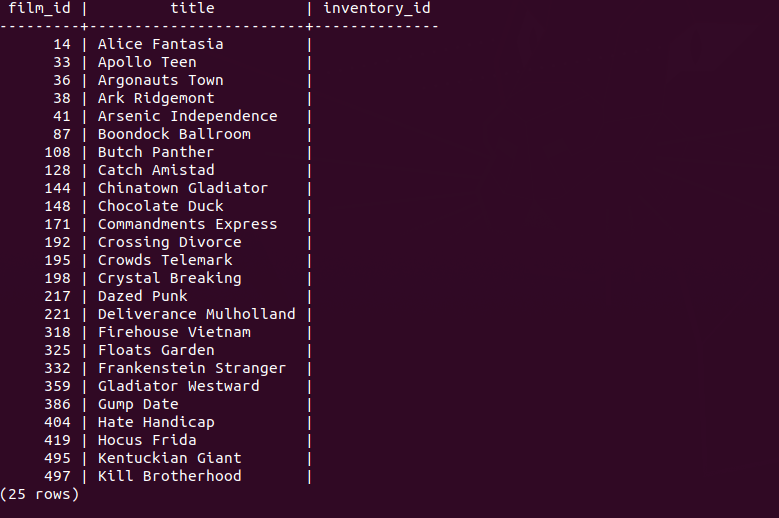
this query will return the first 25 rows on the left join clause to join the film table with inventory table.
SELECT
f.film_id,
title,
inventory_id
FROM
film f
LEFT JOIN inventory i
ON i.film_id = f.film_id
WHERE i.film_id IS NULL
ORDER BY title
FETCH FIRST 25 ROWS ONLY;
Self-Join
A self-join is a regular join that joins a table to itself, a self-join query hierarchical data or to compare rows within the same table.
SELECT select_list
FROM table_name t1
INNER JOIN table_name t2 ON join_predicate;
The above table is joined to itself using the INNER JOIN clause.
SELECT select_list
FROM table_name t1
LEFT JOIN table_name t2 ON join_predicate;
The above table is joined to itself using the LEFT JOIN clause.
This query finds all pair of films which are not duplicates that have the same length. It will skip the first 15 rows then return the next first 25 rows that have films of the same length.
SELECT DISTINCT
f1.title,
f2.title,
f1.length
FROM
film f1
INNER JOIN film f2
ON f1.film_id <> f2.film_id AND
f1.length = f2.length
OFFSET 15 ROWS
FETCH FIRST 25 ROWS ONLY;

Full Outer Join

Syntax of the full outer join:
SELECT * FROM car
FULL [OUTER] JOIN manufacturer on car.id = manufacturer.id;
If the rows in the joined table do not match, the full outer join sets NULL values for every column of the table that does not have the matching row.
If a row from one table matches a row in another table, the result row will contain columns populated from columns of rows from both tables.
Cross Join
CROSS JOIN clause allows you to produce a Cartesian Product of rows in two or more tables.
Cross Join Syntax:
SELECT select_list
FROM table1
CROSS JOIN table2;
This statement is similar to:
SELECT select_list
FROM T1, T2;
Natural Join
It is a join that creates an implicit join based on the same column names in the joined tables.
A natural join can be an inner join, left join, or right join. If you do not specify a join explicitly, PostgreSQL will use the INNER JOIN by default.
Natural Join syntax:
SELECT select_list
FROM table1
NATURAL [INNER, LEFT, RIGHT] JOIN table2;
The convenience of the NATURAL JOIN is that it does not require you to specify the join clause because it uses an implicit join clause based on the common column.
However, avoid using the NATURAL JOIN whenever possible because sometimes it may cause an unexpected result.
Group By
GROUP BY clause divides the rows returned from the SELECT statement into groups. For each group, you can apply an aggregate function for example SUM() to calculate the sum of items or COUNT() to get the number of items in the groups.
Basic Syntax of Group By:
SELECT
column_1,
column_2,
...,
aggregate_function(column_n)
FROM
table_name
GROUP BY
column_1,
column_2,
...
column_n;
This query will return 25 rows from the payment table grouped by customer id, ordered in descending of the total amount
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id
ORDER BY
SUM (amount) DESC
FETCH FIRST 25 ROWS ONLY;

We can use multiple columns with Group By. In this query Group By clause divides the rows in the payment table by the values in the customer_id and staff_id columns. SUM() calculates the total amount. Then ordered by the customer_id in ascending order. It fetches the first 30 rows from our table payment.
SELECT
customer_id,
staff_id,
SUM(amount)
FROM
payment
GROUP BY
staff_id,
customer_id
ORDER BY
customer_id
FETCH FIRST 30 ROWS ONLY;

Having
HAVING clause specifies a search condition for a group or an aggregate. The HAVING clause is often used with the GROUP BY clause to filter groups or aggregates based on a specified condition.
SELECT
column_1,
column_2,
...
aggregate_function (column_n)
FROM
table_name
GROUP BY
column_1
HAVING
condition;
PostgreSQL evaluates the HAVING clause after the FROM, WHERE, GROUP BY, and before the SELECT, DISTINCT, ORDER BY and LIMIT clauses.
Since the HAVING clause is evaluated before the SELECT clause, you cannot use column aliases in the HAVING clause. Because at the time of evaluating the HAVING clause, the column aliases specified in the SELECT clause are not available.
The WHERE clause allows you to filter rows based on a specified condition. However, the HAVING clause allows you to filter groups of rows according to a specified condition.
The WHERE clause is applied to rows while the HAVING clause is applied to groups of rows.
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id
HAVING
SUM (amount) > 150;

