
Introduction
Before getting started, here are the following things you’ll learn in this post :
- What labeling functions are and how you can implement them
- How to improve your weak supervision using active learning and zero-shot modules
- How to use lookup lists to easily manage keyword- and regex-functions
- What other options do you have to automate your labeling using existing resources
- If you want to dive deeper into weak supervision, check out our other blog post 👉🏼 https://www.kern.ai/post/automated-and-denoised-labels-for-nlp-with-weak-supervision
The basic heuristic
We’ll start with the basics of weak supervision, such as labeling functions. Essentially, these are noisy functions that will generate some label signal. They can be super simple keyword/regex functions, complex formulas, and deep domain knowledge. For instance, imagine the following function to detect positive sentiment in some text:
def lkp_positive(record: Dict[str, Any]) -> str:
my_list = [“:-)”, “awesome”, ...]
for term in my_list:
if term.lower() in record[“text”]:
return “positive”
Their most significant advantage is explainability and maintenance, and It is straightforward to implement them. With our automated heuristic validation, you can quickly build labeling functions, grow their coverage, and estimate their performance.
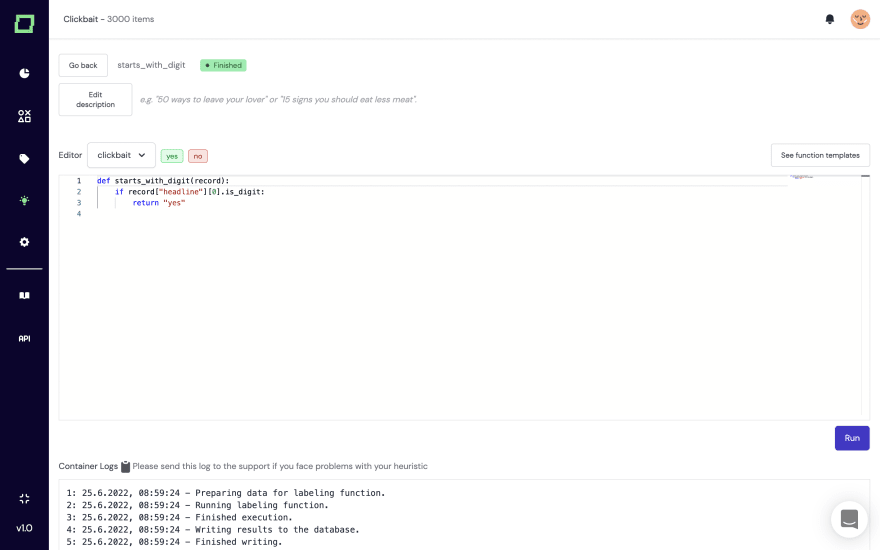
Learning heuristics from few reference training data
Of course, we’re not limited to only labeling functions. Especially with the availability of large-scale pre-trained language models such as those from Hugging Face, you can integrate active transfer learning into the weak supervision methodology. You must typically label ~50 records per class to get some promising initial results.
In active transfer learning, you compute the embeddings (i.e., vector representation) of a text once and perform training on lightweight models like logistic regression or conditional random fields. This works for both classifications and extraction tasks like named entity recognition.
With kern.ai, it comes with a very easy-to-use interface. Within three clicks, you can select your language model and build models in a Python IDE similar to Scikit-Learn. Also, the IDE comes with several options for training in such a way that you can, for instance, filter specific classes or pick a minimum confidence level. Applying active transfer learning to your task is always a great idea.
