
Branching
Branching out is a common first step as you work on a new task. git checkout -b 'name of your brand new branch' should be familiar for most of you. This routine keep root branch (master/ develop whatever) clean, until someone finishes her/his work. Then you have to somehow put your changes into the root branch.
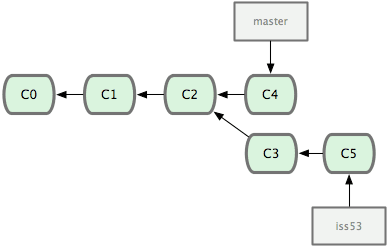
Merge
The default strategy, for integrating changes into a root branch is merge operation. Of course, if you meet any conflicts, you have to resolve them, but finally, the code base will be integrated.
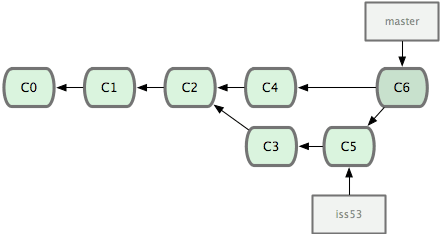
Squash
There is an option while merging changes, to use --squash. You will end up with one merge commit, put on top of the root branch history. From my perspective, this method is really risky. When a team does not stick to the pull requests/branch naming convention, it can have dramatic consequences. Imagine going back in the repository history through commit named update, align with newer version, test, more tests, etc. This option will simplify history view, but it is only for mature teams.
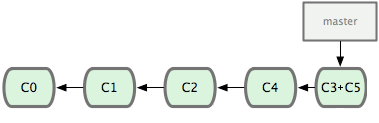
Mix
While I was doing a research for this article, I found this. A really nice mix of the merge and squash in a single approach. Again, here you will need a mature team, to follow the naming convention, but is a nice consensus.
Question?
Personally, I prefer to use standard merge. I have met teams, which use a --squash option for all of the feature branch merge and I can see the pros of this approach. I miss detailed git history in that scenario after all. What is your default merge strategy?
Images source: git-branching-and-merging





Top comments (8)
Personally, I use Github for merging pull requests and protect the main branch, that way people can't sneak bits of code in. On personal projects, I follow the same way. It means I have a place in time on the web where I can view the changes, and look back at the code :) I squash by default to keep the main branch tidy.
Do you squash on your commercial work also? How about rolling back in history in case of any mistakes/bugs?
Yeah, I squash in my commercial work too. Especially there :P mostly there's no need to roll back - and anything can be picked/rolled back when I'm not sure about it as a single commit. How you organise your work - small pieces of functionality, easy to understand, covered with 100% unit test coverage - means the need to roll back is pretty much non existent, and it is very unlikely that you would have a low understanding of why what you have created has caused a bug.
If you are working alone, that this is true. In larger teams, when you can get messy repo/feature branch then, in my opinion, is better to have more granular commits :)
I have worked in FE projects with 30+ people contributing to a single repo, it worked fine for us :)
Nice, I am a little jealous.
Merge commit, no squash. I work to communicate through my commits, so I would git frustrated loosing all that work to group my work into isolated changes.
Take it on a case-by-case basis but typically I'd rather not auto-squash anything unless it only handles commit messages explicitly prefixed with
fixup!orsquash!. If a feature has multiple commits, I tend to believe it's because the developer did the work in logical stages that are separate enough to be units of work that could possibly get reverted independently of the rest of the changes in the branch.Certainly have your developers do any final interactive rebasing and manual squashing/fixing up before merging the pull request though.