
This is an updated post of a previous post from 2022 about how you can use dive to inspect the contents of an image.
In Docker layer caching for GitHub Actions, we covered using the existing layer cache is fundamental to speeding up Docker image builds. The less work we have to redo across builds, the faster our builds will be.
But, leveraging the cache is only one part of the equation for making docker build as fast as possible.
Another part of the equation is reducing the overall image size to improve build time. This post will look at reducing the overall image size to improve build time and the other benefits of keeping images small. We will use a popular open-source project, dive, to help analyze a Docker image, stepping through each individual layer to see what files it adds to the image and how it impacts the total image size.
Our example Docker image
We will use an example Node project with an ordinary Dockerfile someone may write when getting started. It has the following directory structure:
.
├── Dockerfile
├── README.md
├── dist
│ ├── somefile1.d.ts.map
│ ├── somefile1.js
├── node_modules
├── package.json
├── src
│ ├── index.ts
├── tsconfig.json
├── yarn-error.log
└── yarn.lock
There is a src folder, a node_modules folder, a package.json file, a Dockerfile file, and a dist folder that contains the build output of yarn build. Here is an unoptimized Dockerfile for this project that we may write.
FROM node:16
WORKDIR /app
COPY . .
RUN yarn install --immutable
RUN yarn build
CMD ["node", "./dist/index.js"]
This isn't an uncommon Dockerfile that we typically see in the wild. But if we build the image and then check its final size using the following commands:
docker build -t example-image .
docker inspect example-image -f "{{ .Size }}" | numfmt --to si --format "%1.3f"
1.5G
We see that the image size is 1.5 GB. That seems quite large for this example Node application and our Dockerfile above.
Using dive to see what is in our Docker image
The open-source project dive is an excellent tool for analyzing a Docker image. It allows us to view each layer of an image, including the layer size and what files are inside.
We can use dive on the example-image we just built:
dive example-image
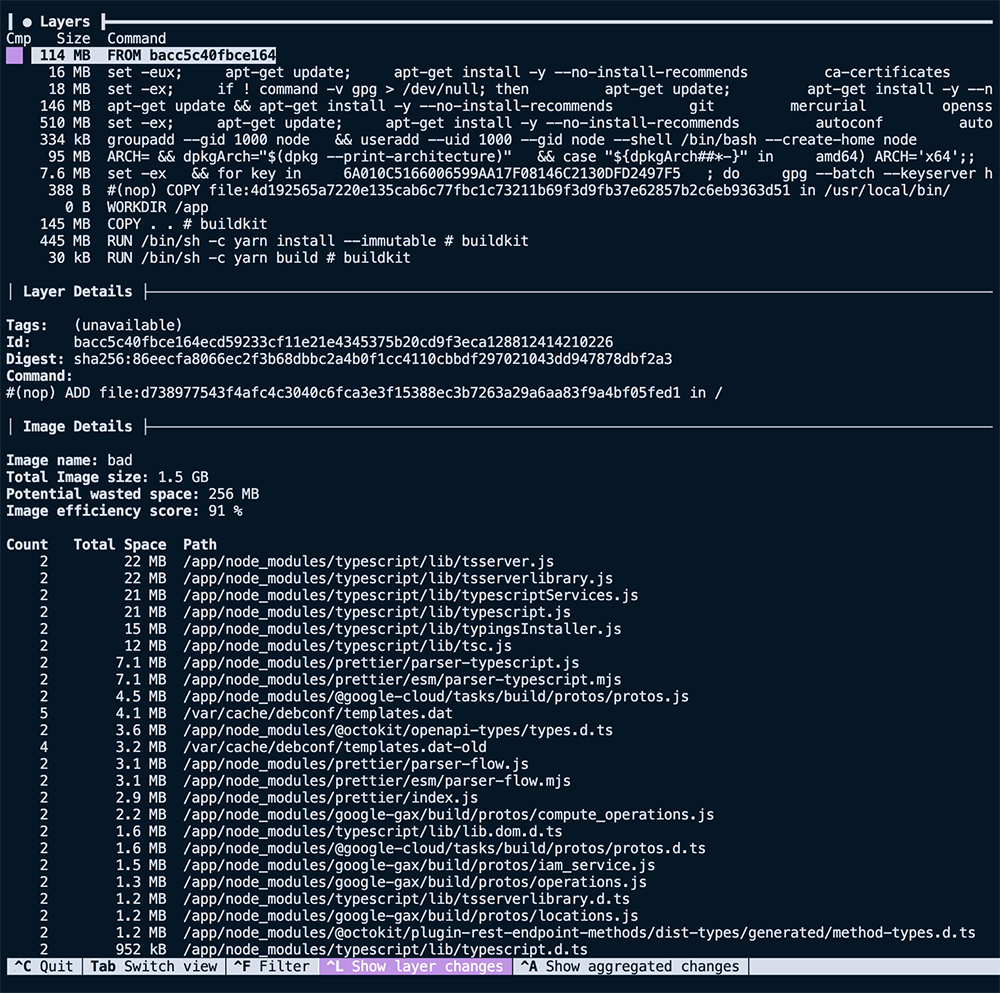
As seen above, the terminal UI of dive shows us the layers that make up the image on the left-hand side.