Union Operator
UNION operator combines result sets of two or more SELECT statements into a single result set.
SELECT select_list_1
FROM table_1
UNION
SELECT select_list_2
FROM table_2
To combine the result sets of two queries using the UNION operator, ensure that:
The number and the order of the columns in the select list of both queries must be the same. The data types must be compatible.
The UNION operator removes all duplicate rows from the combined data set. Use the the UNION ALL to retain duplicate rows.
Intersect Operator
PostgreSQL INTERSECT operator combines result sets of two or more SELECT statements into a single result set.
The INTERSECT operator returns any rows available in both result sets.
SELECT select_list
FROM table_1
INTERSECT
SELECT select_list
FROM table_2;
The number of columns and their order in the SELECT clauses must be the same. The data types of the columns must be compatible. When using the Intersect operator.
Except
EXCEPT operator returns rows by comparing the result sets of two or more queries. It returns distinct rows from the first (left) query that are not in the output of the second (right) query.
SELECT select_list
FROM table_1
EXCEPT
SELECT select_list
FROM table_2;
RollUp
PostgreSQL ROLLUP is a subclause of the GROUP BY clause that offers a shorthand for defining multiple grouping sets. A grouping set is a set of columns by which you group.
ROLLUP assumes a hierarchy among the input columns and generates all grouping sets that make sense considering the hierarchy. ROLLUP is often used to generate the subtotals and the grand total for reports.
This query finds the number of rental per day, month, and year by using the ROLLUP. It will skip 15 rows, then fetch the first 25 rows that follows.
SELECT
EXTRACT (YEAR FROM rental_date) y,
EXTRACT (MONTH FROM rental_date) M,
EXTRACT (DAY FROM rental_date) d,
COUNT (rental_id)
FROM
rental
GROUP BY
ROLLUP (
EXTRACT (YEAR FROM rental_date),
EXTRACT (MONTH FROM rental_date),
EXTRACT (DAY FROM rental_date)
)
OFFSET 15
FETCH FIRST 25 ROWS ONLY;
Cube
PostgreSQL CUBE is a sub clause of the GROUP BY clause. The CUBE allows you to generate multiple grouping sets. A grouping set is a set of columns to which you want to group.
This query generates all possible grouping sets based on the dimension columns specified in CUBE.
SELECT
c1, c2, c3,
aggregate (c4)
FROM
table_name
GROUP BY
CUBE (c1, c2, c3);
Subquery
A subquery is a query nested inside another query such as SELECT, INSERT, DELETE and UPDATE.
The query inside the brackets is called a subquery, the query that contains the subquery is known as an outer query.
PostgreSQL executes the query that contains a subquery in the following sequence:
First, executes the subquery then gets the result and passes it to the outer query. Lastly executes the outer query.
SELECT
film_id,
title,
rental_rate
FROM
film
WHERE
rental_rate > (
SELECT
AVG (rental_rate)
FROM
film
)
FETCH FIRST 30 ROWS ONLY;

The following query gets films that have the returned date between 2005-05-29 and 2005-05-30. Then 30 rows are skipped and the first 30 rows that follows are returned.
SELECT
film_id,
title
FROM
film f
WHERE
film_id IN (
SELECT
i.film_id
FROM
rental r
INNER JOIN inventory i ON i.inventory_id =
r.inventory_id
WHERE
return_date BETWEEN '2005-05-29'
AND '2005-05-30'
)
OFFSET 30 ROWS FETCH FIRST 30 ROWS ONLY;

All Operator
ALL operator allows you to query data by comparing a value with a list of values returned by a subquery.
comparison_operator ALL (subquery)
The ALL operator must be preceded by a comparison operator such as equal (=), not equal (!=), greater than (>), greater than or equal to (>=), less than (<), and less than or equal to (<=). Followed by a subquery which also must be surrounded by the parentheses.
- column_name > ALL (subquery) the expression evaluates to true if a value is greater than the biggest value returned by the subquery.
- column_name >= ALL (subquery) the expression evaluates to true if a value is greater than or equal to the biggest value returned by the subquery.
- column_name < ALL (subquery) the expression evaluates to true if a value is less than the smallest value returned by the subquery.
- column_name <= ALL (subquery) the expression evaluates to true if a value is less than or equal to the smallest value returned by the subquery.
- column_name = ALL (subquery) the expression evaluates to true if a value is equal to any value returned by the subquery.
- column_name != ALL (subquery) the expression evaluates to true if a value is not equal to any value returned by the subquery.
SELECT
film_id,
title,
length
FROM
film
WHERE
length > ALL (
SELECT
ROUND(AVG (length),2)
FROM
film
GROUP BY
rating
)
ORDER BY
length
FETCH FIRST 25 ROWS ONLY;

