YouTube it the second most visited website in the internet nowadays. Almost five billions of videos in the platform are watched everyday. Three hundred hours of new content is uploaded on it every single minute! That makes not only maintaining a website with such massive scale already a very difficult task, but creating models that use that information, like their video recommendation system, a much bigger challenge, and that's what I'll go through a little today. For that, I'll be following the structure of their paper in the subject.
Challenges
These are just some of the challenges the systems has to take into consideration:
- Scale: As mentioned before, Youtube has a huge user base and a massive corpus to handle. Though there are systems that offer good solutions for smaller scale projects, they might fail to operate in large scale platforms.
- Freshness: This means balancing older video recommendations with the thousands of videos being uploaded in the platform every minute.
- Noise: With just a like function and comment section that most users don't use, it's hard to determine user satisfaction if you don't have more information than viewed or not viewed. This issue can add a lot of noise to the data.
Youtubes solution to these problems was to use deep learning to deploy a Neural Network for their recommendation system, implemented using TenserFlow. Their model has roughly one billion parameters, and is trained in hundreds of billions of examples!
Neural Networks

Just to touch this briefly, a Neural Network is a computer system inspired by how the human brain operates. The image above shows the the input layer, where data is injected in the model, then a couple of hidden layers. There can be many of those, and they try to identify underlying relationships in the data. Models can have one output or, as in the Youtube case, several, which represent their recommended videos.
How does it work?
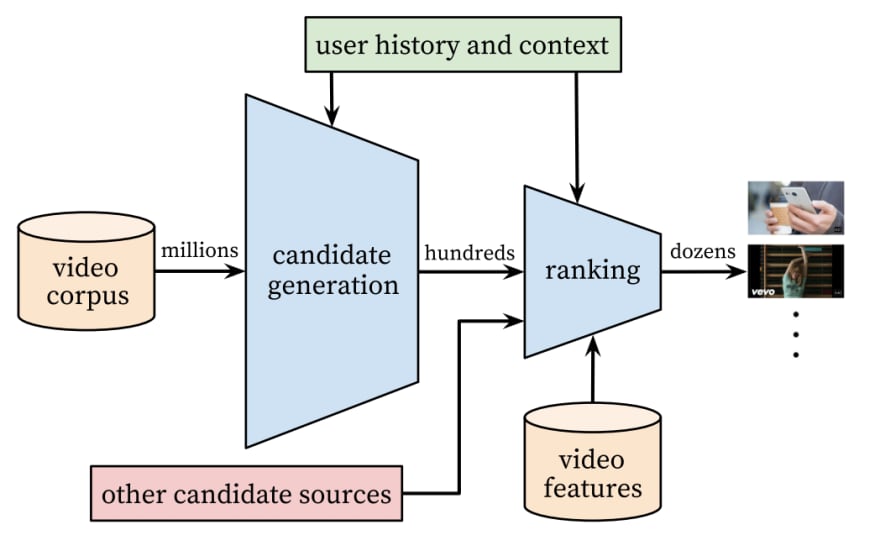
The flow chart above shows the structure of the recommendation system. There are two Neural Networks here: the candidate generation and the ranking. The first phase selects a few hundred videos from Youtube corpus based on the user activity. The ranking phase filters videos based on their scores.
Candidate Generation
Though this post is not going into technical details of how these systems work, I'll point out that the candidate generation system uses the softmax classifier, which is used for multi-class classification problems, and uses just implicit feedback to give it's results, meaning that instead of using features like the thumbs up/down, it relies on length of watches in it's algorithm. To address some of the challenges posed earlier, these were some of the decisions made in the system:
- The age, or how old a video is, is made into a feature and set very close to zero in the training data. This means that though age has a weight in the recommendation, it's won't disproportionally reward older videos, which have more clicks and views.
- Feature engineering was made to increase the model precision. Experiments with a vocabulary of a million videos and a million search tokens, embedded in a bag of maximum size of 50 recent watches and 50 recent searches substantially increased the model mean average precision in relation to one without these features.
- Have fewer inputs from each user in the model. Withholding signals helps prevent the model overfitting and increases precision.
Ranking
In this part the system has to find a way to evaluate which videos users are watching and how much are they enjoying them.
Historical data, or which videos the user has watched in the past, has a big weight here. If users watch a specific kind of content, it's likely they'll watch more of that content. If the suggested videos from the same content are not being clocked on though, they start to lose importance. You can assess this change by searching for a 'How to fix bicycle's breaks' for instance. After you've seen one or two of those, you'll be suggested more of that content, but as you interact more with Youtube and don't click on those recommendations, they start losing weight and are suggested less and less.
The actual ranking of the videos is a measure of how long the user is going to engage with the video. The more the user watches the video, the higher it's ranking gets. Interestingly enough, this method does not take into account the length of the video.
For this prediction, the authors decided to use Weighted Logistic Regression. The weight it includes in the calculation is upon the positive impressions, or the clicked videos, and is calculated as the sum of the watch time of all impressions.
The resulting output here are videos, that have been selected regarding user preferences, then selected amongst themselves, in order of how likely it is that that video is going to be watched by the user. The amount of time this process takes is in the tens of milliseconds, which is an incredible feat.
Conclusion
The model briefly described here consisted on splitting the recommendation problem in two: candidate generation and ranking. It manages to assimilate constant incoming signals and model them using several layers of depth in the neural network.
Some of the unique feats of this system are:
- Withholding signals from the classifier to prevent overfitting.
- Using age as an input feature to remove bias towards the past.
- Layers of depth were shown to effectively model non-linear interactions between hundreds of features.
- Modifying Logistic Regression to weight watch time for positive examples.
Steve Jobs put it clearly when he said "People don't know what they want until you show it to them." Recommendations of videos on Youtube, pages on Google, products on Amazon or music on Spotify are all trying to figure out in what you are interested in and maximize your engagement with their platforms. It can lead people to discover things they never thought to search for, or can direct people like myself, a beginner in the field of data science, to more and precise information regarding what I'm trying to learn. I'm looking forward to assimilate the mathematical intricacies behind models like this and find out how they can be tweaked and modelled.
References:
- Scientific Paper by Paul Covington, Jay Adams and Emre Sargin
- Youtube presentation by Paul Covington
- On YouTube’s recommendation system
- Implementing the YouTube Recommendations Paper in TensorFlow — Part 1
- Using Deep Neural Networks to make YouTube Recommendations





Top comments (0)