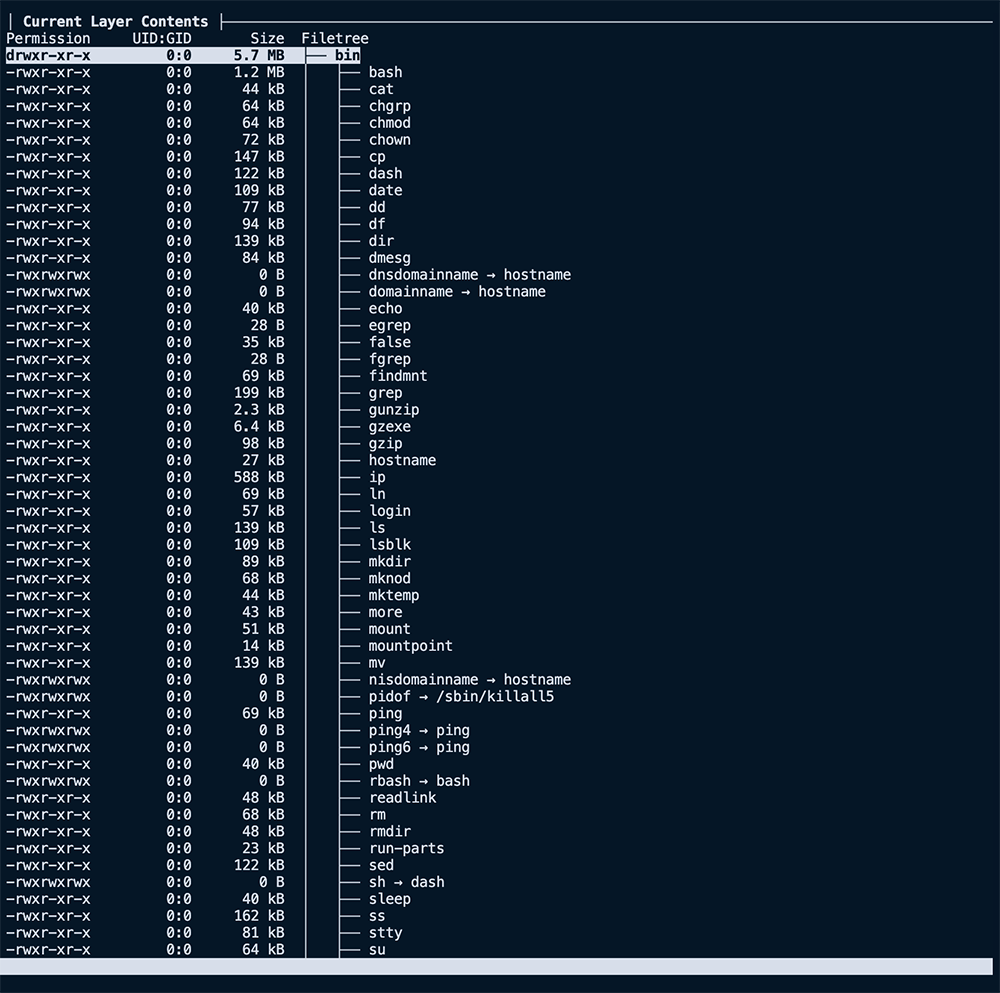
The right side, as seen here, shows us the filesystem of the selected layer. It shows what files were added, removed, or modified between the layer selected and the parent before it.
Our first image above shows that the first nine layers are all related to the base image, FROM node:16, for a summed size of ~910 GB. That's large but not surprising, considering we use the node:16 image as our base.
The next interesting layer is the eleventh one, where we COPY . ., it has a total size of 145 MB. Considering the project we are building, it is much larger than expected. Using the filesystem pane of dive, we can see the files added to that layer via that command.