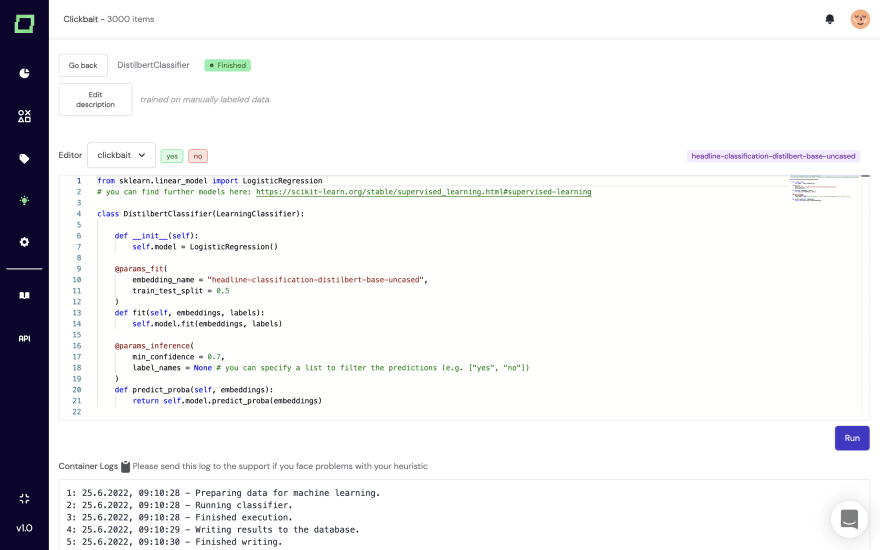
To learn more about active transfer learning, check out our blog posts 👉🏼 https://www.kern.ai/post/6-1-types-of-heuristics-to-automate-your-labeling-process
Learning from label definitions
There are also options in the field of zero-shot that you can apply as heuristics. In zero-shot scenarios, you typically try to examine any information from high-level metadata such as the label names and potential descriptions to provide a pre-trained model with some context to infer predictions.
Even though this field is still under a lot of active research (see also for reference the term “Prompt Engineering”), it is already beneficial in practice, and you can use zero-shot as a great off-the-shelf heuristic for your project. For instance, if you have some news headlines for which you want to apply topic modeling, a zero-shot model can yield promising results without any fine-tuning. However, keep in mind that such models are enormous and computationally expensive, so it typically takes some time to compute their results. They are definitely much slower than active transfer learning or labeling functions.
Our software currently provides a very simplistic zero-shot interface for classifications. We currently don’t integrate prompt engineering but will do so in the future.
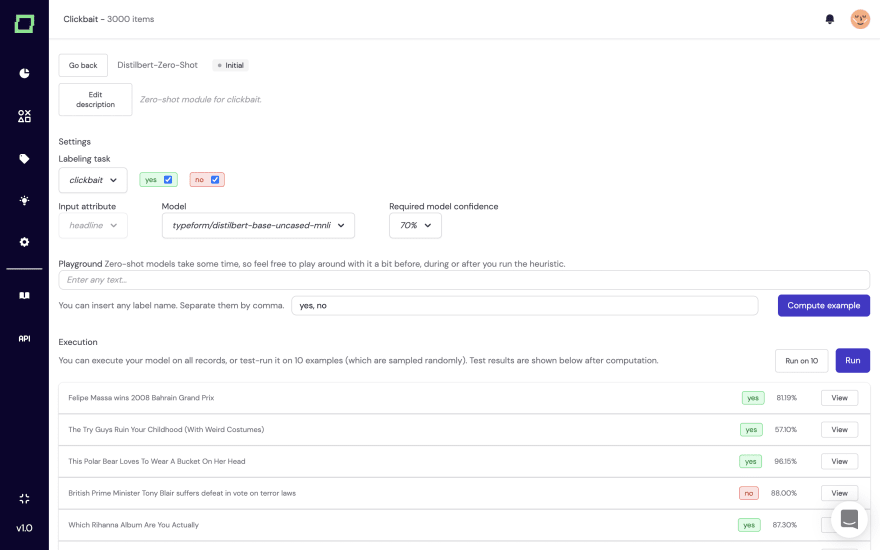
3rd party applications and legacy systems
Another valid option for heuristics is external heuristics, such as other applications in a similar domain. Let's say we want to build a sentiment analysis for financial data - a sentiment analysis from providers like Symanto is a tremendous external heuristic to quickly gain logical power from their systems.
We're extending our API to enable you to integrate any heuristic you like. Don't forget to subscribe to our newsletter here (https://www.kern.ai/pages/open-source) and stay up to date with the release, so you don't miss out on the chance to win a GeForce RTX 3090 Ti for our launch
Manual labeling as a heuristic
Maybe now you’re thinking about whether to include crowd workers or, in general, human annotators - well, of course, you can! The great thing about weak supervision is its generic interface through which you can integrate anything as a heuristic that fits its interface.
Manual labeling is especially useful if you want to label some critical slices. In Kern, you can easily filter your records to create slices with ease, which you can then manually label.
