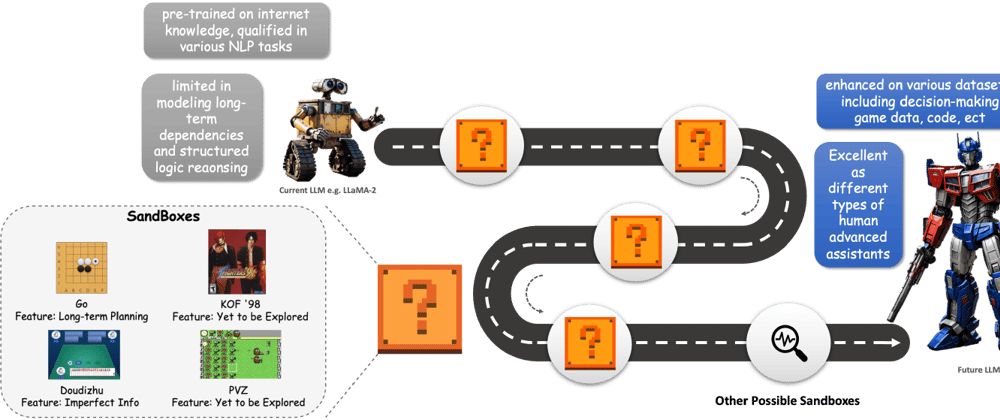
This is a Plain English Papers summary of a research paper called AI Decision-Making Breakthrough: New Training Method Boosts Performance 34% in Strategic Games. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- New algorithmic data synthesis method improves LLM decision-making abilities
- Research combines game theory and LLM training techniques
- Shows 34% performance gain in complex decision games
- Method automatically generates high-quality training examples
- Demonstrates improved transfer learning to new scenarios
- Requires no human annotations or demonstrations
Plain English Explanation
Most large language models (LLMs) struggle with complex decision-making tasks. They can write essays and answer questions, but when faced with strategic situations requiring careful planning or reasoning about others' actions, they often fall short.
The researchers developed a...


Top comments (0)