ChatGPT is based on the GPT (Generative Pre-trained Transformer) series of language models developed by OpenAI.
In this demo, I leverage the power of AWS S3, AWS Lambda, Amazon Textract, and OpenAI’s ChatGPT to seamlessly process images containing text and generate intelligent, context-aware responses. By combining cutting-edge OCR (Optical Character Recognition) technology with advanced language understanding, this solution offers a unique way to interact with visual data.
Note: This demo is assuming basic knowledge on Core AWS services, so details for S3 bucket creation, AWS Lambda creation, AWS VPC creation and AWS IAM role creation are omitted.
Use cases:
- Image to text processing that requires integration with ChatGPT
- Image to text processing integration with Chatbot solution
Chapters:
- General Topology
- Image to text convertion
- Text to ChatGPT integration
- Conclusion
- Next steps ##### Services involved in this demo
- AWS S3
- AWS Lambda
- AWS Textract
- AWS Cloudwatch
- AWS VPC
- AWS NAT Gateway
- AWS Internet Gateway
- OpenAI ChatGPT API
1. General Topology
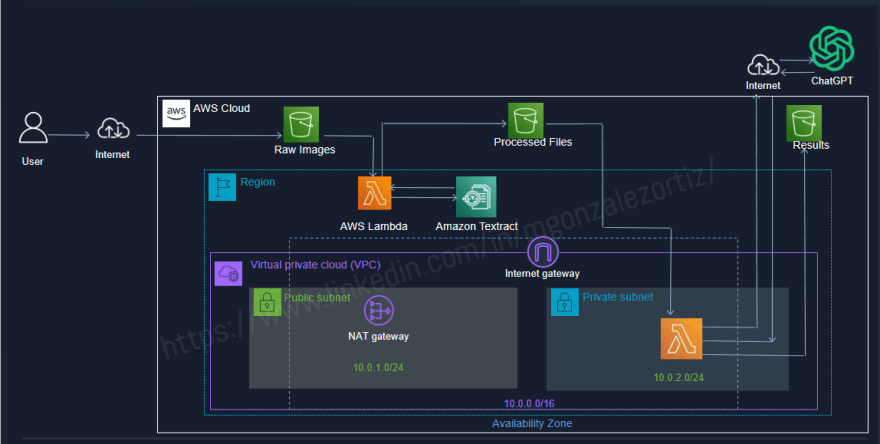
2. Image to text convertion
Steps:
- Create 2 S3 buckets in the same region AWS Lambda will be created.

chatgpt-demo-1 : S3 bucket to store images containing text
chatgpt-demo-1-text : S3 bucket to store extracted text
- Create an AWS Lambda function (runtime Python 3.9) with the following topology

- Trigger: S3 trigger will notify AWS Lambda to start function execution when the PUT event type is executed for any file with the "raw_data" prefix. Alternative, you can select a suffix such us .jpg, .png, .pdf if you want to restrict the source files per file type.

Layer: ZIP archive that contains libraries, a custom runtime, or other dependencies. For this demo, I added a AWS SDK for Python (Boto3) as a zip file for all functions in this demo. You can refer to this link for more details on Layer benefits for AWS Lambda functions: https://towardsdatascience.com/introduction-to-amazon-lambda-layers-and-boto3-using-python3-39bd390add17
Permissions: AWS Lambda function should have permission to the following services: AWS S3, AmazonTextract and AWS CloudWatch. Following image is an example of this setup

- Environment Variable: This is an optional setup but truly useful in case you don't want to depend on fixed values, but have the freedom to quickly update AWS S3/API-gateway/etc information within your code.
Environment Variable for destination S3 bucket

- Lambda Code: The following code objective is to collect the image from source S3 bucket, call AmazonTextract API service to extract the text within the image and store the result in a .txt file with "_processed_data.txt" suffix and store in a target S3 bucket.
import json
import boto3
import os
import urllib.parse
print('Loading function')
s3 = boto3.client('s3')
# Amazon Textract client
textract = boto3.client('textract')
def getTextractData(bucketName, documentKey):
print('Loading getTextractData')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': bucketName,
'Name': documentKey
}
})
detectedText = ''
# Print detected text
for item in response['Blocks']:
if item['BlockType'] == 'LINE':
detectedText += item['Text'] + '\n'
return detectedText
def writeTextractToS3File(textractData, bucketName, createdS3Document):
print('Loading writeTextractToS3File')
generateFilePath = os.path.splitext(createdS3Document)[0] + '_processed_data.txt'
s3.put_object(Body=textractData, Bucket=bucketName, Key=generateFilePath)
print('Generated ' + generateFilePath)
def lambda_handler(event, context):
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
detectedText = getTextractData(bucket, key)
writeTextractToS3File(detectedText, os.environ['processed_data_bucket_name'], key)
return 'Processing Done!'
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
Text to ChatGPT integration
- Create 1 additional S3 bucket in the same region AWS Lambda will be created.

chatgpt-4073-output : S3 bucket to store ChatGPT answer in .txt format
2.Create a VPC with 2 subnets (1 private subnet, 1 public subnet), an Internet Gateway and a NAT Gateway AWS will be deployed.

