
This is the third post in a series about building a podcast application using GRANDstack. Check out the first post, "Podcast Search GraphQL API With Neo4j And The Podcast Index" where we start building the GraphQL API and implement podcast search functionality and the second post, "GRANDcast.FM: User Auth & Podcast Subscribe Functionality"
In this post, we continue building out functionality in the GraphQL API powering our podcast application. This week we focus on adding episodes by parsing podcast XML feeds and adding user playlists to the GraphQL API. We added this functionality during the Neo4j livestream. You can watch the recording of that here:
Working With Podcast Feeds
A podcast feed is an XML document that conforms to the RSS 2.0 specification. The basic structure of an RSS document consists of a top-level <rss> element, followed by a <channel> element which contains metadata about the podcast (title, description, link, etc). We already have this data for each podcast that a user has subscribed to, fetched from the Podcast Index API and added to the database. What we're interested in is the next sub-element of the document, <items>, which consists of one or more <item> elements.
Each <item> element represents a podcast episode and contains the following elements (technically these are all optional according to the specification, and other elements may be included as well):
-
<title>- The title of the podcast episode -
<link>- The URL of the podcast episode (not to be confused with the audio file URL) -
<description>- A synopsis of the episode -
<enclosure>- A media object (such as an audio file) attached to the episode -
<guid>- A globally unique string used to identify the episode -
<pubDate>- Indicates when the episode was published, using RFC822 datetime format.
Now that we know the structure of a podcast feed XML document, let's start parsing them and adding episodes to the database.
Parsing XML With Neo4j
We can parse and import XML data directly into Neo4j using the apoc.load.xml procedure. This procedure takes the URL for the XML file and returns a single nested map representing the XML document using _type, _text, and _children keys to represent values, metadata, and element type as represented in XML. The APOC documentation has a simple example showing how this works. Here we use Cypher to filter for the elements of each episode that we want to capture, using the Graphistania podcast as an example:
MATCH (p:Podcast)
CALL apoc.load.xml("http://feeds.soundcloud.com/users/soundcloud:users:141739624/sounds.rss")
YIELD value
WITH [x in value._children[0]._children WHERE x._type = "item"] AS episodes
UNWIND episodes AS episode
WITH
[X in episode._children WHERE X._type = "title"][0]._text AS title,
[X in episode._children WHERE X._type = "summary"][0]._text AS summary,
[X in episode._children WHERE X._type = "link"][0]._text AS link,
[X in episode._children WHERE X._type = "image"][0].href AS image,
[X in episode._children WHERE X._type = "enclosure" AND X.type CONTAINS "audio"][0].url AS audio,
[X in episode._children WHERE X._type = "pubDate"][0]._text AS pubDate,
[X in episode._children WHERE X._type ="guid"][0]._text AS guid
RETURN *
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════╤══════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤═════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╕
│"audio" │"guid" │"image" │"link" │"pubDate" │"summary" │"title" │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════╪══════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪═════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╡
│"http://www.podtrac.com/pts/redirect.mp3/feeds.soundcloud.com/stream/9│"tag:soundcloud,2010:tracks/935068060"│"http://i1.sndcdn.com/avatars-000135096101-qekfg1-original.png" │"https://soundcloud.com/graphistania/graphistania-20-episode-11" │"Tue, 24 Nov 2020 00:00:00 +0000"│"Graphistania 2.0 - Episode 11 by The Neo4j Graph Database Community" │"Graphistania 2.0 - Episode 11" │
│35068060-graphistania-graphistania-20-episode-11.mp3" │ │ │ │ │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┤
│"http://www.podtrac.com/pts/redirect.mp3/feeds.soundcloud.com/stream/9│"tag:soundcloud,2010:tracks/926771035"│"http://i1.sndcdn.com/avatars-000135096101-qekfg1-original.png" │"https://soundcloud.com/graphistania/graphistania-20-episode-10" │"Thu, 12 Nov 2020 08:08:48 +0000"│"Graphistania 2.0 - Episode 10 by The Neo4j Graph Database Community" │"Graphistania 2.0 - Episode 10" │
