
TLDR
Combine powerful database features with the flexibility of an object storage system by using the Delta Lake framework.
Outline
- Intro
- Prologue
- Defend the planet
- Final battle
- Epilogue
Intro

What’s Delta Lake?
This sounds like a new trending destination to take selfies in front of, but it’s even better than that. Delta Lake is an “open-source storage layer designed to run on top of an existing data lake and improve its reliability, security, and performance.” (source). It let’s you interact with an object storage system like you would with a database.
Why it’s useful?
An object storage system (e.g. Amazon S3, Azure Blob Storage, Google Cloud Platform Cloud Storage, etc.) makes it easy and simple to save large amounts of historical data and retrieve it for future use.
The downside of such systems is that you don’t get the benefits of a traditional database; e.g. ACID transactions, rollbacks, schema management, DML (data manipulation language) operations like merge and update, etc.
Delta Lake gives you best of both worlds. For more details on the benefits, check out their documentation.
Install Delta Lake
To install the Delta Lake Python library, run the following command in your terminal:
pip install deltalake
Setup Delta Lake storage
Delta Lake currently supports several storage backends:
- Amazon S3
- Azure Blob Storage
- GCP Cloud Storage
Before we can use Delta Lake, please setup one of the above storage options. For more information on Delta Lake’s supported storage backends, read their documentation on Amazon S3, Azure Blob Storage, and GCP Cloud Storage.
Prologue
We live in a multi-verse of planets and galaxies. Amongst the multi-verse, there exists a group of invaders determined to conquer all friendly planets. They call themselves the Gold Legion.

Many millennia ago, the Gold Legion conquered vast amounts of planets whose name have now been lost in history. Before these planets fell, they spent their final days exporting what they learned about their invaders, into the fabric of space; with the hopes of future generations surviving the oncoming calamity.

Along with the battle data, these civilizations exported their avatar’s magic energy into the cosmos so that others can one day harness it.
How to use Delta Lake
The current unnamed planet is falling. We have 1 last chance to export the battle data we learned about the Gold Legion. We’re going to use a reliable technology called Delta Lake for this task.
First, download a CSV file and create a dataframe object:
import pandas as pd
df = pd.read_csv(
'https://raw.githubusercontent.com/mage-ai/datasets/master/battle_history.csv',
)
Next, create a Delta Table from the dataframe object:
from deltalake.writer import write_deltalake
write_deltalake(
# Change this URI to your own unique URI
's3://mage-demo-public/battle-history/1337',
data=df,
mode='overwrite',
overwrite_schema=True,
storage_options={
'AWS_REGION': '...',
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
'AWS_S3_ALLOW_UNSAFE_RENAME': 'true',
},
)
If you want to append the data to an existing table, change the mode argument to append.
If you don’t want to change the schema when writing to an existing table, change the overwrite_schema argument to False.
When creating or appending data to a table, you can optionally write that data using partitions. Set the keyword argument partition_by to a list of 1 or more column names to use as the partition for the table. For example, partition_by=['planet', 'universe'].
For more options to customize your usage of Delta Lake, check out their awesome API documentation.
If you’re not sure what keys are available to use in the storage options dictionary, refer to these examples depending on the storage backend you’re using:
- Amazon S3
- Azure Blob Storage
- GCP Cloud Storage
Defend the planet
Fast forward to the present day and the Gold Legion has found Earth. They are beginning the invasion of our home planet. We must defend it!

Load data from Delta Lake
Let’s use Delta Lake to load battle history data from within the fabric of space.
If you don’t have AWS credentials, you can use these read-only credentials:
AWS_ACCESS_KEY_ID=AKIAZ4SRK3YKQJVOXW3Q
AWS_SECRET_ACCESS_KEY=beZfChoieDVvAVl+4jVvQtKm7HqbNrQun9ARMZDy
from deltalake import DeltaTable
dt = DeltaTable(
# Change this to your unique URI from a previous step
# if you’re using your own AWS credentials.
's3://mage-demo-public/battle-history/1337',
storage_options={
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
},
)
dt.to_pandas()
Here is how the data could look:
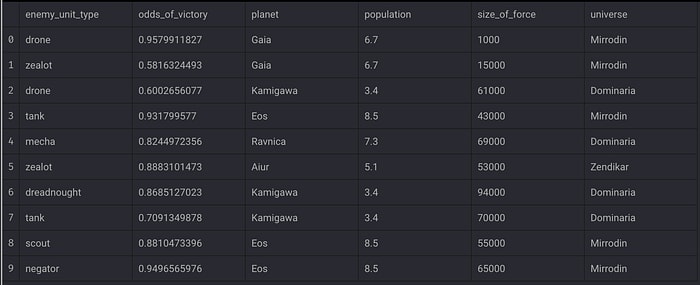
Now that we’ve acquired battle data from various interstellar planets across the multi-verse spanning many millennia, planet Earth has successfully halted the Gold Legion’s advances into the atmosphere!

