This article outlines four different strategies for organizing code: by component, by toolbox, by layer, and by kind. I think these four form a kind of hierarchy with regards to which kind of cohesion they favor and in my experience they cover most of the real-world code I’ve worked with, pleasurable and not. There are an endless number of possible strategies but I’ve (thankfully) never encountered anyone who organizes packages into projects by creation date or classes into packages by first letter.

The Whys and Whats of Organizing Code
It is a funny thing that most of the advice you will hear and read on how to develop software basically prescribes how you should organize your code, a topic that doesn’t matter to the computer. As far as the machine is concerned all this talk about coupling and cohesion is mostly irrelevant; it doesn’t care if you put all your code in a single million line method, sort your classes alphabetically, or give all your variables single letter names. Code organization is not about communicating with the computer but rather all about trying to make sure that people can understand the code well enough that they will be able to maintain and evolve it with some degree of efficiency and confidence.
“Programs should be written for people to read, and only incidentally for machines to execute.”
— Structure and Interpretation of Computer Programs by Abelson and Sussman
When a unit of code grows too large and contains too many elements it becomes hard to navigate, hard to get an overview of, and hard to understand: it becomes complex. Our main weapon against this complexity is divide and conquer: we split the unit into smaller parts which we can understand in isolation. For classes it is fairly well understood that this should be done so that we create logical objects which exhibit good cohesion and fit well in the domain model. With projects — which are separately compiled — we have to break circular dependencies and try to make sure that they expose reasonably logical and stable interfaces to other projects. On the level in between — packages in Java or namespaces in C# — there is a lot more variation and in my experience many developers chose a strategy without much consideration given to why that particular strategy should be employed.
The first three strategies described in this article can be used at either class, package, or project level while the last one — organization by kind — is more or less specific to the package level.
Strategy #1 — by Component
Organization by component minimizes complexity by emphasizing external and internal cohesion of code units, e.g. packages. The former means that the package has a minimal interface which exposes only concepts which are strongly related to the service the component provides. The latter means that the code in the package is strongly interrelated and thus strongly related to the provided service.

Perfectly isolated components
A lot can be and has been written about what constitutes a good unit of abstraction and covering even a sliver of that would make this article too long by far. Suffice to say that the SOLID principles are a great place to start learning and that practice and reflection on how things are working out and why that might be is paramount. In this article I will only cover what in my experience is the single most common reason for rampant complexity in code bases where people have actually tried to organize things by divide conquer: failure to isolate packages into components.
New units of code are often created by identifying a subset of the functionality contained in one (or more) existing packages and creating a new abstraction from the corresponding code, resulting in more but smaller units. This creates code which looks easier to digest but it is mainly window dressing until further steps are taken: the benefit of reduced total complexity doesn’t follow unless you then take the step of eliminating dependencies.

In my opinion packages which have mutual dependencies should not be considered separate units of code at all as none of them can be understood in isolation from the others. In the example above it is easy to imagine that the Graph class has a reference to a GraphStorage in which it persists itself whenever it has changed. Not only does the graph_storage package depend on a lot of details of the graph package domain model about which it should be rightfully ignorant, the packages also remain mutually dependent. The easiest dependency to eliminate is often that from the new package to the old one:

The most important reason that this is an improvement is that when reading the storage code one can now rely on the fact that the only things it need to know about that which it is storing is what is in the Storable interface.
“No client should be forced to depend on methods it does not use.”
— The Interface Segregation Principle
The next step would be to eliminate the direct dependency from the graph package to the storage package. This could e.g. be done by creating a GraphPersister interface in the former and having a higher level package inject an adapter implementation into the Graph. And once again the primary benefit would be that the exact set of storage functionality the graph package depends on would become obvious.
“…packages which have mutual dependencies should not be considered separate units of code at all…”
In theory this process might sound fairly easy but it takes a lot of experience to learn to identify suitable components and strategies for isolating them. It is quite common to start the process only to find out that you didn’t quite get the abstraction right and need to back out of the change. The rewards for properly isolating components are great however: code which is easy to understand, easy to improve, easy to test, and — incidentally — easy to reuse.
Strategy #2 — by Toolbox
Organization by toolbox focuses on external cohesion, providing a consistent toolbox which the consumer can chose from. This strategy is weaker than organizing by component as it drops the requirement for strong internal cohesion, e.g. that the constituents are all strongly interrelated. The parts of a toolbox are often complementary implementations of the same interface(s) which can be usefully chosen from or combined, rather than sharing a lot in the way of implementation.

