One of the most important parts of building an API, or any codebase for that matter, is making sure it is well-documented. How can users know how to use your API, or what it even does if there’s no documentation? How can your team members (or yourself 6 months from now) know how to extend and test your endpoints if there’s nothing describing how they’re supposed to behave?
The biggest hurdle with documentation in my experience is maintaining them. What happens when someone is in a rush to build a feature and they forget to add it to the docs? Or when business rules change and certain inputs and outputs change? Poorly maintained documentation quickly becomes useless as users and developers no longer trust them, and suddenly it’s as if there are no docs at all, leaving them to guess at contracts. See: The Broken Window Theory for why this happens.
This is where specifications come in.
API Specification vs API Documentation
What is an API Specification and how does it differ from documentation? Nordic APIs has a great article that goes into the differences in detail
Simply put, documentation explains how to use the API, while a specification describes how the API behaves. I’ve seen specifications described as blueprints for your API and I think that analogy is accurate. Indeed you can derive many things from a well-built specification including documentation, validation rules, front-end API clients, contract tests, and more.
There are a whole host of specs to choose from, but I’m focusing on OpenAPI Version 2 (I will explain why later) and JSON Schema.
OpenAPI
Remember that we will be using Open API Version 2 for the remainder of this article.
Generating the specification
Open API is an API specification developed by SmartBear and can be written (or generated) as YAML or JSON files. You may also notice that when using Laravel or PHP, you can use libraries such as L5-Swagger to use annotations for generating your spec. Despite my instincts telling me this is a horrible idea I decided to give it a try. My instincts were right, it’s a horrible idea, for a number of reasons.
The most readily apparent reason, though superficial, is that writing and maintaining these annotations is a chore. There’s no IDE plugins to help with formatting so you end up fiddling with asterisks, white spaces, and curly brace and comma alignment for far too long just to keep them looking nice.
Aside from that, once you’re done writing the annotations, you’ll notice that they now take up the majority of your source files,add unnecessary cognitive overhead, and can become difficult to find when needed.
What would be a better approach to this madness? We still need our spec to be scalable, so it can’t exist as one file. We want it to be easily navigable and editable, and we want generation of docs, tests, etc, to be straightforward.
I chose to maintain my spec separately from my code in a folder labeled spec in the root of my Laravel app using YAML files. Though I’m by no means a fan of YAML, I prefer writing it by hand over JSON.
Example
Let’s pretend we are building a simple REST API for a blog with a few endpoints for managing articles. The endpoints might look something like this:
GET /
GET /articles
POST /articles
GET /articles/{slug}
PUT /articles/{slug}
DELETE /articles/{slug}
Setting up the Application
If you want to follow along, create a dev environment however you’d like to (straight on your dev machine, or using a tool like Vagrant or Docker), and install a fresh copy of Laravel.
Setting up the build tools
We want to first setup all the tools and scripts necessary for building our spec. The tools I’m using are: json-refs, path-loader, js-yaml, and swagger-cli. Make sure NPM is installed and grab these packages with
npm install --save-dev json-refs path-loader js-yaml swagger-cli
Create a scripts directory in your application root and place the following script in a file called build-spec.js
var JsonRefs = require('json-refs');
var PathLoader = require('path-loader');
var YAML = require('js-yaml');
var fs = require('fs');
var root = YAML.load(fs.readFileSync('../spec/api.yaml').toString());
var options = {
loaderOptions: {
processContent: function (res, callback) {
callback(YAML.safeLoad(res.text));
}
},
location: '../spec/api.yaml'
};
JsonRefs.resolveRefs(root, options).then(function (results) {
var dir = '../spec/dist';
if (!fs.existsSync(dir)){
fs.mkdirSync(dir);
}
fs.writeFileSync('../spec/dist/api.yaml', YAML.dump(results.resolved), function(err) {
if(err) {
return console.log(err);
}
console.log('Specification compiled successfully.');
});
}, function(err) {
console.log(err);
});
This script converts the YAML files to JSON and resolves all of our external references.
Finally, add the following line to the scripts section of the package.json file.
