
Introduction
Tales is the first application from Harpy, a web platform for Tabletop RPG lovers (D&D, Cthulhu, Pathfinder, L5R, etc). It's a collective story telling app. A Roleplay chat where you speak as your character instead of as yourself.
The problem
In Tales, a player can create a Story divided in Chapters. A Chapter is basically a chat where characters speak. So "just" a list of posts ordered by creation date, right?
Not really. Here's the catch:
- We should load the posts from the latest post a player has seen
- Lazy load should work in both directions (previous posts, next posts)
- Since a character can come and go in a Chapter, all the posts are not necessarily visible by the current user.
- This is live data. If a post is created, updated or deleted by a player, then other players should see the posts being updated right away.
- To make sure the Story makes sense, the main player (called Game master) can move posts around (because sometimes a player will post a message before another player had time to answer). This should also update other players chapter right away.
I'm going to share the different solutions we've come up with and why they didn't really work for us. Hopefully it will be helpful to someone.
Solution 1: Paginate and merge
Ok so let's load posts by chunks of 15, then merge them.
We take the timestamp of the last seen post (let's call it pivotDate) and use it to query around it.
1) The 15 posts before pivotDate.
2) All the posts after pivotDate and before nowDate (time on page load)
3) All the posts after nowDate

You could merge 2 and 3 as a single query but I chose to separate them for some reason that I forgot (hum).
So now you just have to add some kind of separator between 1 and 2, then center the view on it on load (with scrollTo).
Also it should be fairly easy support lazy loading. Watch the scroll and query more chunks with a endBefore based on the latest loaded post and a given limit. I used RxJS combineLatest function to merge everything into a single observable.
If you don't need to support posts being deleted or moved around, this is a pretty good solution, I think. It's cost effective and rather efficient. Firestore does the job on its own.
But what happens if I delete a post?
To make it more readable, let's say we have chunks of 5 posts instead of 15.

Now, what happens if I delete post 63? Well, Chunk 2 query result will be updated and since there's a limitToLast(5) it will now also include post 60. And since nothing has changed on Chunk 1, we'll have the post 60 twice (in both Chunk 1 and 2).

