
TLDR
In this Mage Academy guide, we’ll go over how to evaluate a machine learning (ML) model and learn how to improve the model’s performance.
Glossary
- Link to code notebook
- Introduction
- Evaluate model
- Pick a metric
- Is the model generalized?
- Improve model’s performance
- Hyperparameter tuning
- Feature importance
- Retrain model
- Predictive system
- Magical no code solution
Link to code notebook
For quick reference, check this link for the code and this link for the dataset.
Introduction
In the Music genre classification guide, we’ve learned how to build a machine learning model to classify the genres of songs. Hooray!!
Let’s quickly take a look at the models.
1 from sklearn.preprocessing import StandardScaler
2 from sklearn.linear_model import LogisticRegression
3 # scaling
4 scaler = StandardScaler()
5 standardized_x_train = pd. DataFrame (scaler.fit_transform(X_train), columns = X_train.columns)
6 standardized_x_test = pd.DataFrame (scaler.transform(X_test), columns = X_test.columns)
7 # train and build model
8 LRmodel = LogisticRegression (multi_class = 'multinomial').fit(standardized_x_train, y_train)
Logistic regression model
1 from sklearn.preprocessing import StandardScaler
2 from xgboost import XGBClassifier
3 # scaling
4 scaler = StandardScaler()
5 standardized_x_train = pd.DataFrame (scaler.fit_transform(X_train), columns = X_train.columns)
6 standardized_x_test = pd.DataFrame (scaler.transform(X_test), columns = X_test.columns)
7 # train and build model
8 XGBmodel = XGBClassifier(objective = 'multi:softprob').fit(standardized_x_train, y_train)
XGBoost model
Note: In the Music genre classification article, we didn’t build the XGBoost model.
The models are built but there may be many other questions going on in your head, such as:
- Which model do I choose?
- Can I use these models to classify the genre of real-world data (especially my favorite songs :))?
Don’t worry, let’s find answers to these questions together.
At the end, we’ll also find out which attributes are really important for classifying the genre of the song. Are you wondering if this is possible? Yes, it’s possible!! Pretty interesting, right?
Okay, I hope you're ready for this bumpy ride.
Without any further ado, let’s start!!!
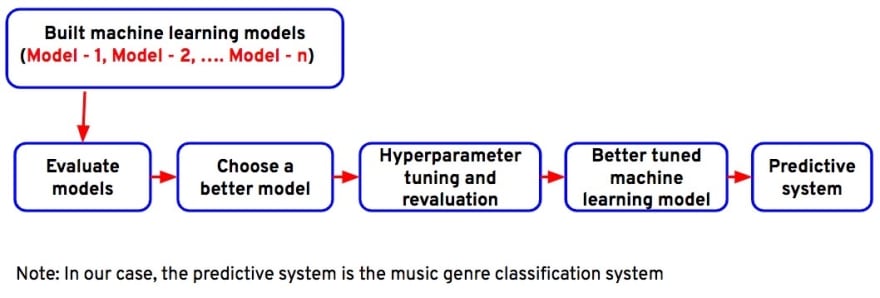 Part-2: Process to build a music genre classification system
Part-2: Process to build a music genre classification system
As you may be very eager to use these models to classify the genre of your favorite songs, let’s start our journey from this point. Choose the best model to predict the song genres. For this, we need to evaluate all the models and compare them.
Evaluate model
Let’s imagine that you’re a teacher. How do you evaluate the performance of your students? You create a set of questions and compare who has the highest marks.
Now, let’s evaluate machine learning models in the same way by conducting a test. For this,
- We’ll first pass the test data inputs into the model, then ask the model to predict the classes for the given inputs. We’ll pass the song attributes into the model, and predict the genre of song.
- Next, we’ll evaluate the models on their performance. Performance measured using evaluation metrics. These metrics come from mathematical formulas that return numerical values. There are many evaluation metrics for classification use cases such as accuracy, precision, recall, log-loss, etc. Some of these metrics are calculated based on a confusion matrix. Most of the time, the best metrics is determined by domain experts that understand the model’s usage and goals.
