I always used capturing groups in regexes to extract parts of the string I was matching for later reference (for example, substitutions).
TIL that they can also be used during the actual matching 😮.
What the heck are capturing groups?
Given a piece of code with this method invocation:
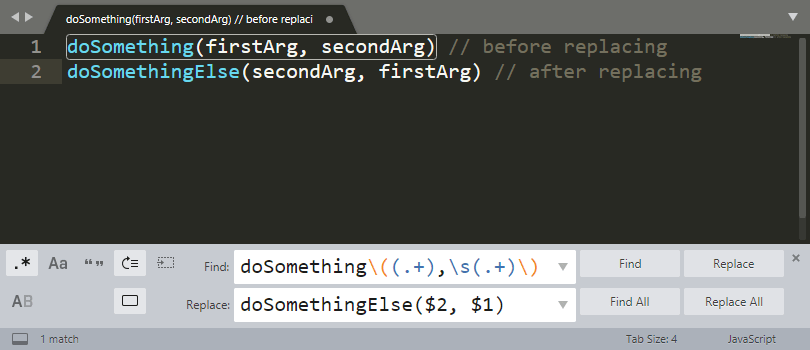
doSomething(firstArg, secondArg)
if I want to make a substitution to use another method which needs the arguments swapped, I can do it with a regex like this:
doSomething\((.+),\s(.+)\)
The parts of the expression inside the round brackets (aside the escaped ones) are capturing groups. They can be used to treat the wrapped expression as a whole, for example applying a quantifier.
Moreover, capturing groups make it easy to extract part of the regex match.
In the previous example, after the match, I can refer to the extracted groups by their position.
So group 1 will be firstArg and group 2 willl be secondArg.
If my editor supports regex substitution or I'm writing some script to automate the operation, I can do something like this to replace the method:
doSomethingElse($2, $1)
which will result in
doSomethingElse(secondArg, firstArg)
(the right syntax really depends on the tool you are using).
Apparently there's more to that!
This kind of substitution is really cool, but capturing groups can be more powerful than that! 🚀
They can also be used during the matching itself to check if a part of the string matches another part already matched.
For example, if I want to check if a string starts and ends with the same sequence of numbers allowing any character string in the middle, I can do it with something like this:
(\d+)[A-Za-z]+\1
The first and only capturing group (\d+) will match any number sequence and the [A-Za-z]+ expression will match the character sequence.
The magic happens with the \1 expression, which is a way to reference the first capturing group of our expression, verifying that this last part of the string matches that group. The number corresponds to the number of the capturing group.
With this regex we can check for strings like:
123HelloWorld123
A more realistic scenario may be a csv file with records holding date of creation and update:
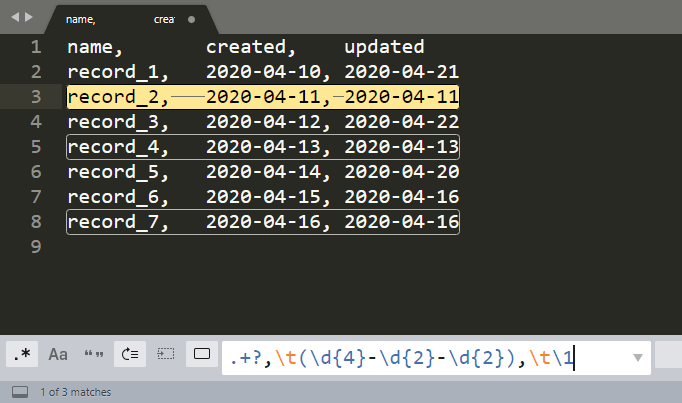
name, created, updated
record_1, 2020-04-10, 2020-04-21
record_2, 2020-04-11, 2020-04-11
record_3, 2020-04-12, 2020-04-22
record_4, 2020-04-13, 2020-04-13
record_5, 2020-04-14, 2020-04-20
record_6, 2020-04-15, 2020-04-16
record_7, 2020-04-16, 2020-04-16
We can use capturing groups if we want to find records whose created and updated dates are equals.
The regex will be something like this:
.+?,\t(\d{4}-\d{2}-\d{2}),\t\1
Not much readable but quite simple. The important bits are the capturing group in round brackets that matches a date and the \1 recalling it. The regex will match only if this two elements are actually equals.
Running the search in a text editor will highlight all the lines whose dates corresponds.
These are simple examples and more complex matchings are possible but it really blows my mind that a feature of regexes that I already considered really useful is indeed a lot more powerful!




Top comments (0)