- Collection libraries are typically organized as toolboxes with a set of complementary implementations of a set of collection interfaces with varying characteristics with regards to areas such as time complexity and memory consumption. There might also be a unifying theme to the toolbox, such as only containing disk-based data structures.
- Logging libraries are not necessarily toolboxes in their entirety but often contain a toolbox of e.g. log-writer implementations which target different destinations.
Toolboxes arise because they are convenient to the consumer and each “tool” in the box isn’t big enough to warrant its own unit even though they are technically independent. Each component in a GUI library might for example deserve its own package but giving each its own project is unnecessarily onerous. Similarly each collection implementation might fit in a single class and putting them all in individual packages would be unnecessary bureaucracy. At least in the latter case a single collection implementation which grows beyond a couple of classes should get its own package, possibly except for a thin facade for the sake of external consistency.

Toolbox with a facade for DiskList for the sake of external consistency
Strategy #3 — by Layer
Organization by layer favors workflow cohesion instead of trying to control complexity by minimizing cross-unit coupling. The code is split along layer boundaries defined by issues such as deployment scenarios or areas of contributor responsibility. This strategy is different from organization by toolbox in that layers don’t present a single, minimal, and coherent interface to the other layers but instead a wide interface with many constituents which are accessed piecemeal by the corresponding constituents of the consuming layer.

Component coupling across layers
The typical characteristic of organization by layer is that the logical coupling is stronger within the logical components that span across the layers than within the layers themselves. The most common failure mode of this strategy is that most changes require touching files across all the layers, basically the textbook definition of tight coupling.
“Given two [units of code], A and B, they are coupled when B must change behavior only because A changed.”
— The C2 wiki
Under this scenario logical intra-component dependencies end up like ugly nails driven through your supposedly decoupled layers, pulling them together into a single — often wildly complex — unit.

Layers nailed together into a single — very complex — unit
Organization by layer should be used cautiously as it often increases total system complexity rather than help control it but there are cases where the benefits it provides outweigh this drawback. In those cases it’s often worth sequestering your layer dependency into a single place in your consumer code rather than having its tendrils reach throughout the entire code base:
- Don’t let references to language resource files infiltrate your entire code base but rather map all results and errors from your internal components to language resource messages in a single place near the presentation layer.
- Don’t use the value objects generated from your JSON schema beyond your service layer, translate them into proper domain objects and calls at the earliest time possible.
Strategy #4 — by Kind
Organization by kind is a strategy which tries to bring order to overly complex units of code by throwing the parts into buckets based on which kind of class (or interface, …) it is deemed to be. In doing this it ignores dependencies and conceptual relationships and typically produces packages with names such as exceptions, interfaces, managers, helpers, or entities.
Organization by kind is different from organization by toolbox in that it drops any pretense that the classes in a package are complementary, interchangeable, and/or form any kind of sensible library when put together. Nobody that I know of are advocating using this strategy for organizing code into separate classes or projects (“here’s the class with all the string members” or “here’s the project in which we put all our exceptions”).
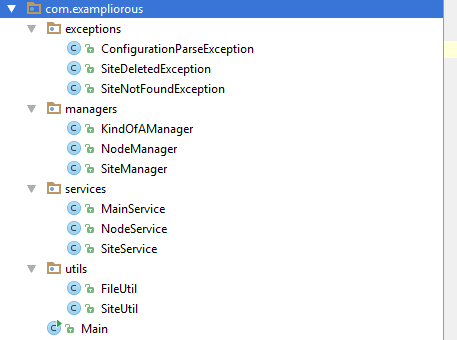
Project organized by kind
I consider organizing code by kind harmful as it hides the actual problems of complex code and thus make developers feel that they’ve fixed it while the overall complexity remains the same. The example above looks kind of neat with everything tucked into bite-sized packages but most every change requires touching every package, meaning that the packages are in fact tightly coupled. The other big problem with this strategy is that if it is taken to its extreme it requires every class to be of a clear-cut kind. I’ve seen this warp entire code-bases as all kinds of strange things get created and designated a Manager or a Helper just to fit into some package.
“…package size isn’t the main problem, the number of interdependent parts is.”
I consider organization by kind a code smell but in my experience from commercial projects — mainly in Java and C# — it is quite common. I believe that this happens because it seems to provide an easy way to partition large packages and most people aren’t aware that package size isn’t the main problem, the number of interdependent parts is.
Summary
Organizing code is a core skill for software developers and as with all skills the most effective way to improve is to reflect on your previous choices and the fallout from them. There are a wide array of different strategies for organizing code and learning to recognize both the useful and the dangerous ones is very important.
More
- This article was originally published on Medium
- InfoQ China has published a Chinese translation of this article
- This article is featured in the May 2016 issue of Hacker Bits




Top comments (0)