Pick a metric
For our use case, because music genres contain 3 more types, we'll be using log-loss as our evaluation metric since it’s a multi class classification model. The log-loss metric measures the distance between a predicted and actual class probability value. For a more detailed explanation on log-loss, check out this article. The performance is best when the log-loss is zero or close to zero. So, let’s begin to calculate log-loss scores for both logistic regression and XGBoost models and pick a model that has the least log-loss score.
1 from sklearn.metrics import log_loss
2
3 # logistic regression log-loss or cross-entropy
4 logloss_metric = log_loss(y_test, y_test_pred_prob)
5 print("Test data log_loss", logloss_metric)
 Logistic regression log-loss
Logistic regression log-loss
1 # XGBoost log-loss or cross-entropy
2 logloss_metric = log_loss (y_test, y_test_pred_prob)
3 print("Test data log_los", logloss_metric)
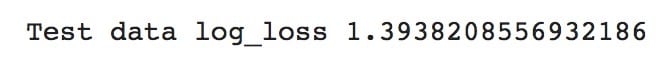 XGBoost log-loss
XGBoost log-loss
When log-loss values of both models are compared, the XGBoost model has a lower log-loss value (1.3938) than the logistic regression model's log-loss value (1.5231). So, we can conclude that the XGBoost model is better at predicting the genre of real world data (songs). By this we’ve got an answer to your 1st question (Which model do I choose?)
Is the model generalized?
First of all let’s understand what model generalization is and why it’s important to generalize the model.
In simple terms, model generalization is to make the machine learning model ready for real world data i.e., in our case the model should be able to predict the class of your favorite song. If the model isn’t generalized then it may not be able to work well for real world data i.e., it may not predict your favorite songs accurately. So it’s really important to check for model generalization. Let’s try to understand it with the help of an example.
Let’s go back to the math teacher's example. This time you’ve got a couple of questions, such as: are your students paying attention and are they able to grasp all of the concepts covered in class? So, you decided to conduct 2 mock objective tests: 1 (test A) to assess their attentiveness in class, and the other (test B) to assess their understanding of the concepts. Based on the scores obtained in these tests, we can determine if the student is ready for the main exam or not.
To evaluate attentiveness, you may ask them to solve the exact same problems that have been taught in class, and to evaluate their understanding of concepts, you may ask them to solve problems that are similar but not exactly the same as those taught in class. Based on the test scores, you may be able to tell if the student really understood the concepts and was ready for the main exam or not.
- If a student secured a high score in test A but not in test B, then we can conclude that the student isn’t ready for the main exam as he/she was simply memorizing the answers but didn’t understand the concepts.
- If a student didn’t perform well in both tests A and B but secured slightly more marks in test B (possibly by guessing) than in test A, we can conclude that the student didn’t really understand the concepts and wasn’t ready for the main exam.
- But if a student passed the exam and scored more or less the same in both the tests, then we can conclude that the student is ready for the main exam and that he/she also understood the concepts but may need more practice.
Just like how we analyzed the students' readiness to take the main exams, we may evaluate if the model is generalized or not by conducting 2 tests and comparing their results. The only difference is that here we'll use evaluation metrics to calculate the scores. One test is conducted on a training dataset; it’s the same data on which machine learning models are trained (exactly the same problems that've been taught in the class). The other test is conducted on a test dataset, which contains values similar to those in the training dataset (similar to the problems that were taught in the class).
- If the machine learning model predicts well (evaluation score is high) for the training dataset instances but not for the testing dataset, then we can conclude that the machine learning model is just memorizing the data, i.e., the model is overfitted.
- If a machine learning model performs slightly better on a testing dataset than on a training dataset, we say that the model didn’t identify or understand the concept or pattern, and this means that the model is underfitting.
- If a machine learning model's evaluation score is pretty much the same for both training and testing datasets, then we say that the model is a good fit or generalized.