│26771035-graphistania-graphistania-20-episode-10.mp3" │ │ │ │ │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┤
│"http://www.podtrac.com/pts/redirect.mp3/feeds.soundcloud.com/stream/9│"tag:soundcloud,2010:tracks/905615800"│"http://i1.sndcdn.com/avatars-000135096101-qekfg1-original.png" │"https://soundcloud.com/graphistania/graphistania-20-episode-9" │"Tue, 06 Oct 2020 00:00:00 +0000"│"Graphistania 2.0 - Episode 9 by The Neo4j Graph Database Community" │"Graphistania 2.0 - Episode 9" │
│05615800-graphistania-graphistania-20-episode-9.mp3" │ │ │ │ │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┤
│"http://www.podtrac.com/pts/redirect.mp3/feeds.soundcloud.com/stream/8│"tag:soundcloud,2010:tracks/889154860"│"http://i1.sndcdn.com/avatars-000135096101-qekfg1-original.png" │"https://soundcloud.com/graphistania/graphistania-20-episode-8" │"Tue, 08 Sep 2020 00:00:00 +0000"│"Graphistania 2.0 - Episode 8 by The Neo4j Graph Database Community" │"Graphistania 2.0 - Episode 8" │
│89154860-graphistania-graphistania-20-episode-8.mp3" │ │ │ │ │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┤
│"http://www.podtrac.com/pts/redirect.mp3/feeds.soundcloud.com/stream/8│"tag:soundcloud,2010:tracks/853044658"│"http://i1.sndcdn.com/avatars-000135096101-qekfg1-original.png" │"https://soundcloud.com/graphistania/graphistania-20-episode-7" │"Fri, 10 Jul 2020 00:00:00 +0000"│"Graphistania 2.0 - episode 7 by The Neo4j Graph Database Community" │"Graphistania 2.0 - episode 7" │
│53044658-graphistania-graphistania-20-episode-7.mp3" │ │ │ │ │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┤
│"http://www.podtrac.com/pts/redirect.mp3/feeds.soundcloud.com/stream/7│"tag:soundcloud,2010:tracks/791209915"│"http://i1.sndcdn.com/avatars-000135096101-qekfg1-original.png" │"https://soundcloud.com/graphistania/graphistania-20-episode-6" │"Mon, 06 Apr 2020 00:00:00 +0000"│"Graphistania 2.0 - episode 6 by The Neo4j Graph Database Community" │"Graphistania 2.0 - episode 6" │
│91209915-graphistania-graphistania-20-episode-6.mp3" │ │ │ │ │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────┼──────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼─────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┤
Now that we can parse each podcast feed we're ready to add these episodes to the database.
Adding Podcast Episodes To The Graph
We'll use the apoc.load.xml procedure to parse the podcast feeds for any podcasts currently stored in the database and create Episode nodes in the graph with the relevant details for each episode stored as node properties. We'll connect the episode to its podcast using a HAS_EPISODE relationship.

Here we create an Episode node for each podcast episode parsed from the feed. Note how we make use of the apoc.date.parse function when storing the pubDate property as a datetime type.
MATCH (p:Podcast)
call apoc.load.xml(p.feedURL)
YIELD value
UNWIND value._children AS foo
WITH p, [x in foo._children WHERE x._type = "item"] AS episodes
UNWIND episodes AS episode
WITH p,
[X in episode._children WHERE X._type = "title"][0]._text AS title,
[X in episode._children WHERE X._type = "summary"][0]._text AS summary,
[X in episode._children WHERE X._type = "link"][0]._text AS link,
[X in episode._children WHERE X._type = "image"][0].href AS image,
[X in episode._children WHERE X._type = "enclosure" AND X.type CONTAINS "audio"][0].url AS audio,
[X in episode._children WHERE X._type = "pubDate"][0]._text AS pubDate,
[X in episode._children WHERE X._type ="guid"][0]._text AS guid
MERGE (e:Episode {id: guid})
SET e.title = title,
e.summary = summary,
e.link = link,
e.image = image,
e.audio = audio,
e.pubDate = datetime({epochMillis: apoc.date.parse(pubDate, "ms", "EEE, dd MMM yyyy HH:mm:ss z")})
MERGE (e)<-[:HAS_EPISODE]-(p)
Adding Episodes When A User Subscribes To A Podcast
Now that we have the Cypher statement to parse podcast feeds and insert episodes into the database we need to update our GraphQL API so that when a podcast is added to the database we start parsing the feed. There are a few different ways we could approach this, perhaps creating a database trigger or a background job to parse the feed. Instead of those options let's update the subscribeToPodcast GraphQL mutation to include the Cypher for parsing the podcast feed and adding episodes to the graph when a user subscribes to the podcast. To do that we'll add the above Cypher statement to the subscribeToPodcast mutation @cypher statement:
type Mutation {
signup(username: String!, password: String!): AuthToken
login(username: String!, password: String!): AuthToken
subscribeToPodcast(itunesId: String!): Podcast
@cypher(
statement: """
// First we fetch the podcast details from the podcast index
WITH toString(timestamp()/1000) AS timestamp
WITH {
`User-Agent`: 'GRANDstackFM',
`X-Auth-Date`: timestamp,
`X-Auth-Key`: apoc.static.get('podcastkey'),
`Authorization`: apoc.util.sha1([apoc.static.get('podcastkey')+apoc.static.get('podcastsecret') +timestamp])
} AS headers
CALL apoc.load.jsonParams('https://api.podcastindex.org/api/1.0/podcasts/byitunesid?id=' + apoc.text.urlencode($itunesId), headers, '', '') YIELD value
WITH value.feed AS feed
// Next we create the (:User)-[:SUBSCRIBES_TO]->(:Podcast) path in the database
MATCH (u:User {id: $cypherParams.userId})
MERGE (p:Podcast {itunesId: $itunesId})
SET p.title = feed.title,
p.link = feed.link,
p.description = feed.description,
p.feedURL = feed.url,
p.image = feed.artwork
MERGE (u)-[:SUBSCRIBES_TO]->(p)
WITH p
// Now we parse the podcast XML feed and add its episodes to the database
// (:Podcast)-[:HAS_EPISODE]->(:Episode)
CALL apoc.load.xml(p.feedURL) YIELD value
UNWIND value._children AS foo
WITH p,[x in foo._children WHERE x._type = \"item\"] AS episodes
UNWIND episodes AS episode
WITH p,[x in episode._children WHERE x._type =\"title\"][0]._text AS title,
[x in episode._children WHERE x._type =\"description\"][0]._text AS summary,
[x in episode._children WHERE x._type=\"link\"][0]._text AS link,
[x in episode._children WHERE x._type=\"image\"][0].href AS image,
[x in episode._children WHERE x._type=\"enclosure\" AND x.type CONTAINS \"audio\" ][0].url AS audio,
[x in episode._children WHERE x._type=\"pubDate\"][0]._text AS pubDate,
[x in episode._children WHERE x._type =\"guid\"][0]._text AS guid
MERGE (e:Episode {id: guid})
SET e.title = title,
e.summary = summary,
e.link = link,
e.image = image,
e.audio = audio,
e.pubDate = dateTime({epochMillis: apoc.date.parse(pubDate, 'ms', 'EEE, dd MMM yyyy HH:mm:ss zzz')})
MERGE (e)<-[:HAS_EPISODE]-(p)
RETURN p
"""
)
}
We'll also want to add the Episode type definition to our GraphQL API:
type Episode {
id: ID!
pubDate: DateTime
summary: String
title: String
link: String
image: String
audio: String
podcast: Podcast @relation(name: "HAS_EPISODE", direction: "IN")
}
User Podcast Feed
A typical flow for our application will be:
- Show the user a feed of episodes for all the podcasts to which they subscribe, most recent first
- The user adds episodes they want to listen to to a playlist
- When the user is ready to listen they can view all episodes assigned to each playlist
Let's add a GraphQL query field to show all episodes for each podcast a user subscribes to, showing the most recent episodes first. We'll use the cypherParams.userId value, which will identify the currently authenticated user, to look up that user in the database, traverse to all podcasts they subscribe to, and then traverse to each episode for their subscribed podcasts. Refer to the previous post in this series for details about the cypherParams.userId value and how that is parsed from the auth token.
type Query {
episodeFeed(first: Int = 10, offset: Int = 0): [Episode]
@cypher(
statement: """
MATCH (u:User {id: $cypherParams.userId})-[:SUBSCRIBES_TO]->(p:Podcast)-[:HAS_EPISODE]->(e:Episode)
RETURN e ORDER BY e.pubDate DESC SKIP toInteger($offset) LIMIT toInteger($first)
"""
)
}
First, we'll log in using the username and password we created previously:

This gives us the auth token that when added to the request header will allow us to make authenticated GraphQL requests to the API. Now, let's make an authenticated request to query for our user's podcast episode feed, showing the most recent episodes across all the podcasts I subscribe to:
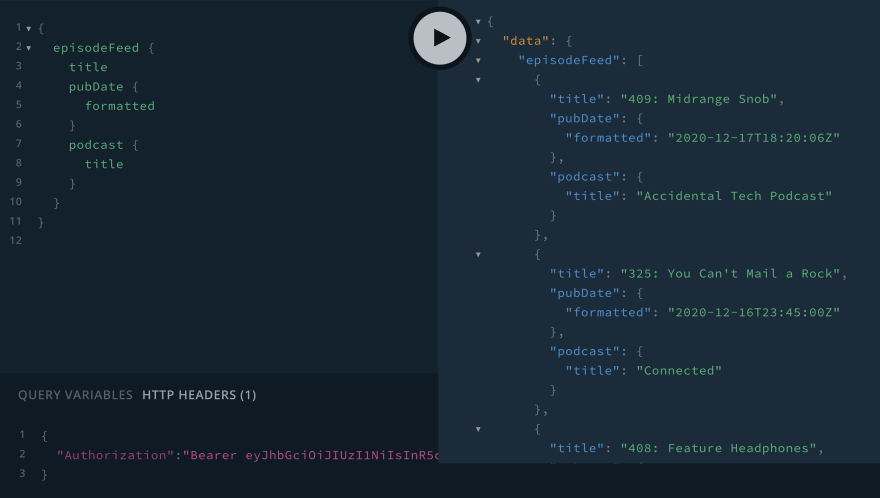
Playlists
Next, let's introduce the concept of playlists to our API. We want to add individual episodes to one or more playlists, which we should then be able to query for later and play episodes from each playlist. First, we'll add the Playlist type to our GraphQL type definitions:
type Playlist {
name: String!