Exists Operator
The EXISTS operator is a boolean operator that tests for existence of rows in a subquery.It accepts an argument which is a subquery.
EXISTS (subquery)
SELECT
column1, column2
FROM
table_1
WHERE
EXISTS( SELECT
1
FROM
table_2
WHERE
column_2 = table_1.column_1);
This query statement returns customers who have paid at least one rental with an amount greater than 15
SELECT first_name,
last_name
FROM customer c
WHERE EXISTS
(SELECT 1
FROM payment p
WHERE p.customer_id = c.customer_id
AND amount > 15 )
ORDER BY first_name,
last_name;

Insert
INSERT statement allows you to insert a new row into a table.
INSERT INTO table_name(column1, column2, value3, ...)
VALUES (value1, value2, value3, ...);
For example this will insert values to a table called links, for the column url, name, last_modified columns.
INSERT INTO links (url, name, last_modified)
VALUES('https://www.dev.to','DEV','2022-09-20');
Insert Multiple Rows
INSERT INTO table_name (column_list)
VALUES
(value_list_1),
(value_list_2),
(value_list_3),
...
(value_list_n);
INSERT INTO
links (url, name, date_modified)
VALUES
('https://www.tradingview.com', 'tradingview', '2022-09-
15'),
('https://www.codenewbie.com','codenewbie', '2022-09-
18'),
('https://www.forem.com','Forem', '2022-09-20'),
('https://www.bitbucket.com', 'Bitbucket', '2022-09-20');
Update
UPDATE statement allows you to modify data in a table
UPDATE table_name
SET column1 = value1,
column2 = value2,
column3 = value3
...
WHERE condition;
UPDATE subjects
SET published_date = '2022-08-15'
WHERE subject_id = 231;
Returns the following message after one row has been updated:
UPDATE 1
Delete
DELETE statement allows you to delete one or more rows from a table.
DELETE FROM table_name
WHERE condition;
This will delete the row where the id is 7.
DELETE FROM links
WHERE id = 7;
This query deletes all the rows in our table since we did not specify a where clause.
DELETE FROM links;
The subquery returns a list of phones from the blacklist table and the DELETE statement deletes the contacts whose phones match with the phones returned by the subquery.To delete all contacts whose phones are in the blacklist table.
DELETE FROM contacts
WHERE phone IN (SELECT phone FROM blacklist);
Upsert
Referred to as merge, when you insert a new row into the table, PostgreSQL will update the row if it already exists, otherwise, it will insert the new row.
INSERT INTO table_name(column_list)
VALUES(value_list)
ON CONFLICT target action;
INSERT INTO customers (name, email)
VALUES('tradingview','hotline@tradingview')
ON CONFLICT (name)
DO NOTHING;
INSERT INTO customers (name, email)
VALUES('tradingview','hotline@tradingview')
ON CONFLICT (name)
DO
UPDATE SET email = EXCLUDED.email || ';' || customers.email;
Common Table Expressions (CTE)
It is a temporary result set which you can reference within another SQL statement including SELECT, INSERT, UPDATE or DELETE. They only exist during the execution of the query and used to simplify complex joins and subqueries in PostgreSQL.
WITH cte_name (column_list) AS (
CTE_query_definition
)
statement;
Advantages of using CTEs:
- Improve the readability of complex queries.
- Ability to create recursive queries, queries that reference themselves.
- Use CTEs in conjunction with window functions to create an initial result set and use another select statement to further process this result set.
This query, the CTE returns a result set that includes staff id and the number of rentals. Then, join the staff table with the CTE using the staff_id column.
WITH cte_rental AS (
SELECT staff_id,
COUNT(rental_id) rental_count
FROM rental
GROUP BY staff_id
)
SELECT s.staff_id,
first_name,
last_name,
rental_count
FROM staff s
INNER JOIN cte_rental USING (staff_id);
Recursive Query
A recursive CTE has three elements:
- Non-recursive term: a CTE query definition that forms the base result set of the CTE structure.
- Recursive term: one or more CTE query definitions joined with the non-recursive term using the UNION or UNION ALL operator.
- Termination check: the recursion stops when no rows are returned from the previous iteration.
Sequence that PostgreSQL executes a recursive CTE:
- Execute the non-recursive term to create the base result set
- Execute recursive term with Ri as an input to return the result set Ri+1 as the output.
- Repeat step 2 until an empty set is returned (termination check)
- Return the final result set that is a UNION or UNION ALL of the result set
WITH RECURSIVE cte_name AS(
CTE_query_definition -- non-recursive term
UNION [ALL]
CTE_query definion -- recursive term
) SELECT * FROM cte_name;
I trust you have understood the content that we have covered so far. Lets gear on and continue learning.