However, the invaders are still in the Milky Way and are plotting their next incursion into our planet. Do you want to repel them once and for all? If so, proceed to the section labeled “Craft data pipeline (optional)”.
Time travel with versioned data
In the multi-verse, time is a concept that can be controlled. With Delta Lake, you can access data that has been created at different times. For example, let’s take the battle data, create a new table, and append data to that table several times:
from deltalake.writer import write_deltalake
# ['Aiur', 'Eos', 'Gaia', 'Kamigawa', 'Korhal', 'Ravnica']
planets = list(sorted(set(df['planet'].values)))
# Loop through each planet
for planet in planets:
# Select a subset of the battle history data for a single planet
planet_df = df.query(f"`planet` == '{planet}'")
# Write to Delta Lake for each planet and keep appending the data
write_deltalake(
# Change this URI to your own unique URI
's3://mage-demo-public/battle-history-versioned/1337',
data=planet_df,
mode='append',
storage_options={
'AWS_REGION': '...',
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
'AWS_S3_ALLOW_UNSAFE_RENAME': 'true',
},
)
print(
f'Created table with {len(planet_df.index)} records for planet {planet}.',
)
This operation will have appended data 6 times. Using Delta Lake, you can travel back in time and retrieve the data using the version parameter:
from deltalake import DeltaTable
dt = DeltaTable(
# Change this to your unique URI from a previous step
# if you’re using your own AWS credentials.
's3://mage-demo-public/battle-history-versioned/1337',
storage_options={
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
},
version=0,
)
dt.to_pandas()
The table returned will only include data from the planet Aiur because the 1st append operation only had data from that planet. If you change the version argument value from 0 to 1, the table will include data from Aiur and Eos.
Craft data pipeline (optional)
If you made it this far, then you’re determined to stop the Gold Legion for good. In order to do that, we must build a data pipeline that will continuously gather magic energy in addition to constantly collecting battle data from space.

Once this data is loaded, we’ll transform the data by deciphering its arcane knowledge and combining it all into a single concentrated source of magical energy.
The ancients, that came to our planet thousands of years before us, knew this day would come. They crafted a magical data pipeline tool called Mage that we’ll use to fight the enemy.