"build-spec": "cd scripts && node build-spec.js && swagger-cli validate ../spec/dist/api.yaml"
Creating the spec object
Now that we have our build tools setup, create the spec folder in the root of the application with a file called api.yaml. According to the spec, there are three required fields. The swagger field, which specifies the version of Open API that we are using (it’s called openapi in version 3), the info field, which contains basic information about our API like it’s name and version, and the paths field, which contains our endpoint definitions. Put together, a basic spec might look something like this:
swagger: '2.0'
info:
version: '1.0'
title: Blog API
host: 'api.blog.test'
schemes: [http]
consumes: [application/json]
produces: [application/json]
paths:
$ref: ./paths.yaml
And in paths.yaml, let’s create a simple endpoint to display our API version
/:
get:
summary: 'Return the API's version'
responses:
200:
description: 'API version successfully returned.'
You can now run the build script to resolve the external references, validate the spec, and output the final product by running:
npm run build-spec
Adding the endpoint
Let’s add the post index endpoint to our spec. I like to split out our spec into modules, following the application structure as outlined in Scaling Laravel Architecture.
Create an articles directory, a paths subdirectory, and a YAML file called article-index.yaml. Your directory structure should look like this:
spec
├── dist
│ └── api.yaml
├── articles
│ └── paths
│ └── article-index.yaml
├── api.yaml
└── paths.yaml
Let’s write our post index endpoint spec!
summary: 'Return a list of articles.'
tags:
- Articles
parameters:
- name: page
in: query
required: false
type: integer
- name: limit
in: query
required: false
type: integer
responses:
200:
description: 'Articles returned successfully.'
schema:
type: object
properties:
meta:
type: object
properties:
page:
type: integer
total:
type: integer
last_page:
type: integer
limit:
type: integer
data:
type: array
items:
type: object
properties:
title:
type: string
published_at:
type: string
format: date
author:
type: object
properties:
name:
type: string
body:
type: string
And then in our paths.yaml file:
/articles:
get:
$ref: ./articles/paths/article-index.yaml
In the example above we have defined a summary of the endpoint, the available parameters, and the output schema. Path operations also inherit the consumes and produces field that we defined at our root level spec. We can also override them here if we’d like.
Extracting reusable components
We can, and should, clean this up. You’ll notice there are some structures here that would be useful to abstract and make reusable such as pagination query parameters, metadata pagination output, and the article entity output. Extracting these structures into a reusable structure not only saves time, but allows us to maintain them in one place, rather than in every instance that they occur.
OpenAPI makes defining reusable parameters easy. Add a file called parameters.yaml to the root spec directory.
pageParam:
name: page
in: query
required: false
type: integer
limitParam:
name: limit
in: query
required: false
type: integer
Then link it api.yaml like paths.
parameters:
$ref: ./parameters.yaml
To reference the objects defined here, you can reference them like so:
- $ref: '#/parameters/pageParam'
So the parameters section of article-index.yaml now looks like this:
parameters:
- $ref: '#/parameters/pageParam'
- $ref: '#/parameters/limitParam'
We start the ref with a # to denote it is an internal reference. Since the files resolve external references first, all of our definitions will be in the same file as our paths, so we can reference them internally.
Now we need to extract our Post definition into its own schema file. According to the Open API Specification Version 2: “Models are described using the Schema Object which is a subset of JSON Schema Draft 4.”
Models may be a subset of JSON Schema, but as far as I can tell, you cannot directly work with JSON Schema objects in Open API v2. I wanted to use JSON Schema to define a single source of truth for our models, and import them into our Open API spec, but the current tools do not allow it with version 2. The awesome people over at WeWork have built Speccy to work with this type of setup with Open API v3, but unfortunately we are not using version 3 (We’ll get into the reasoning behind this later).
So for now, we will simply use the Open API spec to define our models. I’d love to come back to this and explore JSON Schema more when there’s a viable route to do so.