Managing Tables
PostgreSQL Data Types, Create Table, Select Into, Create Table As, Serial, Sequences, Identity Column, Alter Table, Rename Table, Add Column, Drop Column, Change Column’s Data Type, Rename Column, Drop Table, Temporary Table, Truncate Table
Transaction
A database transaction is a single unit of work that consists of one or more operations. A PostgreSQL transaction is atomic, consistent, isolated, and durable. These properties are often referred to as ACID:
- Atomicity guarantees that the transaction completes in an all-or-nothing manner.
- Consistency ensures the change to data written to the database must be valid and follow predefined rules.
- Isolation determines how transaction integrity is visible to other transactions.
- Durability makes sure that transactions that have been committed will be stored in the database permanently.
-- start a transaction
BEGIN;
-- insert a new row into the accounts table
INSERT INTO accounts(name,balance)
VALUES('Alice',10000);
-- commit the change (or roll it back later)
COMMIT;
-- start a transaction
BEGIN;
-- deduct 1000 from account 1
UPDATE accounts
SET balance = balance - 1000
WHERE id = 1;
-- add 1000 to account 2
UPDATE accounts
SET balance = balance + 1000
WHERE id = 2;
-- select the data from accounts
SELECT id, name, balance
FROM accounts;
-- commit the transaction
COMMIT;
-- begin the transaction
BEGIN;
-- deduct the amount from the account 1
UPDATE accounts
SET balance = balance - 1500
WHERE id = 1;
-- add the amount from the account 3 (instead of 2)
UPDATE accounts
SET balance = balance + 1500
WHERE id = 3;
-- roll back the transaction
ROLLBACK;
The easiest way to export data of a table to a CSV file is to use COPY statement.
COPY persons TO '/home/exporter/persons_db.csv' DELIMITER ',' CSV HEADER;
A relational database consists of multiple related tables. A table consists of rows and columns. Tables allow you to store structured data.
CREATE TABLE [IF NOT EXISTS] table_name (
column1 datatype(length) column_contraint,
column2 datatype(length) column_contraint,
column3 datatype(length) column_contraint,
table_constraints
);
Column Constraints
- NOT NULL – ensures that values in a column cannot be NULL.
- UNIQUE – ensures the values in a column unique across the rows within the same table.
- PRIMARY KEY – a primary key column uniquely identify rows in a table. A table can have one and only one primary key.
- FOREIGN KEY – ensures values in a column or a group of columns from a table exists in a column or group of columns in another table. Unlike the primary key, a table can have many foreign keys.
- CHECK – a CHECK constraint ensures the data must satisfy a boolean expression.
CREATE TABLE accounts (
user_id serial PRIMARY KEY,
username VARCHAR ( 50 ) UNIQUE NOT NULL,
password VARCHAR ( 50 ) NOT NULL,
email VARCHAR ( 255 ) UNIQUE NOT NULL,
created_on TIMESTAMP NOT NULL,
last_login TIMESTAMP
);
CREATE TABLE roles(
role_id serial PRIMARY KEY,
role_name VARCHAR (255) UNIQUE NOT NULL
);
CREATE TABLE account_roles (
user_id INT NOT NULL,
role_id INT NOT NULL,
grant_date TIMESTAMP,
PRIMARY KEY (user_id, role_id),
FOREIGN KEY (role_id)
REFERENCES roles (role_id),
FOREIGN KEY (user_id)
REFERENCES accounts (user_id)
);
SELECT
film_id,
title,
length
INTO TEMP TABLE short_film
FROM
film
WHERE
length < 60
ORDER BY
title;
SELECT * FROM short_film;
CREATE TABLE action_film AS
SELECT
film_id,
title,
release_year,
length,
rating
FROM
film
INNER JOIN film_category USING (film_id)
WHERE
category_id = 1;
SELECT * FROM action_film
ORDER BY title;
Serial
CREATE TABLE table_name(
id SERIAL
);
CREATE TABLE fruits(
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL
);
INSERT INTO fruits(name)
VALUES('Orange');
Sequence
CREATE SEQUENCE [ IF NOT EXISTS ] sequence_name
[ AS { SMALLINT | INT | BIGINT } ]
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ]
[ CACHE cache ]
[ [ NO ] CYCLE ]
[ OWNED BY { table_name.column_name | NONE } ]
Create a table
CREATE TABLE order_details(
order_id SERIAL,
item_id INT NOT NULL,
item_text VARCHAR NOT NULL,
price DEC(10,2) NOT NULL,
PRIMARY KEY(order_id, item_id)
);
CREATE SEQUENCE order_item_id
START 10
INCREMENT 10
MINVALUE 10
OWNED BY order_details.item_id;
INSERT INTO
order_details(order_id, item_id, item_text, price)
VALUES
(100, nextval('order_item_id'),'DVD Player',100),
(100, nextval('order_item_id'),'Android TV',550),
(100, nextval('order_item_id'),'Speaker',250);
SELECT
order_id,
item_id,
item_text,
price
FROM
order_details;
List all sequences in the current database
SELECT
relname sequence_name
FROM
pg_class
WHERE
relkind = 'S';
First, specify the name of the sequence which you want to drop and use the CASCADE option if you want to recursively drops objects that depend on the sequence, and objects that depend on the dependent objects.
DROP SEQUENCE [ IF EXISTS ] sequence_name [, ...]
[ CASCADE | RESTRICT ];
DROP TABLE order_details;
PostgreSQL identity column
PostgreSQL version 10 introduced a new constraint GENERATED AS IDENTITY that allows you to automatically assign a unique number to a column. The GENERATED AS IDENTITY constraint is the SQL standard-conforming variant of the good old SERIAL column.
column_name type GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY[ ( sequence_option ) ]
create a table named color with the color_id as the identity column:
CREATE TABLE color (
color_id INT GENERATED ALWAYS AS IDENTITY,
color_name VARCHAR NOT NULL
);
Insert new rows into the color table:
INSERT INTO color(color_name)
VALUES ('Green')
VALUES ('Blue');
Alter Table
To change the structure of an existing table, you use PostgreSQL ALTER TABLE statement.
ALTER TABLE table_name action;
Add a column, Drop a column, Change the data type of a column, Rename a column, Set a default value for the column, Add a constraint to a column, Rename a table.
CREATE TABLE links (
link_id serial PRIMARY KEY,
title VARCHAR (512) NOT NULL,
url VARCHAR (1024) NOT NULL
);
To add a new column named active, you use the following statement
ALTER TABLE links
ADD COLUMN active boolean;
To remove the active column from the links table.