Go to demo.mage.ai, and click the New button in the top left corner, and select the option labeled Standard (batch).
Load magic energy
We’ll load the magic energy from the cosmos by reading a table using Delta Lake.
- Click the button + Data loader, select Python, and click the option labeled Generic (no template).
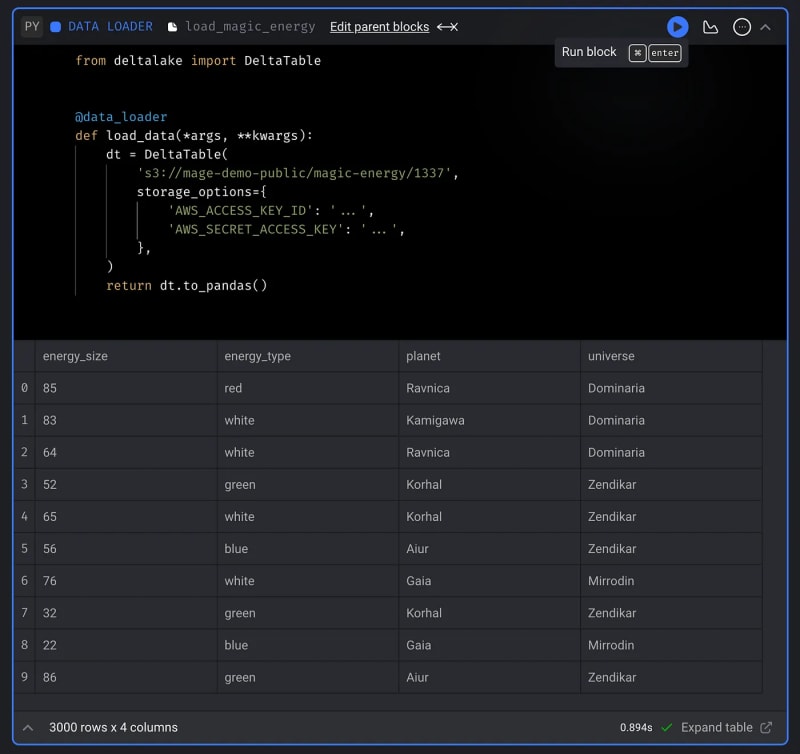
- Paste the following code into the text area:
from deltalake import DeltaTable
@data_loader
def load_data(*args, **kwargs):
dt = DeltaTable(
's3://mage-demo-public/magic-energy/1337',
storage_options={
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
},
)
return dt.to_pandas()
Use the following read-only AWS credentials to read from S3:
AWS_ACCESS_KEY_ID=AKIAZ4SRK3YKQJVOXW3Q
AWS_SECRET_ACCESS_KEY=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
- Click the play icon button in the top right corner of the block to run the code:
Transform data
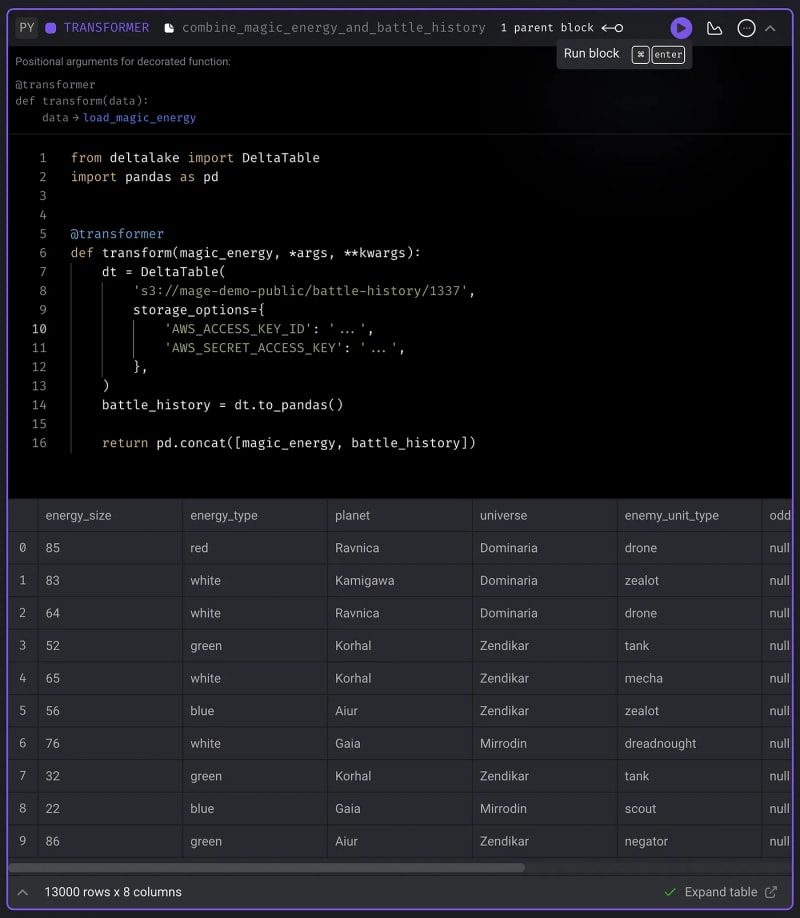
Now that we’ve retrieved the magic energy from the cosmos, let’s combine it with the battle history data.
- Click the button + Transformer, select Python, and click the option labeled Generic (no template).
- Paste the following code into the text area:
from deltalake import DeltaTable
import pandas as pd
@transformer
def transform(magic_energy, *args, **kwargs):
dt = DeltaTable(
# Change this to your unique URI from a previous step
# if you’re using your own AWS credentials.
's3://mage-demo-public/battle-history/1337',
storage_options={
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
},
)
battle_history = dt.to_pandas()
return pd.concat([magic_energy, battle_history])
- Click the play icon button in the top right corner of the block to run the code:
Export data
Now that we’ve combined millennia worth of battle data with magical energy from countless planets, we can channel that single source of energy into Earth’s Avatar of the Lake.
- Click the button + Data exporter, select Python, and click the option labeled Generic (no template).
- Paste the following code into the text area:
from deltalake.writer import write_deltalake
@data_exporter
def export_data(combined_data, *args, **kwargs):
write_deltalake(
# Change this URI to your own unique URI
's3://mage-demo-public/magic-energy-and-battle-history/1337',
data=combined_data,
mode='overwrite',
overwrite_schema=True,
storage_options={
'AWS_REGION': '...',
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
'AWS_S3_ALLOW_UNSAFE_RENAME': 'true',
},
partition_by=['planet'],
)
- Click the play icon button in the top right corner of the block to run the code:
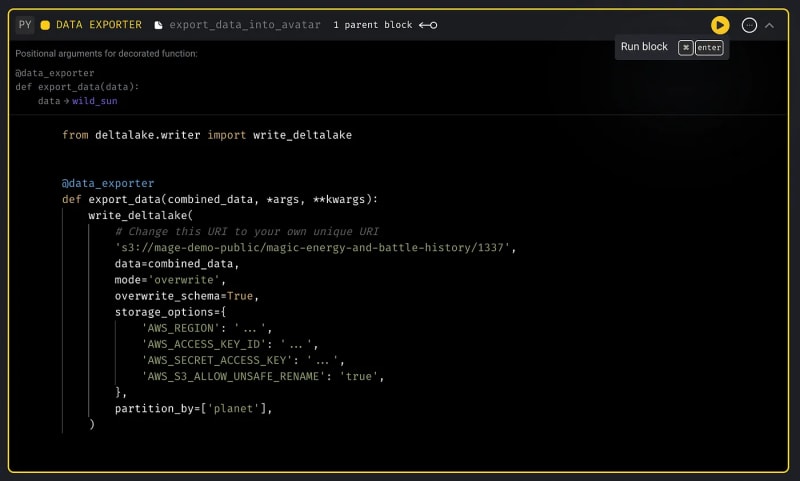
Your final magical data pipeline should look something like this:
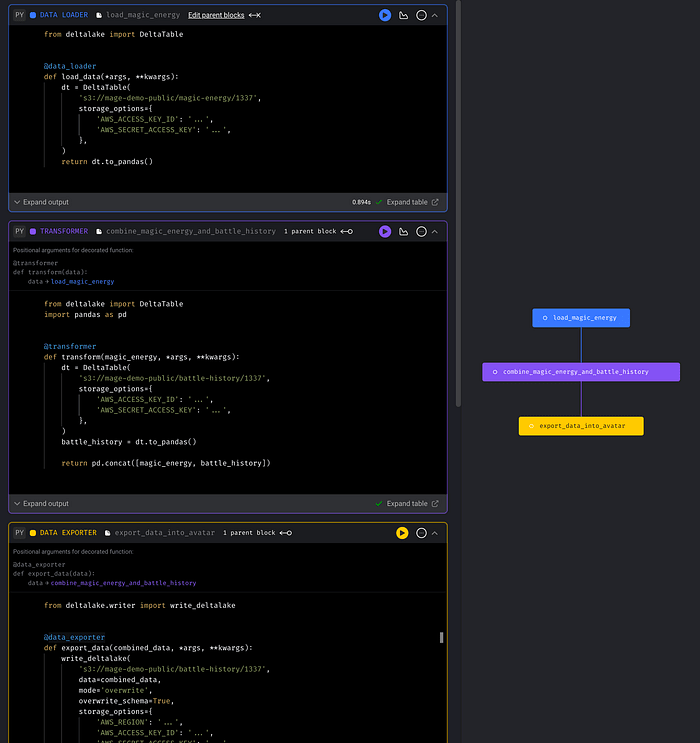
Data partitioning
Partitioning your data can improve read performance when querying records. Delta Lake makes data partitioning very easy. In the last data exporter step, we used a keyword argument named partition_by with the value ['planet']. This will partition the data by the values in the planet column.
To retrieve the data for a specific partition, use the following API:
from deltalake import DeltaTable
dt = DeltaTable(
# Change this to your unique URI from a previous step
# if you’re using your own AWS credentials.
's3://mage-demo-public/magic-energy-and-battle-history/1337',
storage_options={
'AWS_ACCESS_KEY_ID': '...',
'AWS_SECRET_ACCESS_KEY': '...',
},
)
dt.to_pandas(partitions=[('planet', '=', 'Gaia')])
This will return data only for the planet Gaia.
Final battle
The Gold Legion’s armies descend upon Earth to annihilate all that stand in its way.