Create a file called article.yaml in spec/articles/schemas
type: object
properties:
id:
type: integer
title:
type: string
published_at:
type: string
format: date
body:
type: string
author:
$ref: '#/definitions/Author'
Now a file called author.yaml in the same folder.
type: object
properties:
id:
type: integer
name:
type: integer
required:
- id
- name
Now create a file called definitions.yaml in the spec/ directory.
Article:
$ref: ./articles/schemas/article.yaml
Author:
$ref: ./articles/schemas/author.yaml
And link the definitions file in your root spec like we did with the paths and parameters files.
definitions:
$ref: ./definitions.yaml
Now we can reference the models in our path operation like so:
responses:
200:
description: 'Articles returned successfully.'
schema:
type: object
properties:
meta:
type: object
properties:
page:
type: integer
total:
type: integer
last_page:
type: integer
limit:
type: integer
data:
type: array
items:
$ref: '#/definitions/Article'
We could extract the meta object in the same way. Create a shared/ module in the root spec and add a schemas folder with a file called pagination.yaml
type: object
properties:
page:
type: integer
total:
type: integer
last_page:
type: integer
limit:
type: integer
And the final path operation looks like this:
summary: 'Return a list of articles.'
tags:
- Articles
parameters:
- $ref: '#/parameters/pageParam'
- $ref: '#/parameters/limitParam'
responses:
200:
description: 'Articles returned successfully.'
schema:
type: object
properties:
meta:
$ref: '#/definitions/Pagination'
data:
type: array
items:
$ref: '#/definitions/Article'
Much cleaner! There are definitely aspects to this flow that could be improved, but I believe this is a good pattern for building a scalable and maintainable API spec.
Documentation with ReDoc
Now that we have our basic spec, let’s generate some documentation! Using ReDoc, we can turn our spec into clean, easy to read docs. First, grab redoc-cli by running
npm install -g redoc-cli
Then add the following to the scripts section in the package.json
"serve-docs": "redoc-cli serve spec/dist/api.yaml --watch"
You can now serve up your docs by running
npm run docs
Navigate to http://127.0.0.1:8080 and you should see something like this:

Easy
Testing your spec
To me, being able to test your spec against your API, and integrate that process into your CI/CD is one of the biggest benefits to having a spec in the first place. The only tool I’ve seen that does this is Dredd, and it is the reason I suggested using Open API v2.
Dredd does not yet have Open API v3 support, and a ticket has been open to add it for over a year. I’m not sure when to expect it, and given that there are tools to help convert from Open API v2 to v3, I think sticking with v2 to gain the benefit of Dredd is worth it.
Setup
Install Dredd using NPM
npm install -g dredd
Initialize Dredd by running
dredd init
? Location of the API description document (apiary.apib) spec/dist/api.yaml
? Command to start the API server under test (npm start)
? Host of the API under test (http://127.0.0.1:3000) http://api.blog.test
? Do you want to use hooks to customize Dredd's behavior? (Y/n) Y
Go
JavaScript
Perl
❯ PHP
Python
Ruby
Rust
? Do you want to report your tests to the Apiary inspector? (Y/n) n
? Dredd is best served with Continuous Integration. Do you want to create CI configuration? (Y/n) N
Make sure you’ve configured your app to be served at http://api.blog.test, or replace this with the location of your Laravel app. Next, go ahead and install the Dredd PHP hooks with
composer require ddelnano/dredd-hooks-php --dev
We can use these hooks to configure our application for test mode when Dredd runs. For now though, let’s see what happens when we run Dredd:
info: Configuration './dredd.yml' found, ignoring other arguments.
info: Beginning Dredd testing...
fail: GET (200) / duration: 248ms
fail: GET (200) /articles duration: 36ms
I’ve truncated the rest of the output due to length, but as you will see, all of our tests are failing! With each failure you get the request, the expected output, and the actual output, Since we haven’t changed anything in our actual application, it doesn’t reflect what we have specced out! Let’s fix this with mocked responses.
