
Data Science is about learning. I don’t mean supervised learning, unsupervised learning, reinforcement learning or transfer learning ! I mean LEARNING ! From books. From code. From your colleagues and friends. From stackoverflow ! You are constantly learning and improving your skill set. New models and breakthroughs are being announced at a faster rate than ever. As data scientists, you need to be aware of what is going on in this field and stay on top of the latest developments. IBM has a few open source projects that I want to write about that will help you keep up to date. We will look MAX or Model Asset Exchange in this post.

MAX is a repository of open source Machine Learning and Deep Learning models developed by my colleagues and friends at IBM. They include topics ranging from object recognition, pose detector, audio analysis and age estimator. The team puts out a new model every now and then. So what’s the big deal ?
You can clone, fork, improve upon, provide feedback and learn from these models ! You LEARN ! You learn how to make one yourself and make it usable ! You learn why it works well. You learn why some it does not work well and more importantly why it does not work with certain inputs.
My dear friend and colleague Patrick Titzler gave a talk in San Francisco recently on MAX and showed us how to use Node-RED to quickly test some of these models. I met Ayush at the same meetup. Ayush is using two models from MAX to facilitate his everyday hobby — photography. I will save that for another post later. Let’s look at my favorite MAX models …
Object Detector
This model recognizes the objects present in an image from the 80 different high-level classes of objects in the COCO Dataset. This problem has been solved for most part and if the framework/platform you are using does not do well with the default results, try creating a custom classifier (insert url) with Watson Visual Recognition. As an example, I gave the leading visual recognition APIs an image of Raspberry Pi and they mostly came back with “computer chip”, “mother board” or “electronic”. Those are all amazing results, but I wanted more. I was able to train a custom classifier using Watson to tell me with high confidence if the picture was “Raspberry Pi Model A” or “Raspberry Pi Model B” 😳. Pretty cool stuff ! You can read about the customer classifier in this medium post. That being said, this open source model still makes for a great learning resource. You can also try these patterns in Node-RED, more coming on this option in the next post ! Pretty cool that it got the bicycle just with what was visible in the picture ! The bicycle is hanging upside down in my room 🆒 !

Facial Age Estimator
This model detects faces in an image, extracts facial features for each face detected and finally predicts the age of each face.
This is my favorite by far because it gets me younger every time :). At first, I was quite annoyed that IBM would put out a model that did not do as well as I expected it to. Sometimes I shave and other times I have a stubble. It gives me a different result in day light vs inside a dimly lit conference hall. But then I realized that these are all learning opportunities for me. Questions that we need to ask of each model. I started looking at the training data and quickly realized that unless I am in Hollywood and have five lbs of makeup on, it wont be able to guess my age. The training data is IMDB imageset that you can find here. We will look at this dataset closely in an upcoming blog post.
IMDB-WIKI - 500k+ face images with age and gender labels
We Now have an IBM code pattern that will help you create a web application that uses this model ! These world leaders are awfully young !

It does fairly well with my image, only off by two … I will let you guess in which direction.

