
Originally published at msscohen.com - a mind of a software engineer
A common code release looks like this:

System before change consists of three components

System after change: One component is replaced with an improved component.
If something goes wrong and and a rollback is possible, the rollback should replace the new production code with the old production code (replace C2' with C2). The rollback plan usually means:
- Revert the current release by committing the opposite diff to the project's version control.
- Deploy the above change to production.
- Restart the project's services to apply the new code.
- Once the rollback process is completed, additional fixes may be needed such as repairing damaged data.
The rollback process may seem trivial but when working with distributed systems, performing a commit and releasing a new version to dozens of servers may take time. This time is valuable since it is the time where a buggy production version is working which may result in more corrupted data, more data loss, additional downtime and so on.
One way to handle this situation is by applying an architectural pattern which will allow rollbacks by changing a single parameter in the project's configuration file. The following is a diagram of such architecture:

Architectural pattern adjusted for rapid rollbacks: data is copied and distributed to the old and new components using a Hub; The Switch component decides which path to enable using corresponding configuration keys.
This architecture presents two new components:
Hub: Copies and distributes traffic to several outputs. For file systems, this component will copy files to several directories; For messaging queues, this component will route messages to multiple queues (for example by using a fanout exchange); For HTTP servers, this component will copy the HTTP request and send it to multiple destinations.

Switch: Choose which source of traffic to output according to configuration. You can either implement a generic switch or apply a switch per endpoint which enables or disables each endpoint's output according to a dedicated configuration key.
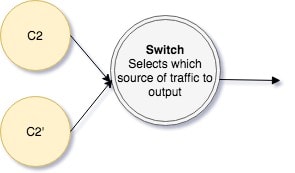
One of the advantages of this pattern is that you can deploy the new code without using it (when the switch is off), so you can test the code with real production data and stress, and activate it with a simple configuration change. Also, the hub and the switch are generic components which may be used for additional use cases.
A disadvantage of this pattern is that for small releases writing a hub, writing a switch and duplicating all incoming data might be overkill. Another disadvantage is that once the new release is stable enough, the next release should delete the of old version (C2, and possibly the hub and the switch).
I apply this pattern for either high risk changes or for large releases. In one of the biggest projects I managed, I kept the new version in production for a few months without enabling it using this pattern. During these months, we added more and more components and tested the system's behavior with live production data without affecting customers. Only when we were confident that our system was reliable, we enabled it.
Further Reading
Switch and hub components implemented in Click modular router. Click is a software architecture for building flexible and configurable routers originally developed at MIT.





Top comments (0)