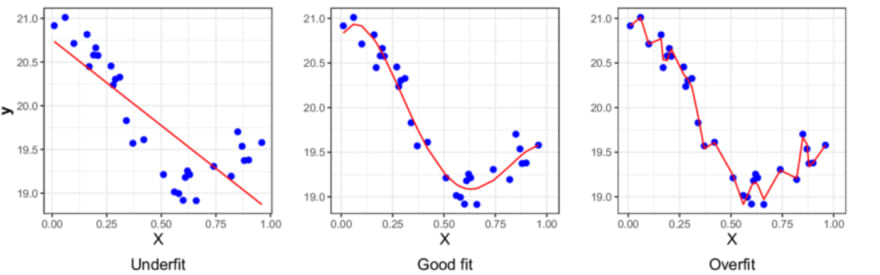 Source: ResearchGate
Source: ResearchGate
So now let’s check if our XGBoost genre classification model is overfit, underfit, or generalized. We’ll use the log-loss metric to evaluate the scores of the training and test data sets.
1 # train predict
2 y_train_pred_prob = XGBmodel.predict_proba(standardized_x_train)
3
4 # train data log-loss
5 train_logloss = log_loss(y_train, y_train_pred_prob)
6 print("Train data log_loss",train_logloss)

1 # test predict
2 y_test_pred_prob = XGBmodel.predict_proba (standardized_x_test)
3
4 # test data log-loss
5 test_logloss = log_loss(y_test, y_test_pred_prob)
6 print("Test data log_loss",test_logloss)
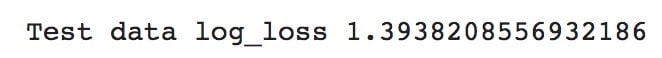
While evaluating the scores with respect to log_loss, we have to keep in mind that the better model is the 1 that has the least log_loss value. We see that the test data log_loss value is greater (1.39382) when compared to the train data log_loss value (1.23169). So this indicates that the model is overfitting and it cannot predict genres of real-world data (songs). With this, we found our answer to the 2nd question as well (Can I use these models to classify the genre of real world data?).
Improve model’s performance
Even though the XGBoost model performed better for our music genre classification, the model‘s performance is still considered average. Let’s see if there’s a way to improve this model’s performance and generalize the model.
Machine learning model’s performance can be improved by Hyperparameter tuning
Hyperparameter tuning
Let’s say that you’ve tuned in to a radio channel to listen to songs, but due to some noise, you weren’t able to hear the songs clearly. What would you do in this situation? If you’re thinking about tuning the channel, i.e., adjust the frequency, then pat yourself on the back!!
Similar to how you tune the radio, you can tune a machine learning model to improve performance.
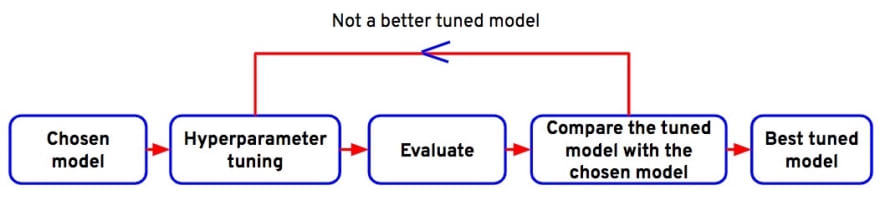 Iterative process of hyperparameter tuning
Iterative process of hyperparameter tuning
Machine learning models have hyperparameters, and these can be tuned to increase the model's performance as well as to make the model more generalized. To further improve the XGBoost model, we'll tune the hyperparameters of this model.
For this guide, I’ll consider tuning only a few hyperparameters, such as max_depth, min_child_weight, n_estimators, learning_rate, and subsample.
After a few trials, the values of the hyperparameters that slightly decreased the log-loss score were:

1 # train and build model
2 XGBmodel = XGBClassifier(objective = 'multi:softprob',
3 max_depth = 2,
4 min_child_weight 50,
5 n_estimators = 1200,
6 learning_rate = 0.02,
7 subsample 0.8).fit(standardized_x_train, y_train)
8 y_train_pred_prob = XGBmodel.predict_proba (standardized_x_train)
9 # train data log-loss
10 train_logloss = log_loss (y_train, y_train_pred_prob)
11 print("Train data log_loss after hyperparameter tuning",train_logloss)
12
13 y_test_pred_prob = XGBmodel.predict_proba(standardized_x_test)
14 # test data log-loss
15 test_logloss = log_loss(y_test, y_test_pred_prob)
16 print("Test data log_loss after hyperparameter tuning", test_logloss)
XGBoost hyperparameter tuned model building and evaluation
 XGBoost model log-loss values after hyperparameter tuning
XGBoost model log-loss values after hyperparameter tuning
With just a few trials, the model's error decreased from 1.3938 to 1.37790, and also the difference between train and test data log_loss decreased. This increases the overall performance of the model. Even though it's a minor change, it shows improvement. This model can be used to predict the genres of real-world data (songs) but the prediction may still not be very accurate as there’s still error in the model. With more trials, we can reduce the error even further and build a more efficient model.