Our first path
The first path we added to our spec was the root endpoint to display our application version. It produces JSON and should output a version number. Let’s look at what Dredd tells us about this path:
request:
method: GET
uri: /
headers:
Content-Type: application/json
Accept: application/json
User-Agent: Dredd/5.2.0 (Linux 4.15.0-38-generic; x64)
body:
expected:
headers:
Content-Type: application/json
statusCode: 200
actual:
statusCode: 200
content-type: text/html; charset=UTF-8
Again, I’ve truncated this as there’s tons of output, but you can see it expects a 200 response with the application/json mime-type, but it actually received a 200 response with text/html. We can quickly fix this by replacing the welcome view in the route with a JSON response like so:
Route::get('/', function () {
return response()->json([
'name' => 'Blog API',
'version' => '1.0'
]);
});
If we re-run our tests we see that it now passes!
The articles endpoint
If we look at our next test we will see that it is also failing.
fail: GET (200) /articles duration: 38ms
fail: statusCode: Status code is '404' instead of '200'
The route doesn’t exist, so let’s add it by adding an entry to our routes file.
Note: We would not want to put any of this directly in our routes file, it's just easier to demonstrate this way.
Route::get('/articles', function () {
});
If we re-run Dredd, we get the following output
fail: GET (200) /articles duration: 74ms
fail: headers: Header 'content-type' has value 'text/html; charset=UTF-8' instead of 'application/json'
We get a 200 now, but the content-type is invalid. Let’s return a JSON response and see what happens.
Route::get('/articles', function () {
return response()->json([]);
});
And now Dredd tells us…
fail: GET (200) /articles duration: 71ms
fail: body: At '' Invalid type: array (expected object)
We are returning the correct status code and content-type, but the actual response is being marked as invalid by Dredd. Let’s look at documentation to see what Dredd is expecting:
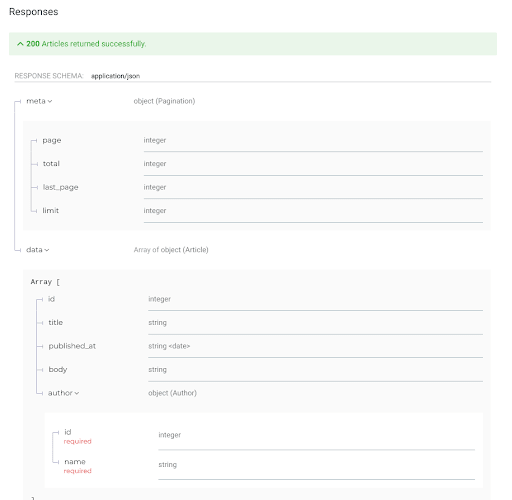
We can see that our response should be an object with a meta and data properties. Meta should contain a Pagination object as we defined in our schema, and the data property should be an array containing Article objects. Dredd validates that our API is returning the correct data structure, so let’s mock what one would look like:
Route::get('/articles', function () {
return response()->json([
'meta' => [
'page' => 1,
'total' => 1,
'last_page' => 1,
'limit' => 10
],
'data' => [
[
'id' => 1,
'title' => 'My Article Title',
'published_at' => '2018-11-13',
'body' => 'My article body',
'author' => [
'id' => 1,
'name' => 'Test'
]
]]
]);
});
If we run Dredd, we can see all of our tests now pass!
info: Configuration './dredd.yml' found, ignoring other arguments.
info: Beginning Dredd testing...
pass: GET (200) / duration: 174ms
pass: GET (200) /articles duration: 22ms
complete: 2 passing, 0 failing, 0 errors, 0 skipped, 2 total
complete: Tests took 198ms
This is the ultimate safeguard from documentation rot! You can, and should, set up measures to prevent deployments unless your spec matches your actual API. This kind of protection around your spec is invaluable.
Other tools
ReDoc and Dredd are only the beginning in terms of what you can do with your new specification. There are tools that let you generate validation rules, client libraries, mock servers, and more!
Summary
This article ran a bit longer than I meant it to, and I didn’t even touch on everything I wanted, so I may be writing a follow-up sometime in the future. In the meantime, please feel free to share any questions, comments, or suggestions in the section below! Thanks for reading!
The post API Specifications and Laravel appeared first on Matt Does Code.





Top comments (0)