Same problem if we try to move things around. The problem is that our chunk queries are based on static post timestamps.
Solution 2: No limit, just a hour based pagination
So let's forget about post timestamp. They are not reliable enough. Maybe we could simply paginate by chunk of 24 hours?
Let's say I want to load 5 more posts, then I query more chunks with a 24 hours delta until I get 5 or more posts (not the greatest idea but I was frustrated at this point).
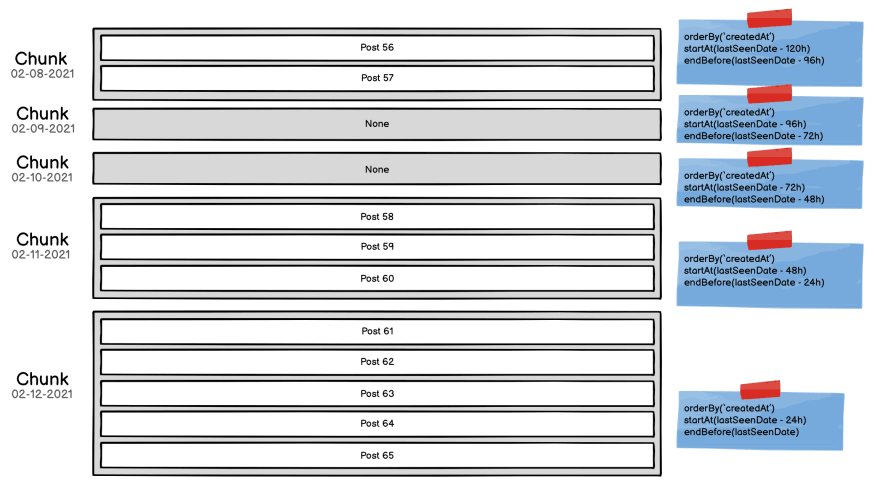
So yeah... it kinda works. I can delete posts and move them around and it will work fine. Each chunk holds the view on a given time period without any time hole.
But if for some reason no player has posted anything in 5 months then you'll have to wait for 30 x 5 queries to return empty results before seing anything.
Extra costs wouldn't be a problem though since Firestore pricing is based on the number of results and not the number of queries (not 100% sure though). So 150 queries returning no result shouldn't cost anything (I guess).
Still, this can't be the best solution, right?
Solution 3: No more merging. Just increase the limit when you need it
Ok, so what if I completely dump the chunk system and simply increase the limit as the player scrolls.
First load the 15 latest posts. Player scrolls.. Now the limit is 30. Player scrolls... Limit 45... Player scrolls... Limit 60...
It works and it's not that slow actually because Firestore is really fast (as long as the player doesn't try to load 1000 posts or more).
And the code is far simpler. No more merging. Just a regular query.
The big problem is that every time you update the limit you send a new query and that's not cost effective (at all).
Let's say we have 100 posts on a Chapter. Player wants to load them all. Let's say we increase the limit by 20 on scroll. We load the latest 20... then the latest 40... 60... 80... 100. Done. So, how many reads will we be charged for?
Answer: 20 + 40 + 60 + 80 + 100 = 300 reads
With 200 posts that would make 1100 reads
With 1000 posts that would make 25500 reads.
So... let's not do that.
Solution 4: Same thing but on RTDB because it's cheaper
As long as you don't have too many users, solution 3 is not that bad. Firebase free tier is very generous. But as your user base grows, you quickly have to find another way.
And that's too bad because at this point all our requirements are met... if money wasn't an issue.
The thing is Realtime Database (RTDB) pricing is not based on the number of reads (like Firestore) but on the data stored and downloaded. So what if we create an index of posts on RTDB with the postUid and timestamp only then use Firestore to load the post when needed?
Well it works...
...as long as you don't need a decent query system.
Take a look at the "Sorting and Filtering data" on the RTDB docs
You remember that not all players can see the same posts?
Well on RTDB, you can only filter by one value and it has to be the one you used to order by... So no more magic "array-contains" for me to filter on.

It's alright... Who needs a query system really? Let's create a bunch of indexes instead. 1 player = 1 index.
Data duplication. The dream, right? (sarcasm)
Well, that's actually my current solution. Yup. On each write (create/update/delete), a Cloud function updates all the related indexes.
The writes are cumbersome (and error prone) but the reads are super fast!
Example:
You're user 982sed87JKUISDjks2, trying to load posts from Chapter 9kklskç349dskfjsk? Easy enough. Give me the 50 latest from RTDB key chats.9kklskç349dskfjsk.users.982sed87JKUISDjks2.visiblePosts
POW!

So that's it. That's my current solution. It's not great I know. But it works, it's fast and it costs nothing.
Solution 5 (Bonus) You're creating your own indexes, maybe you should simply use a search engine like Algolia, Meilisearch or Typesense instead.
Maybe but I would lose realtime then.
Solution 6 (Bonus) Use Supabase
Supabase is an open source (wannabe) equivalent of Firebase. It already does a lot and uses Postgres as database. So it has a real query system (and is realtime!)
The thing is, many features are still missing (Cloud Functions for instance) so a migration is not possible at the moment. Also I don't know how much slower the database would be compared to a NoSQL database like RTDB or Firestore.
Still, this will probably become the way to go at some point if Firebase doesn't offer a decent solution for this use case.
Solution 7 (Bonus) Do you really need realtime?
Fair enough... maybe I don't need realtime. But it makes everything else so simple. Once you've tasted the joy of reactive programming it's hard to work without it. So I'll stick to it for now.
Conclusion
In conclusion, there are no perfect solution right now. As usual, it's all about trade offs.
Please comment if you come up with another solution.
If you want to take a look at Tales it's available for free on the web and on the Appstore






Top comments (0)