3.Create an AWS Lambda function (runtime Python 3.9) with the following topology
- Trigger: S3 trigger will notify AWS Lambda to start function execution when the PUT event type is executed for any file with the "_processed_data.txt" suffix.

Permissions: AWS Lambda function should have permission to the following services: AWS S3 and AWS CloudWatch.
VPC: For this AWS Lambda function, we will create within the new VPC, in the private subnet. Access to Public GhatGPT API will be done through NAT-Gateway.
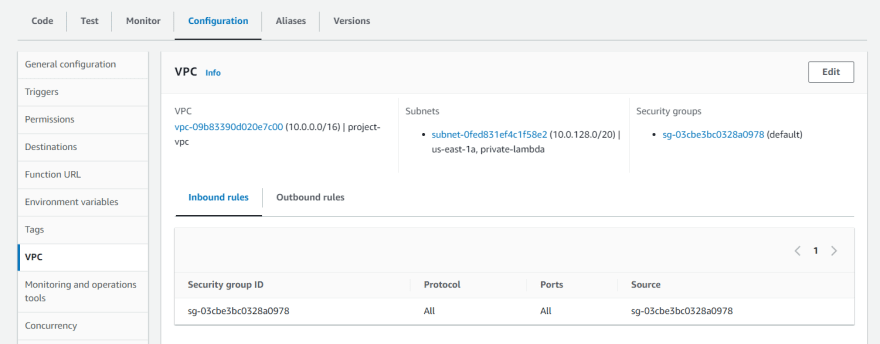
Environment variables: In order to make an API call to Public API webservice, the following variables were define:
- model_chatgpt : Selected ChatGPT model for text processing
- openai_secret_key_env: Security Key to authenticate API call user
- output_bucket_name: AWS S3 bucket to store results in .txt file.
4.A big kudos to my friend Prakash Rao https://www.linkedin.com/in/prakashrao40/), who is the creator for the following Python script
import os
import json
import boto3
import http.client
import urllib.parse
s3 = boto3.client('s3')
def lambda_handler(event, context):
# Get the uploaded file's bucket and key
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# Read the text file from S3
file_content = s3.get_object(Bucket=bucket, Key=key)['Body'].read().decode('utf-8')
# Store the file content in a Python JSON
file_json = {'text': file_content}
# Read OpenAI API credentials from environment variables
openai_secret_key = os.environ['openai_secret_key_env']
# Set up HTTP connection to OpenAI API endpoint
connection = http.client.HTTPSConnection('api.openai.com')
# Define request parameters
prompt = file_json['text']
model = os.environ['model_chatgpt']
data = {
'prompt': prompt,
'model': model,
'max_tokens': 50
}
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {openai_secret_key}'
}
# Send API request and parse response
connection.request('POST', '/v1/completions', json.dumps(data), headers)
response = connection.getresponse()
response_data = json.loads(response.read().decode())
completion_text = response_data['choices'][0]['text']
# Print generated text
#print(completion_text)
# Define the output bucket and output key (file name)
output_bucket = os.environ['output_bucket_name']
output_key = f"{os.path.splitext(os.path.basename(key))[0]}_chatgpt_result.txt"
# Upload the generated text to the output S3 bucket
s3.put_object(Bucket=output_bucket, Key=output_key, Body=completion_text)
# Return response to API Gateway
return {
'statusCode': 200,
'body': json.dumps({'text': completion_text})
}
5.Once integration is completed, the S3 bucket will store the results. In addition, you can refer to AWS Cloudwatch Logs > Log groups to check the details of API calls and results.
Conclusion:
Existing AWS serverless services such as Amazon Textract, Amazon Comprehend, Amazon Lex and others are great candidates to integrate with OpenAI ChatGPT. In this demo, I wanted to show how easy this integration can be achieved without exceeding our budget.
Nex steps:
- Integrate AWS Lambda to AWS Secret Manager for credentials
- Add AWS SNS Service for multiple uploads
- Improve existing ChatGPT model
Happy Learning!





Top comments (0)