As Earth makes its final stand, mages across the planet channel their energy to summon the Avatar of the Lake from its century long slumber.

The Gold Legion’s forces clash with the Avatar. At the start of the battle, the Avatar of the Lake land several powerful blows against the enemy; destroying many of their forces. However, the Gold Legion combines all of its forces into a single entity and goes on the offensive.

Earth’s Avatar is greatly damaged and weakened after a barrage of attacks from the Gold Legion’s unified entity. When all hope seemed lost, the magic energy from the cosmos and the battle data from the fabric of space finally merges together and is exported from Earth into the Avatar; filling it with unprecedented celestial power.

The Avatar of the Lake, filled with magic power, destroys the Gold Legion and crushes their will to fight. The invaders leave the galaxy and never return!
Epilogue
Congratulations! You learned how to use Delta Lake to create tables and read tables. Using that knowledge, you successfully saved the multi-verse.
In addition, you defended Earth by using Mage to create a data pipeline to load data from different sources, transform that data, and export the final data product using Delta Lake.
The multi-verse can rest easy knowing heroes like you exist.

Stay tuned for the next episode in the series where you’ll learn how to build low-code data integration pipelines syncing data between various sources and destinations with Delta Lake.
Link to original blog: https://www.mage.ai/blog/how-to-build-a-data-pipeline-using-delta-lake





Top comments (1)
This is epic!