To quickly select the best values for the hyperparameters, there are a few techniques such as gridsearch, random search, bayesian optimization, etc. We’ll discuss these topics in future articles as they are out of scope for this article.
Feature importance
By using the SHAP library, we can find the top features that influence our genre classification model. Learn more about SHAP values in this article.
1 !pip install shap
2
3 import shap
4 explainer = shap. TreeExplainer (model)
5 shap_values = explainer.shap_values (X)
6 shap.summary_plot(shap_values, X, plot_type='bar')
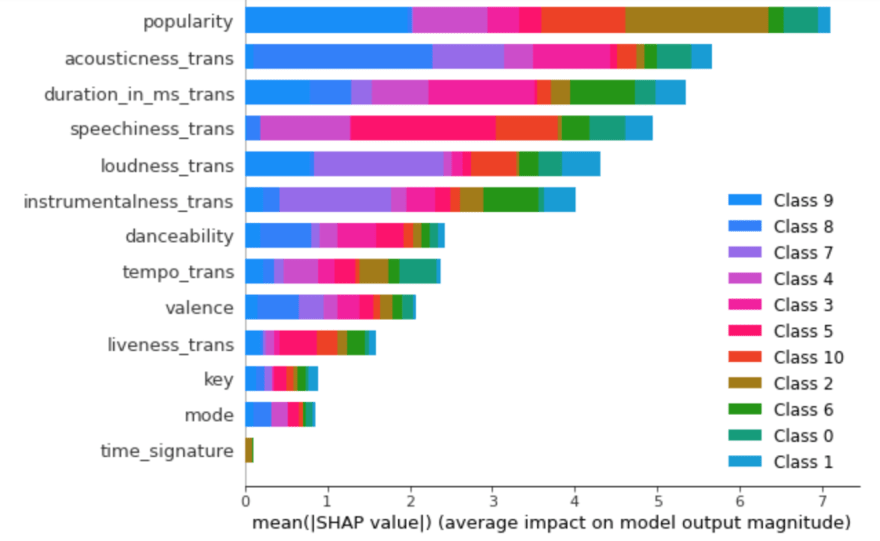
From the plot, we see that the "popularity" and “acousticness_trans” features are the top influencers of the model, while the "key," "mode," and "time_signature" features have the least impact on the model. We can also remove the features that have the least impact on the model and rebuild it for better performance.
Retrain model
Let’s go back to the math teacher's example. If a student scored poorly on the test, what suggestions would you give them to improve their score? You point out some areas where they can improve, ask them to practice those concepts, and assist them by teaching those concepts again in a new way that they can easily understand by giving lots of new examples. In the same way, we can again improve the model efficiency by retraining the algorithm with either recleaning, repreparing the data, adding more data, removing features that have less impact on the machine learning model or by resampling the data.