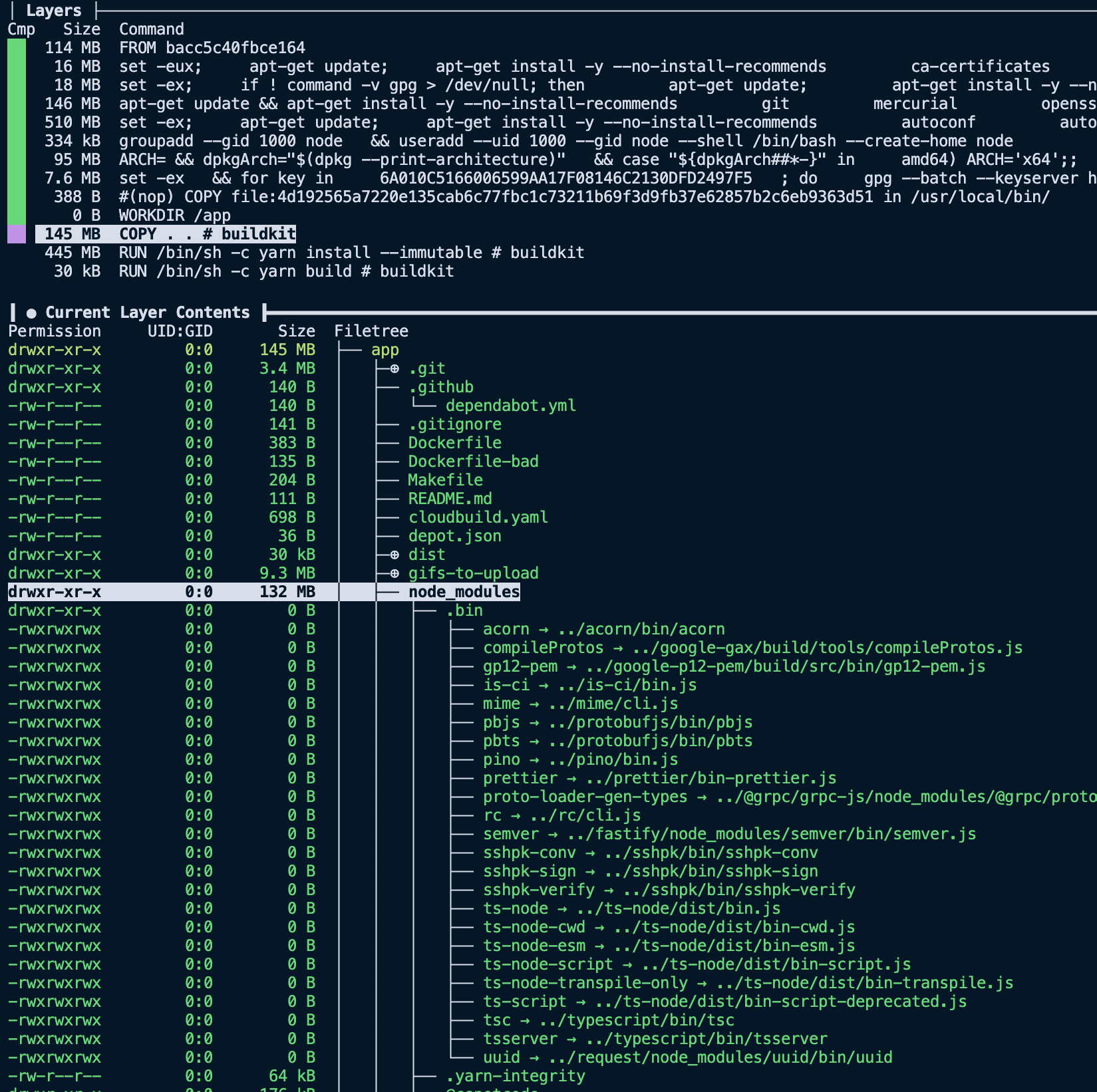
Now things get a little more compelling. Analyzing the layer, we can see it contains our entire project directory, including directories like dist and node_modules that we recreate with future RUN steps. So now that we have spotted the first problem with our image size, we can start implementing solutions to slim it down.
Reducing image size
Now that we have insights into what is in our image via dive, we can reduce the final Docker image size using three different techniques.
- Add a
.dockerignorefile to our project to exclude unnecessary files or directories - Change our
Dockerfileto use smaller base images. - Use multi-stage builds to exclude unnecessary artifacts from earlier stages in the final image
Add a .dockerignore file
A .dockerignore file instructs Docker to skip files or directories during docker build. Files or directories that match in .dockerignore won't be copied with any ADD or COPY statements. As a result, they never appear in the final built image.