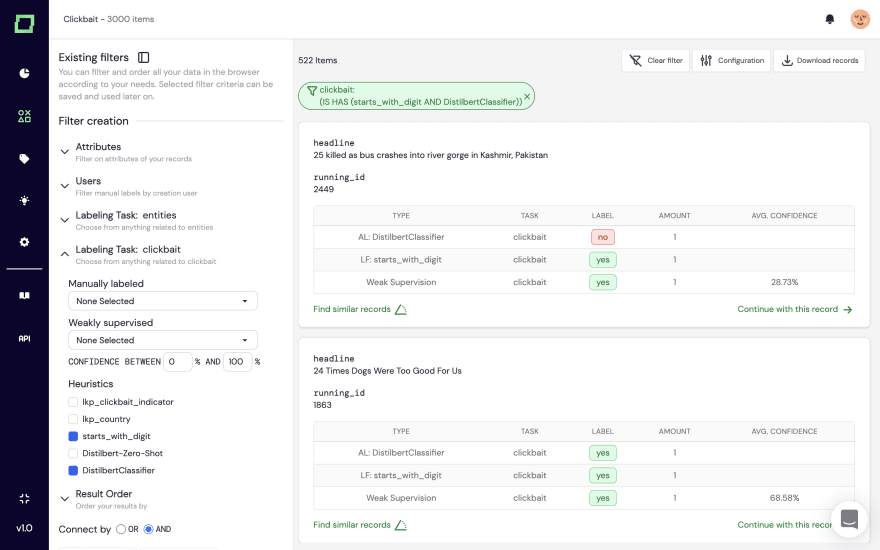
Their integration will also be enabled via API, so there will be no difference between the integration of 3rd party apps and manual labeling for heuristics.
Lookup functions
For label functions, you often implement keyword- or regex-based pattern matching. Those functions are super helpful, as they are easy to implement and validate. Nevertheless, maintaining them can become quite tedious, as you don’t want to constantly append to some list in a labeling function. Because of this, we created automated filling of lookup lists (also called knowledge bases) in your projects based on entity labeling.
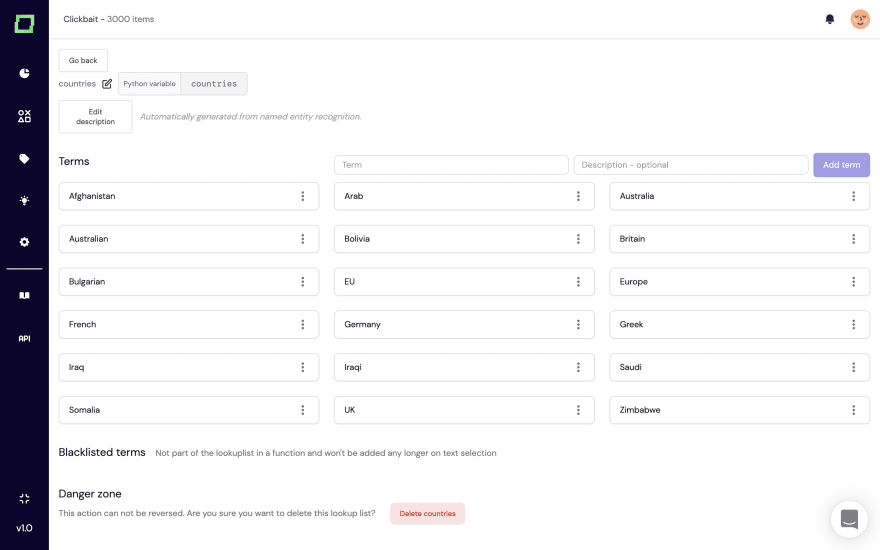
Those lists are super easy to create and are linked to Python variables. Once created and filled, you can integrate them into your functions as follows:
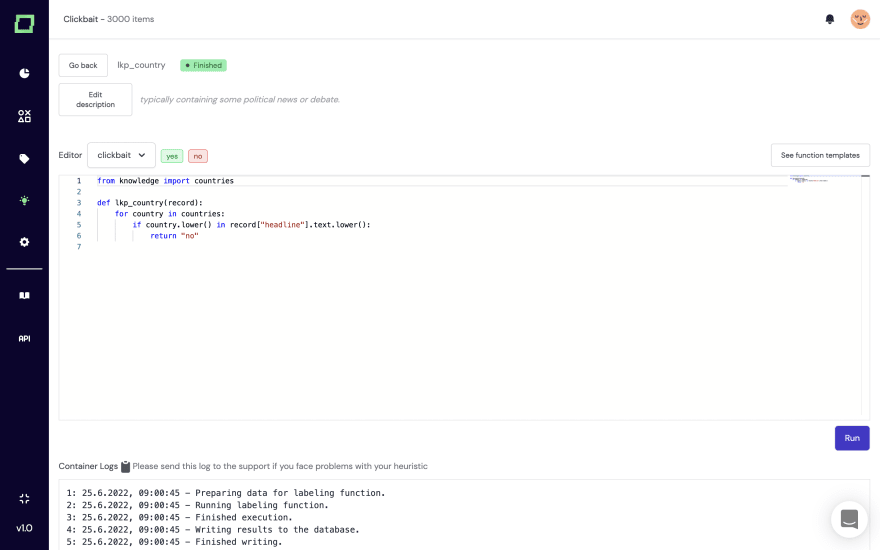
Afterward, you don’t have to touch any other code in this function to maintain your heuristic. Instead, you can work on the function only via the lookup list. That’s easy, isn’t it?