ALTER TABLE links
DROP COLUMN active;
To add a new column named target to the links table
ALTER TABLE links
ADD COLUMN target VARCHAR(10);
To change the name of the links table to short_urls:
ALTER TABLE links
RENAME TO short_urls;
ALTER TABLE table_name
DROP COLUMN column_name;
To drop column that other objects depend on.
ALTER TABLE table_name
DROP COLUMN column_name CASCADE;
Drop Table
To drop a table from the database.
DROP TABLE [IF EXISTS] table_name
[CASCADE | RESTRICT];
The CASCADE option allows you to remove the table and its dependent objects. The RESTRICT option rejects the removal if there is any object depends on the table. The RESTRICT option is the default if you don’t explicitly specify it in the DROP TABLE statement.
Truncate Table
The TRUNCATE TABLE statement deletes all data from a table without scanning it. It is faster than the DELETE statement, TRUNCATE TABLE statement reclaims the storage right away so you do not have to perform a subsequent VACUMM operation, which is useful in the case of large tables.
This query removes all data and resets the identity column value.
TRUNCATE TABLE table_name
RESTART IDENTITY;
To remove data from a table and other tables that have foreign key reference the table, you use CASCADE option in the TRUNCATE TABLE statement
TRUNCATE TABLE table_name
CASCADE;
The TRUNCATE TABLE is transaction-safe. It means that if you place it within a transaction, you can roll it back safely.
Database Constraints
Primary Key, Foreign Key, Check Constraint, Unique Constraint
Not Null Constraint
Primary Key
A primary key is a column or a group of columns used to identify a row uniquely in a table. A table can have one and only one primary key. It is a good practice to add a primary key to every table. PostgreSQL creates a unique B-tree index on the column or a group of columns used to define the primary key.
CREATE TABLE po_headers (
po_no SERIAL PRIMARY KEY,
vendor_no INTEGER,
description TEXT,
shipping_address TEXT
);
Removing Primary Key
ALTER TABLE table_name DROP CONSTRAINT primary_key_constraint;
To remove the primary key from the table
ALTER TABLE products
DROP CONSTRAINT products_pkey;
Foreign Key
A foreign key is a column or a group of columns in a table that reference the primary key of another table.
In PostgreSQL, you define a foreign key using the foreign key constraint. The foreign key constraint helps maintain the referential integrity of data between the child and parent tables.
A foreign key constraint indicates that values in a column or a group of columns in the child table equal the values in a column or a group of columns of the parent table.
syntax
[CONSTRAINT fk_name]
FOREIGN KEY(fk_columns)
REFERENCES parent_table(parent_key_columns)
[ON DELETE delete_action]
[ON UPDATE update_action]
actions: SET NULL, SET DEFAULT, RESTRICT, NO ACTION, CASCADE
CREATE TABLE customers(
customer_id INT GENERATED ALWAYS AS IDENTITY,
customer_name VARCHAR(255) NOT NULL,
PRIMARY KEY(customer_id)
);
CREATE TABLE contacts(
contact_id INT GENERATED ALWAYS AS IDENTITY,
customer_id INT,
contact_name VARCHAR(255) NOT NULL,
phone VARCHAR(15),
email VARCHAR(100),
PRIMARY KEY(contact_id),
CONSTRAINT fk_customer
FOREIGN KEY(customer_id)
REFERENCES customers(customer_id)
);
- ON DELETE CASCADE automatically deletes all the referencing rows in the child table when the referenced rows in the parent table are deleted.
- The SET NULL automatically sets NULL to the foreign key columns in the referencing rows of the child table when the referenced rows in the parent table are deleted.
- The RESTRICT action is similar to the NO ACTION. PostgreSQL issues a constraint violation because the referencing rows
- The ON DELETE SET DEFAULT sets the default value to the foreign key column of the referencing rows in the child table when the referenced rows from the parent table are deleted.
ALTER TABLE child_table
ADD CONSTRAINT constraint_fk
FOREIGN KEY (fk_columns)
REFERENCES parent_table(parent_key_columns)
ON DELETE CASCADE;
Check Constraint
A CHECK constraint is a kind of constraint that allows you to specify if values in a column must meet a specific requirement. It uses a Boolean expression to evaluate the values before they are inserted or updated to the column.
If the values pass the check, PostgreSQL will insert or update these values to the column. Otherwise, PostgreSQL will reject the changes and issue a constraint violation error.
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
birth_date DATE CHECK (birth_date > '1900-01-01'),
joined_date DATE CHECK (joined_date > birth_date),
salary numeric CHECK(salary > 0)
);
To add CHECK constraints to existing tables, you use the ALTER TABLE statement.
CREATE TABLE prices_list (
id serial PRIMARY KEY,
product_id INT NOT NULL,
price NUMERIC NOT NULL,
discount NUMERIC NOT NULL,
valid_from DATE NOT NULL,
valid_to DATE NOT NULL
);
ALTER TABLE prices_list
ADD CONSTRAINT price_discount_check
CHECK (
price > 0
AND discount >= 0
AND price > discount
);
Unique Constraint
To ensure that values stored in a column or a group of columns are unique across the whole table such as email addresses or usernames.
PostgreSQL provides you with the UNIQUE constraint that maintains the uniqueness of the data correctly.
CREATE TABLE person (
id SERIAL PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Not-Null Constraint
In databases, NULL represents unknown or information missing. NULL is not the same as an empty string or the number zero.
CREATE TABLE invoices(
id SERIAL PRIMARY KEY,
product_id INT NOT NULL,
qty numeric NOT NULL CHECK(qty > 0),
net_price numeric CHECK(net_price > 0)
);
- Use the NOT NULL constraint for a column to enforce a column not accept NULL. By default, a column can hold NULL.
- To check if a value is NULL or not, you use the IS NULL operator. The IS NOT NULL negates the result of the IS NULL.
- Never use equal operator = to compare a value with NULL because it always returns NULL.
PostgreSQL Data Types
Boolean, Char, VarChar, and Text, Numeric, Integer, Serial, Date, Timestamp, Interval, Time, Uuid, Json, Hstore, Array, User-defined Data Types