Image Caption Generator
This is the model Ayush was using to generate captions for his Instagram account. By the way, you can follow him here: https://www.instagram.com/throughshutter
This model generates captions from a fixed vocabulary that describe the contents of images in the COCO Dataset. Even though the training dataset is limited (80 object categories), it does pretty well. Here is an example
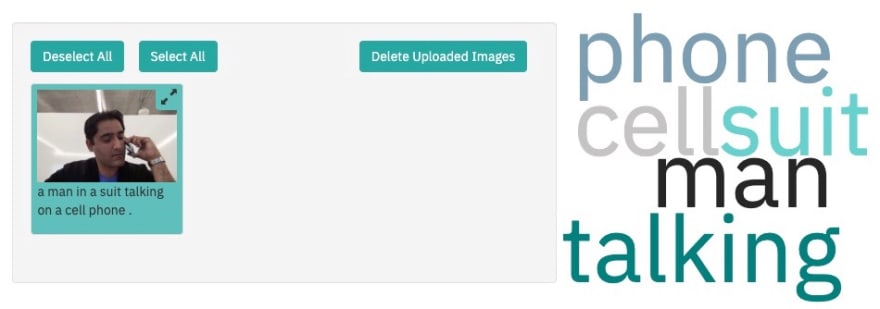
A man in a suit talking on a cell phone
The caption says a man in a suit talking on a cell phone. That is not bad at all ! There are plenty of other models you can try on MAX. But let’s look at how you can use Node-RED to quickly test a few of these. The MAX team has created some assets to help us out. If you have never used Node-RED before, get ready to fall in love 💕.
Audio Classifier
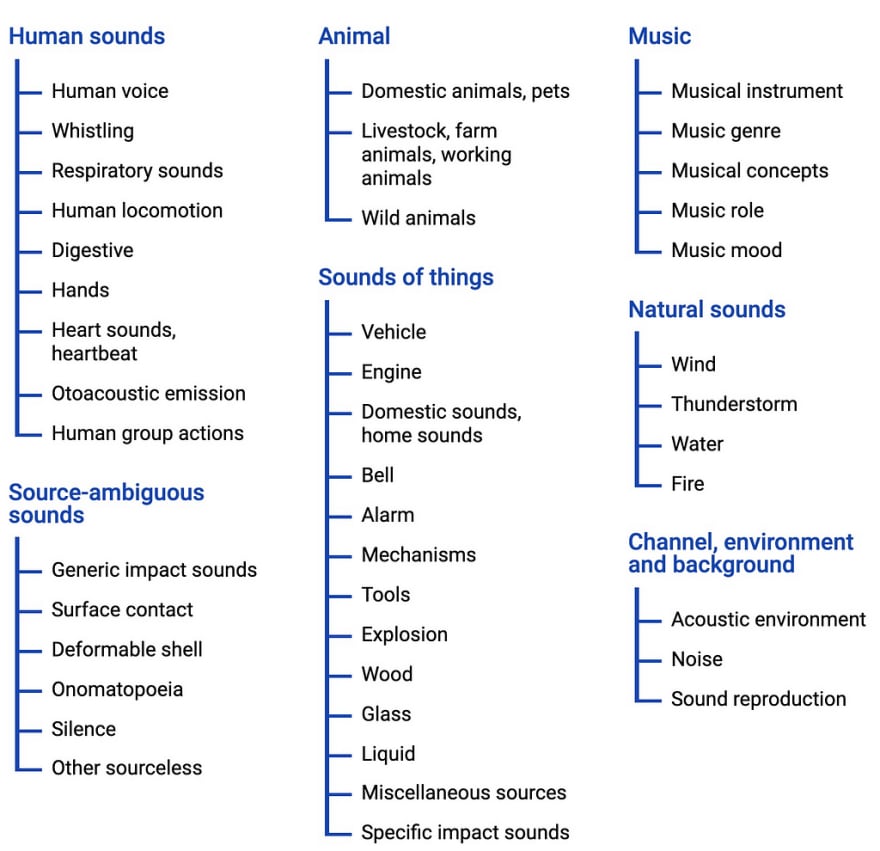
This one is so much fun. This model recognizes a signed 16-bit PCM wav file as an input, generates embeddings, applies PCA transformation/quantization, uses the embeddings as an input to a multi-attention classifier and outputs top 5 class predictions and probabilities as output. WHAT 🤯 !! Basically, it identifies sounds and noise. The data is coming from AudioSet. I am building some cool demos and games to use this model. Stay tuned !
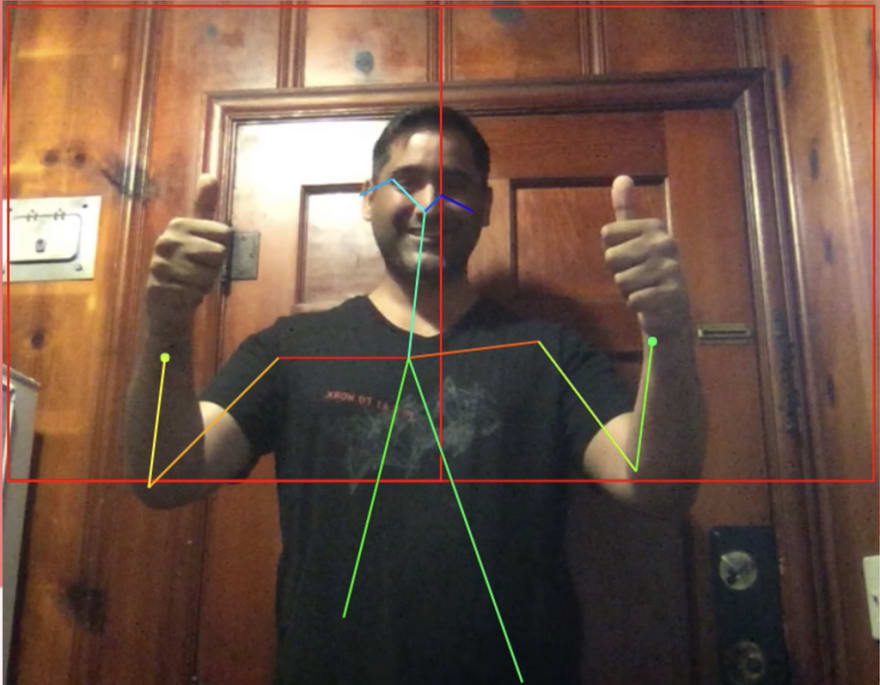
Human Pose Estimator
I had a lot of fun with this one at a recent data science workshop ! This model detects humans and their poses in a given image. The model first detects the humans in the input image and then identifies the body parts, including nose, neck, eyes, shoulders, elbows, wrists, hips, knees, and ankles. Next, each pair of associated body parts is connected by a pose line.
Those are some of my favorite models. There are lots more in the Model Asset Exchange. Give them a try and let me know which ones you like ! I have some more posts coming up on how to use/deploy some of these models.
Max Katz, sorry for the confusion in advance :). I will write a separate post to introduce you ! Patrick Titzler, thank you for the wonderful meetup ! Gabriela de Queiroz and Simon, thank you for demoing MAX at the IBM AI-ML Summit in San Francisco.




Top comments (0)