Templates for labeling functions
As a last additional type, we want to show you some cool recurring labeling functions. They are available in our templates repository, so feel free to check them out - and if you want to add your own, please let us know. You can create an issue or fork the repository anytime.
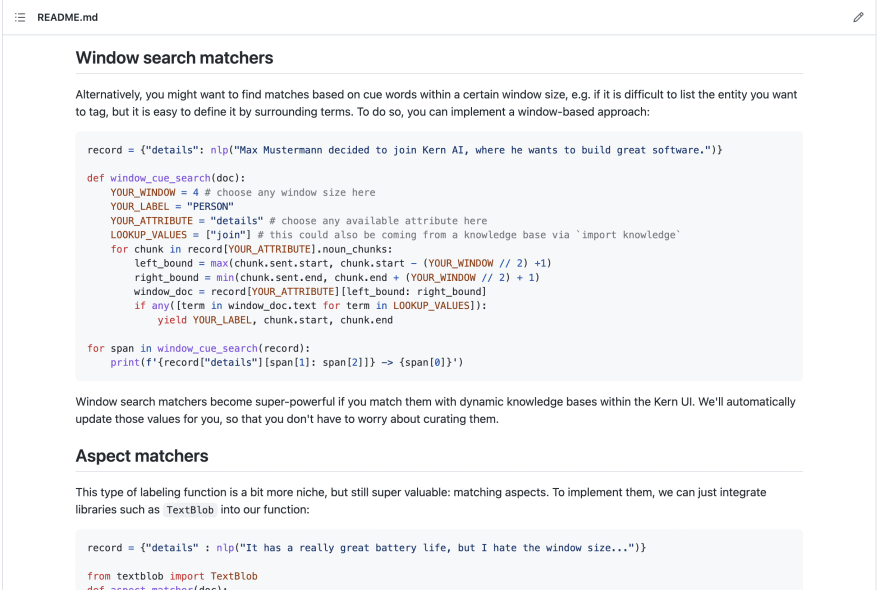
For classifications, you can often integrate libraries like spaCy to use pre-computed metadata. For instance, you can just check the grammar or named entities of sentences and label your data accordingly. Another typical option is to use TextBlob for sentiment analysis:
from textblob import TextBlob
def textblob_sentiment(record):
if TextBlob(record["mail"].text).sentiment.polarity < -0.5:
return "spam"
If you’re building labeling functions for extraction tasks, you need to adapt the return statement a bit. In general, entities can occur multiple times within a text, so you yield instead of return. Also you need to provide the start and end of a span. Similar to the above function, you could use TextBlog in an extraction function to find positive and negative aspects in a review like this:
from textblob import TextBlob
def aspect_matcher(doc):
window = 4 # choose any window size here
for chunk in record[“details”].noun_chunks:
left_bound = max(chunk.sent.start, chunk.start - (window // 2) +1)
right_bound = min(chunk.sent.end, chunk.end + (window // 2) + 1)
window_doc = record[“details”][left_bound: right_bound]
sentiment = TextBlob(window_doc.text).polarity
if sentiment < -0.5:
yield “negative”, chunk.start, chunk.end
elif sentiment > 0.5:
yield “positive”, chunk.start, chunk.end
We’re going open-source, try it out yourself
Ultimately, it is best to just play around with some data yourself right? Well, we’re launching our system soon that we’ve built for more than the past year, so feel free to install it locally and play around with it. It comes with a rich set of features like integrated transformer models, neural search and flexible labeling tasks.
Subscribe to our newsletter 👉🏼 https://www.kern.ai/pages/open-source, stay up to date with the release so you don’t miss out on the chance to win a GeForce RTX 3090 Ti for our launch! :-)





Top comments (0)