Boolean
PostgreSQL supports a single Boolean data type: BOOLEAN that can have three values: true, false and NULL.
PostgreSQL uses one byte for storing a boolean value in the database. The BOOLEAN can be abbreviated as BOOL.
CREATE TABLE stock_availability (
product_id INT PRIMARY KEY,
available BOOLEAN NOT NULL
);
VarChar, Var, Text
PostgreSQL provides three primary character types: CHARACTER(n) or CHAR(n), CHARACTER VARYINGING(n) or VARCHAR(n), and TEXT, where n is a positive integer.
Advantage of specifying the length specifier for the VARCHAR data type is that PostgreSQL will issue an error if you attempt to insert a string that has more than n characters into the VARCHAR(n) column.
- PostgreSQL supports CHAR, VARCHAR, and TEXT data types. The CHAR is fixed-length character type while the VARCHAR and TEXT are varying length character types.
- Use VARCHAR(n) if you want to validate the length of the string (n) before inserting into or updating to a column.
- VARCHAR (without the length specifier) and TEXT are equivalent.
CREATE TABLE chemical_compounds (
id serial PRIMARY KEY,
first CHAR (7),
second VARCHAR (19),
third TEXT
);
Numeric Type
The NUMERIC type can store numbers with a lot of digits. Typically, you use the NUMERIC type for numbers that require exactness such as monetary amounts or quantities.
NUMERIC(precision, scale)
The precision is the total number of digits and the scale is the number of digits in the fraction part. For example, the number 8765.351 has the precision 7 and scale 3.
If precision is not required, you should not use the NUMERIC type because calculations on NUMERIC values are typically slower than integers, floats, and double precision.
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price NUMERIC(5,2)
);
Integer Data Types
To store the whole numbers in PostgreSQL, you use one of the following integer types: SMALLINT, INTEGER, and BIGINT.
SMALLINT type for storing something like ages of people, the number of pages of a book
INTEGER is the most common choice between integer types because it offers the best balance between storage size, range, and performance.
Using BIGINT type is not only consuming a lot of storage but also decreasing the performance of the database, therefore, you should have a good reason to use it.
CREATE TABLE cities (
city_id serial PRIMARY KEY,
city_name VARCHAR (255) NOT NULL,
population INT NOT NULL CHECK (population >= 0)
);
Date
To store date values, use the PostgreSQL DATE data type that uses 4 bytes to store a date value.
CREATE TABLE employees (
employee_id serial PRIMARY KEY,
first_name VARCHAR (255),
last_name VARCHAR (355),
birth_date DATE NOT NULL,
hire_date DATE NOT NULL
);
INSERT INTO employees (first_name, last_name, birth_date, hire_date)
VALUES ('Derrick','Kimani','1990-05-01','2015-06-01'),
('Florence','Wanjiru','1991-03-05','2013-04-01'),
('Richard','Chege','1992-09-01','2011-10-01');
To get the current date and time, use the built-in Now() function
SELECT NOW()::date;
SELECT CURRENT_DATE;
To get the year, quarter, month, week, day from a date value, you use the EXTRACT() function.
The following statement extracts the year, month, and day from the birth dates of employees:
SELECT
employee_id,
first_name,
last_name,
EXTRACT (YEAR FROM birth_date) AS YEAR,
EXTRACT (MONTH FROM birth_date) AS MONTH,
EXTRACT (DAY FROM birth_date) AS DAY
FROM
employees;
TimeStamp
The timestamp datatype allows you to store both date and time. However, it does not have any time zone data. It means that when you change the timezone of your database server, the timestamp value stored in the database will not change automatically.
The timestamptz datatype is the timestamp with the time zone. The timestamptz datatype is a time zone-aware date and time data type.
SELECT CURRENT_TIMESTAMP;
SELECT TIMEOFDAY();
Time
A time value may have a precision up to 6 digits. The precision specifies the number of fractional digits placed in the second field.
The TIME data type requires 8 bytes and its allowed range is from 00:00:00 to 24:00:00.
column_name TIME(precision);
CREATE TABLE shifts (
id serial PRIMARY KEY,
shift_name VARCHAR NOT NULL,
start_at TIME NOT NULL,
end_at TIME NOT NULL
);
SELECT LOCAL TIME;
SELECT CURRENT TIME;
To extracting hours, minutes, seconds from a time value, you use the EXTRACT function
SELECT
LOCALTIME,
EXTRACT (HOUR FROM LOCALTIME) as hour,
EXTRACT (MINUTE FROM LOCALTIME) as minute,
EXTRACT (SECOND FROM LOCALTIME) as second,
EXTRACT (milliseconds FROM LOCALTIME) as milliseconds;
UUID Data Type
UUID stands for Universal Unique Identifier defined by RFC 4122 and other related standards. A UUID value is 128-bit quantity generated by an algorithm that make it unique in the known universe using the same algorithm.
a UUID is a sequence of 32 digits of hexadecimal digits represented in groups separated by hyphens.
Because of its uniqueness feature, often found UUID in the distributed systems because it guarantees a better uniqueness than the SERIAL data type which generates only unique values within a single database. To store UUID values in the PostgreSQL database, you use the UUID data type.
To install the uuid-ossp module, you use the CREATE EXTENSION statement
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
If you want to generate a UUID value solely based on random numbers, use the uuid_generate_v4()
SELECT uuid_generate_v4();
Create a table whose primary key is UUID data type, the values of the primary key column will be generated automatically using the uuid_generate_v4() function.
CREATE TABLE contacts (
contact_id uuid DEFAULT uuid_generate_v4 (),
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
email VARCHAR NOT NULL,
phone VARCHAR,
PRIMARY KEY (contact_id)
);
INSERT INTO contacts (
first_name,
last_name,
email
)
VALUES
(
'Kamau',
'Kelvin',
'kamau.kelvin@example.com'
),
(
'Nafula',
'Wepkulu',
'nafula.wepkulu@example.com',
),
(
'Kasunda',
'Mutorini',
'kasunda.mutorini@example.com'
);
To query our database so that we view the uuid in the customer_id column.
SELECT
*
FROM
contacts;

