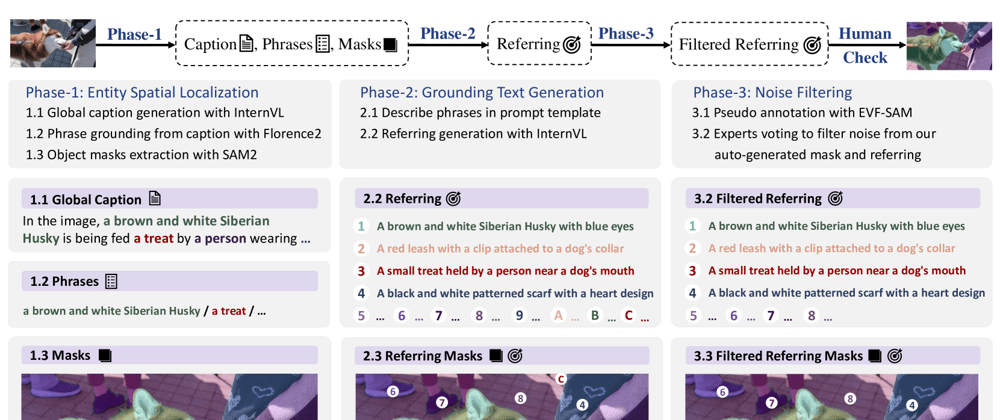
This is a Plain English Papers summary of a research paper called New Benchmark Shows AI Still Struggles to Precisely Identify Objects in Images Based on Text Descriptions. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- GroundingSuite introduces a new benchmark for evaluating pixel grounding capabilities
- Measures how well AI models can identify specific pixels in images based on language descriptions
- Includes 8 diverse datasets covering detection, segmentation, and complexity levels
- Evaluates models' abilities to handle difficult grounding challenges like distinguishing similar objects
- Tests cross-dataset generalization and multi-granular understanding
- Shows significant performance gaps in current state-of-the-art models
Plain English Explanation
Computer vision systems need to understand exactly what we're referring to when we point out objects in images using natural language. This ability, called "pixel grounding," is cruci...

Top comments (0)