Predictive system
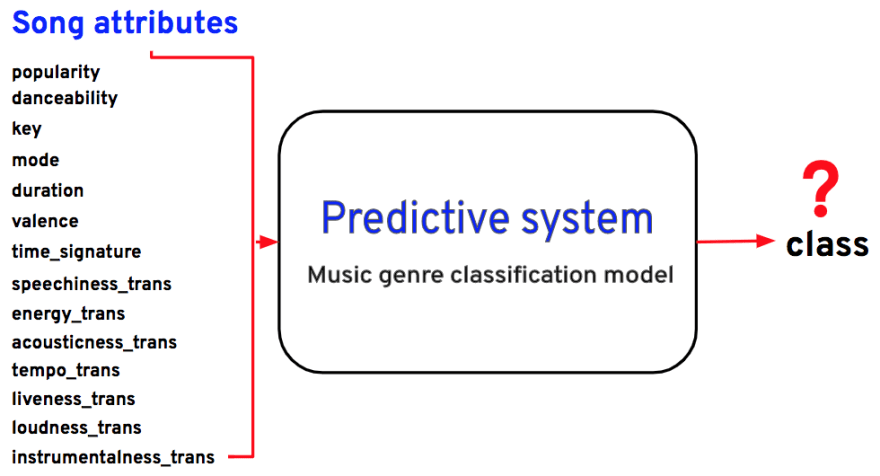
In our case, the predictive system is the music genre classification system. Once we find the music genre classification optimal model, we can use the optimal model to predict the classes on real-world data. We’ll use the Scikit-learn predict() function to predict the genres of songs.

![]()
Magical no code solution
Once the machine learning model has been created, Mage will provide you with several statistics to help you better understand the data. Mage computes and displays the results of all metrics, such as accuracy, precision, etc.
On top of this, Mage also provides you with assessments for each metric value.

As you’ve observed, when compared to the model built by us manually, the Mage model gives us better accuracy without even performing hyperparameter tuning. Isn't this amazing?
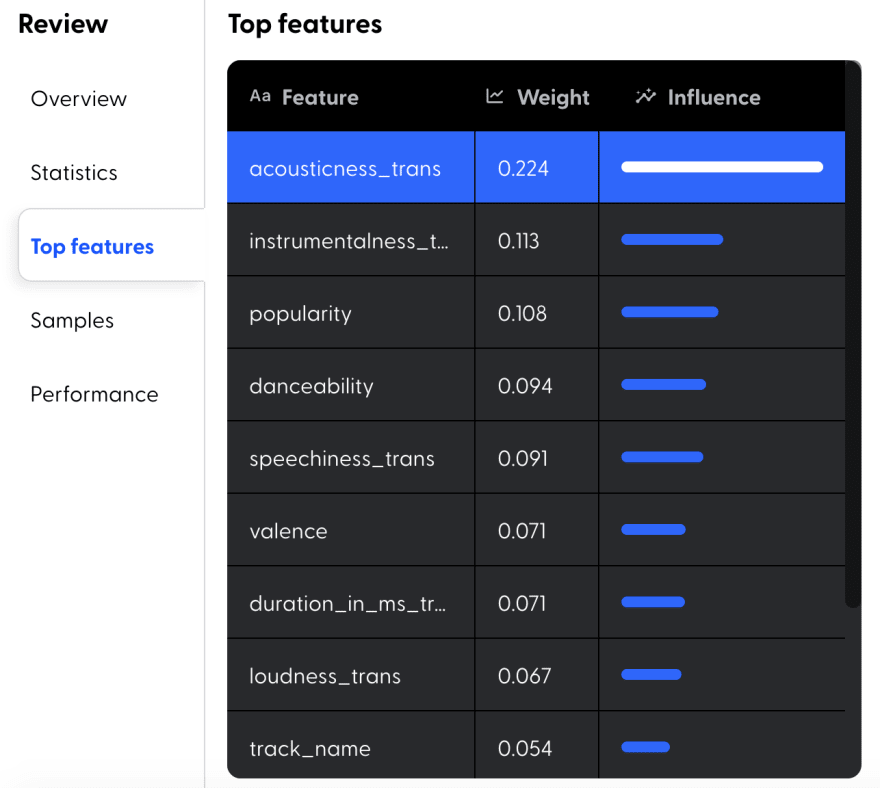
Mage also generates the list of top features. This helps us understand which features are important to predict the genre of songs.
Finally, Mage also provides you with a playground to test real-world data. Woohoo!!
 Mage’s playground
Mage’s playground
Simply fill in the feature values and see the predicted results given by the model.
If you are still not happy with the results, you can retrain the model by removing less-impacted features or by adding more data and see if the model's performance improves.
As you’ve seen it’s simple to build models with Mage. Try by yourself, start by uploading data, and that's it. You’re just a few clicks away from building an efficient machine learning model.



Top comments (0)