The .dockerignore syntax is similar to a .gitignore file. We can add a .dockerignore file to the root of our project that ignores all the unneeded files for our example image build.
node_modules
Dockerfile*
.git
.github
.gitignore
dist/**
README.md
Here we exclude files that are recreated as part of our Dockerfile, like node_modules are installed via the RUN yarn install --immutable step. We also exclude unnecessary folders like .git and dist, the RUN yarn build output.
With this small change, we can rebuild our image and recheck its size.
docker build -t example-image .
docker inspect example-image -f "{{ .Size }}" | numfmt --to si --format "%1.3f"
1.3G
The size is now 1.3 GB instead of 1.5 GB, so we have already shaved off 200 MB from our image size!
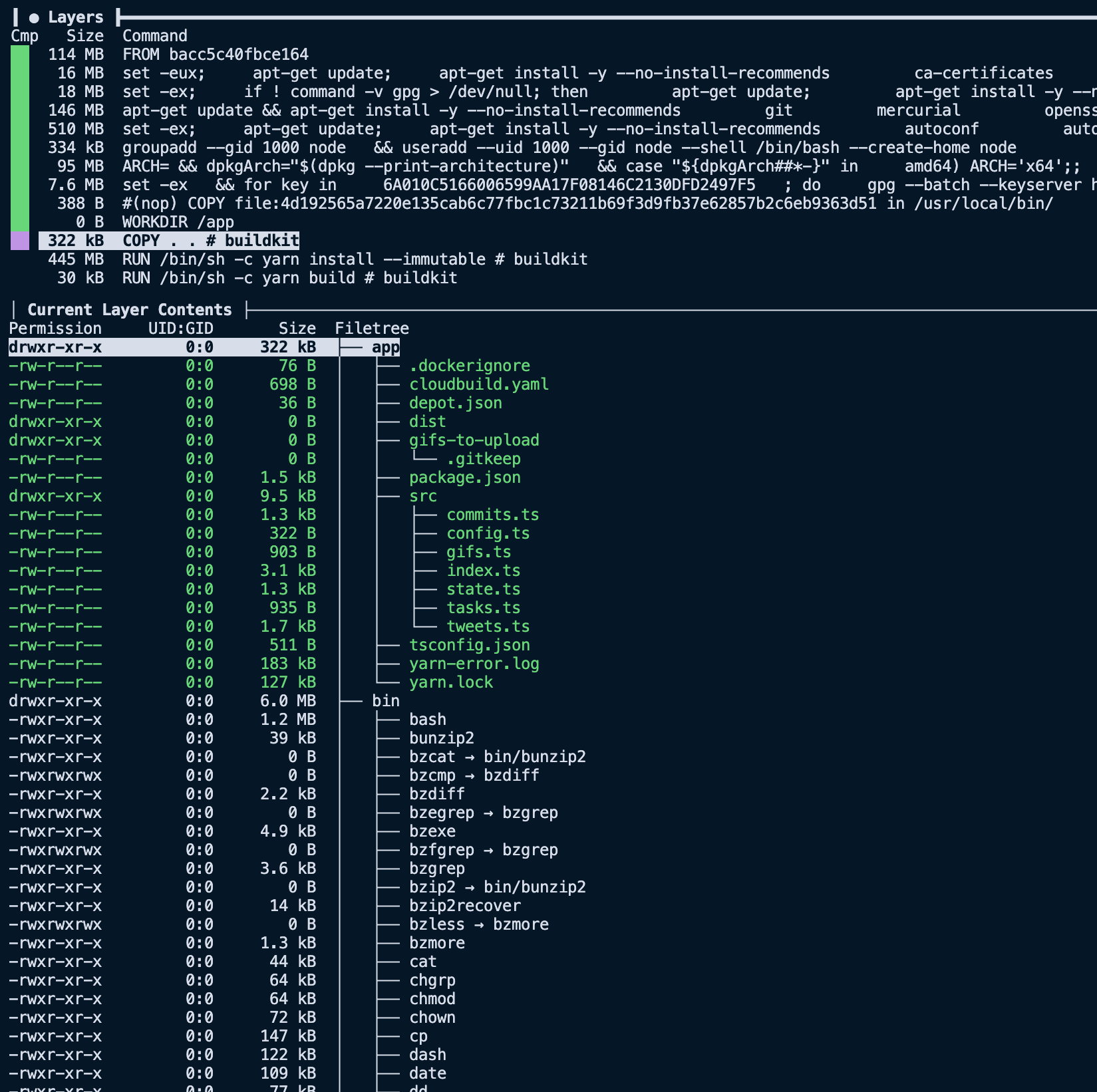
Looking at the COPY layer via dive again, we see that we removed the node_modules folder and other file paths from our .dockerignore. Bringing the layer size down from 145 MB to less than 400 KB.