Hstore data type
The hstore module implements the hstore data type for storing key-value pairs in a single value.
The hstore data type is very useful in many cases, such as semi-structured data or rows with many attributes that are rarely queried. Notice that keys and values are just text strings only.
To enable the hstore extension which loads the contrib module to your PostgreSQL instance.
CREATE EXTENSION hstore;
CREATE TABLE books (
id serial primary key,
title VARCHAR (255),
attr hstore
);
The data that we insert into the hstore column is a list of comma-separated key =>value pairs. Both keys and values are quoted using double quotes (“”).
PostgreSQL provides the hstore_to_json() function to convert hstore data to JSON.
SELECT
title,
hstore_to_json (attr) json
FROM
books;
JSON data type
JSON stands for JavaScript Object Notation. JSON is an open standard format that consists of key-value pairs, JSON is human-readable text.
The main usage of JSON is to transport data between a server and a web application.
The orders table consists of two columns:
The id column is the primary key column that identifies the order. The info column stores the data in the form of JSON.
CREATE TABLE orders (
id serial NOT NULL PRIMARY KEY,
info json NOT NULL
);
PostgreSQL provides two native operators -> and ->> to help you query JSON data.
The operator -> returns JSON object field by key.
The operator ->> returns JSON object field by text.
We can apply aggregate functions such as MIN, MAX, AVERAGE, SUM, etc., to JSON data. For example, the following statement returns minimum quantity, maximum quantity, average quantity and the total quantity of products sold.
SELECT
MIN (CAST (info -> 'items' ->> 'qty' AS INTEGER)),
MAX (CAST (info -> 'items' ->> 'qty' AS INTEGER)),
SUM (CAST (info -> 'items' ->> 'qty' AS INTEGER)),
AVG (CAST (info -> 'items' ->> 'qty' AS INTEGER))
FROM orders;
The json_each() function allows us to expand the outermost JSON object into a set of key-value pairs.
To get a set of keys in the outermost JSON object, you use the json_object_keys() function.
User-defined Data Types
Domain is a data type with optional constraints e.g., NOT NULL and CHECK. A domain has a unique name within the schema scope.
Domains are useful for centralizing the management of fields with common constraints.
The CREATE TYPE statement allows you to create a composite type, used as the return type of a function.
CREATE TYPE film_summary AS (
film_id INT,
title VARCHAR,
release_year SMALLINT
);
Use the film_summary data type as the return type of a function
CREATE OR REPLACE FUNCTION get_film_summary (f_id INT)
RETURNS film_summary AS
$$
SELECT
film_id,
title,
release_year
FROM
film
WHERE
film_id = f_id ;
$$
LANGUAGE SQL;
A user-defined function that returns a random number between two numbers low and high.
CREATE OR REPLACE FUNCTION random_between(low INT ,high INT)
RETURNS INT AS
$$
BEGIN
RETURN floor(random()* (high-low + 1) + low);
END;
$$ language 'plpgsql' STRICT;
SELECT random_between(1,100);
To get multiple random numbers between two integers, execute:
SELECT random_between(1, 100)
FROM generate_series(1, 4);
To list all user-defined types in the current database use the \dT or \dT+ command.
Conditional Expressions & Operators
CASE, COALESCE, NULLIF, CAST
CASE expression
The PostgreSQL CASE expression is the same as IF/ELSE statement in other programming languages. It allows you to add if-else logic to the query to form a powerful query.
General CASE expression
CASE
WHEN condition_1 THEN result_1
WHEN condition_2 THEN result_2
[WHEN ...]
[ELSE else_result]
END
SELECT
SUM (CASE
WHEN rental_rate = 0.99 THEN 1
ELSE 0
END
) AS "Economy",
SUM (
CASE
WHEN rental_rate = 2.99 THEN 1
ELSE 0
END
) AS "Mass",
SUM (
CASE
WHEN rental_rate = 4.99 THEN 1
ELSE 0
END
) AS "Premium"
FROM
film;