episodes: [Episode] @relation(name: "IN_PLAYLIST", direction: "IN")
}
We want playlists to be private to the currently authenticated user so we'll add the Playlist type to the configuration to be excluded from automatic query and mutations. Instead we'll create @cypher directive fields to access playlists.
const schema = makeAugmentedSchema({
typeDefs,
resolvers,
config: {
query: {
exclude: ['PodcastSearchResult', 'AuthToken', 'User', 'Playlist']
},
mutation: {
exclude: ['PodcastSearchResult', 'AuthToken', 'User', 'Playlist']
}
}
});
Create Playlist
Since we added the Playlist type to be excluded from the generated queries and mutations during the schema augmentation process we'll need to define the logic for creating and updating playlists using @cypher schema directive fields. Let's add a createPlaylist field to the Mutation type:
type Mutation {
createPlaylist(name: String!): Playlist
@cypher(
statement: """
MATCH (u:User {id: $cypherParams.userId})
MERGE (p:Playlist {name: $name})<-[:OWNS]-(u)
RETURN p
"""
)
}
Now, we can create a playlist. Let's create a playlist called "jogging" that I'll use to listen to episodes while I'm on jogs around the neighborhood:
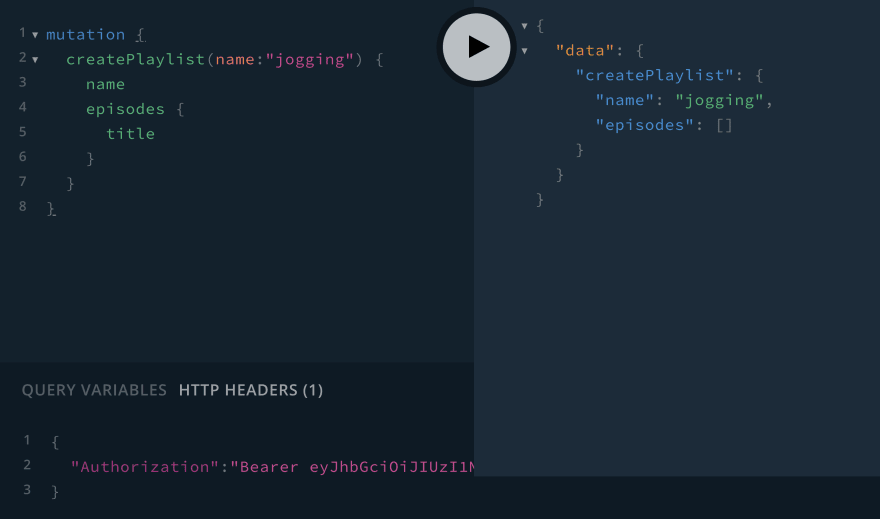
Note that the episodes array is empty - we haven't added any episodes to this playlist yet. Let's add that functionality to the GraphQL API now.
Add Episodes To Playlist
To enable users to add episodes to each playlist we'll create a new mutation field called addEpisodeToPlaylist that will take as arguments the name of the playlist and the id of a podcast episode to be added to the playlist. We'll define the logic for this mutation using a @cypher schema directive, ensuring that we match on the authenticated user and make sure they are the owner of the playlist before adding an IN_PLAYLIST relationship connecting the Episode and Playlist nodes.
type Mutation {
addEpisodeToPlaylist(name: String!, podcastId: ID!): Playlist
@cypher(
statement: """
MATCH (u:User {id: $cypherParams.userId})-[:OWNS]->(p:Playlist {name: $name})
MATCH (e:Episode {id: $podcastId})
MERGE (e)-[:IN_PLAYLIST]->(p)
RETURN p
"""
)
}

Get Playlist Episodes
Finally, we'll implement a query field to return all playlists a user owns, which can then also be used to return the episodes in each playlist, including episode details.
type Query {
playlists: [Playlist]
@cypher(
statement: """
MATCH (u:User {id: $cypherParams.userId})-[:OWNS]->(p:Playlist)
RETURN p
"""
)
}






Top comments (0)