Shave lots of bytes with smaller base images
Slim base images can provide dramatic reductions in image size. But they do come with tradeoffs that are worth considering. For example, as we will see, the alpine base image provides a massive size reduction, but it comes with its own and more limited package manager, apk. However, for most use cases, this limitation is manageable and can often be worked around.
For our example, we don't mind the tradeoffs presented for the node:16-alpine base image, so we can plug it into our Dockerfile and run a new build.
- FROM node:16
+ FROM node:16-alpine
...
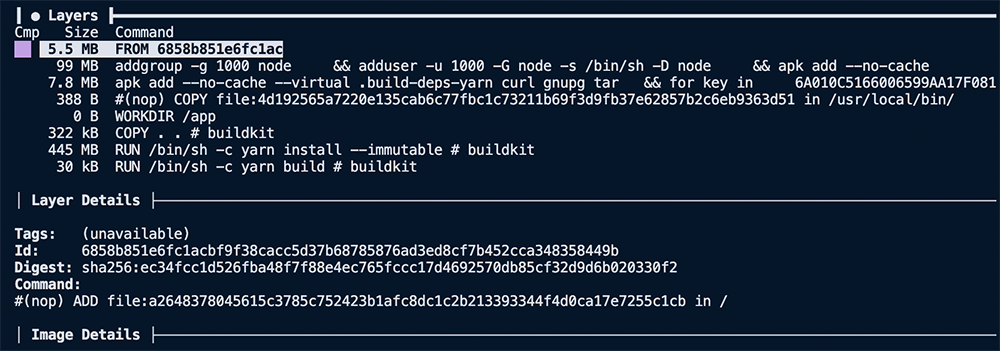
Changing the base image to alpine brings the number of base layers down from nine to five. Reducing the total image size of 1.3 GB down to 557 MB, nearly 3x smaller than the original 1.5 GB image.
Leverage multi-stage builds
A multi-stage build allows you to specify multiple FROM statements in a single Dockerfile, and each of them represents a new stage in a build. You can also copy files from one stage to another. Files not copied from an earlier stage are discarded in the final image, resulting in a smaller size.
Here is what our example Dockerfile looks like with an optimized multi-stage build.
FROM node:16-alpine AS build
WORKDIR /app
COPY package.json yarn.lock tsconfig.json ./
RUN yarn install --immutable
COPY src/ ./src/
RUN yarn build
FROM node:16-alpine
WORKDIR /app
COPY --from=build /app/node_modules /app/node_modules
COPY --from=build /app/dist /app/dist
CMD ["node", "./dist/index.js"]
The first stage copies in the package.json, yarn.lock, and tsconfig.json files so that node_modules can be installed and the application can be built.
The second stage copies the node_modules and dist folders from the first stage, build, into the final image. The items not copied from the first stage get discarded. We no longer have a COPY . . step either; instead, we only copy in the node_modules and the build output of our project, the dist folder.
If we build this example with a multi-stage build, we can bring the total image size down to 315 MB. That's a 4x reduction in image size from the original 1.5 GB.
The benefits of reducing Docker image size
Smaller images build and deploy faster. But speed is one of many benefits of keeping your container images small. The smaller the image is, the less complex it is as well. The less complex an image is the fewer binaries and packages inside it and, by extension, the fewer pathways for vulnerabilities to exist.
Using the three techniques we covered in this post and dive to analyze the contents of our images, we can drastically reduce the size of Docker images so that they build and run faster. But we also make them less complex, more accessible to reason about, and more secure.
Faster Docker image builds with Depot
Optimize your Docker image build process with Depot. Companies like PostHog use it to reduce build time by over 17 hours daily. We achieve this by launching remote builders for native Intel and Arm with persistent caching that's immediately available across builds—no more slow emulation or saving of layer cache over networks. Try Depot for yourself with our 60-minute free tier and experience the time-saving benefits of our cutting-edge technology. Sign up now to get started.





Top comments (4)
Excellent post!
Really well explained with all the steps it really easy to understand
Use a smaller base image: When creating your Dockerfile, use a smaller base image. For instance, think about utilising a lightweight image like Alpine Linux rather than a full-featured Linux distribution like Ubuntu or CentOS.
Remove unused folders and files: Clean up your Docker image of any unused directories and files. This includes any temporary files that are not required during runtime, such as log files and package caches.
Make use of multi-stage builds: To make your final Docker image smaller, make use of multi-stage builds. With multi-stage builds, you can create your programme on one image, then copy just the files you need to the smaller final image.
Helpful post. Thanks for sharing it.
Good post. One thing you might want to consider is not copying the node modules to the second container.