Coalesce
COALESCE function that returns the first non-null argument. The COALESCE function accepts an unlimited number of arguments. It returns the first argument that is not null. If all arguments are null, the COALESCE function will return null.
The COALESCE function evaluates arguments from left to right until it finds the first non-null argument. All the remaining arguments from the first non-null argument are not evaluated.
COALESCE (argument_1, argument_2,argument_3, ...);
CREATE TABLE items (
ID serial PRIMARY KEY,
product VARCHAR (100) NOT NULL,
price NUMERIC NOT NULL,
discount NUMERIC
);
Insert records into the item table
INSERT INTO items (product, price, discount)
VALUES
('Cassava', 1000 ,10),
('Yams', 1500 ,20),
('Arrow roots', 800 ,5),
('Potatoes', 500, NULL);
SELECT
product,
(price - COALESCE(discount,0)) AS net_price
FROM
items;
COALESCE function makes the query shorter and easier to read, it substitutes null values in the query.
NULLIF
To use PostgreSQL NULLIF function to handle null values.
NULLIF(argument_1, argument_2, argument_3);
Apply the NULLIF function to substitute the null values for displaying data and preventing division by zero error.
CAST operator
To convert a value of one data type into another. PostgreSQL provides you with the CAST operator that allows you to do this.
CAST ( expression AS target_type );
Specify an expression that can be a constant, a table column, an expression that evaluates to a value. Then the target data type to which you want to convert the result of the expression.
PostgreSQL type cast :: operator
expression::type
Cast a string to a double
SELECT
CAST ('10.2' AS DOUBLE PRECISION);
Cast a string to a date
SELECT
CAST ('2015-01-01' AS DATE),
CAST ('01-OCT-2015' AS DATE);
Cast operator to convert a string to an interval
SELECT '15 minute'::interval,
'2 hour'::interval,
'1 day'::interval,
'2 week'::interval,
'3 month'::interval;
Explain
The EXPLAIN statement returns the execution plan which PostgreSQL planner generates for a given statement.
The EXPLAIN shows how tables involved in a statement will be scanned by index scan or sequential scan, etc., and if multiple tables are used, what kind of join algorithm will be used.
EXPLAIN [ ( option [, ...] ) ] sql_statement;
Option can be :
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
BUFFERS [ boolean ]
TIMING [ boolean ]
SUMMARY [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
Boolean specifies whether the selected option should be turned on or off. You can use TRUE, ON, or 1 to enable the option, and FALSE, OFF, or 0 to disable it.
The ANALYZE option causes the sql_statement to be executed first and then actual run-time statistics in the returned information including total elapsed time expended within each plan node and the number of rows it actually returned.
TIMING includes the actual startup time and time spent in each node in the output.It defaults to TRUE and it may only be used when ANALYZE is enabled.
COSTS option includes the estimated startup and total costs of each plan node, as well as the estimated number of rows and the estimated width of each row in the query plan. The COSTS defaults to TRUE.
BUFFERS only can be used when ANALYZE is enabled. By default, the BUFFERS parameter set to FALSE
VERBOSE parameter allows you to show additional information regarding the plan. This parameter sets to FALSE by default.
SUMMARY parameter adds summary information such as total timing after the query plan. Note that when ANALYZE option is used, the summary information is included by default.
The output format of the query plan such as TEXT, XML, JSON, and YAML. This parameter is set to TEXT by default.
Explain statement that calculates the query plan.
EXPLAIN ANALYZE
SELECT
f.film_id,
title,
name category_name
FROM
film f
INNER JOIN film_category fc
ON fc.film_id = f.film_id
INNER JOIN category c
ON c.category_id = fc.category_id
ORDER BY
title;

Indeed we have covered the basics of SQL using PostgreSQl in detail. You need to practice what you have learnt using a sample database, so as to understand the concepts well. Our goal should be to write complex readable queries with fast execution rate. The next SQL article will cover the advanced topics in SQL such as Indexes, Views, Stored Procedures.

Feel free to share your thoughts in the comments.




Top comments (2)
Good inofrmation share buddy! It is new information for me! Get your love back by dua
Good to hear you found the article useful