Database Partitioning vs. Sharding vs. Replication
The history of partitioning, sharding, and replication dates back several decades and is closely tied to the evolution of database technology and the increasing demand for efficient handling of large amounts of data. These strategies play a crucial role in supporting modern applications and ensuring the effective management of complex datasets.
Partitioning, sharding, and replication are different strategies used to improve a database’s performance, scalability, and reliability. Each serves a unique purpose and addresses different aspects of database management.
Partitioning
Over time, tables containing large amounts of data may begin to experience performance issues with long-running queries and data manipulation (DML) operations. In these situations, dividing the dataset into smaller, more manageable parts can be an effective solution. This approach can enhance query performance, reduce storage requirements, and boost scalability by enabling parallel processing.
Database partitioning involves splitting a logical database into distinct, independent parts. By doing so, you can manage data more effectively and optimize performance in complex database systems.
There are typically two main strategies for database partitioning: vertical partitioning and horizontal partitioning.
Vertical Partitioning
Vertical partitioning refers to dividing a database table into multiple segments, each containing a subset of the columns from the original table. The main reason for using vertical partitioning is to manage columns that are frequently updated. By separating these columns into a different table or partition, you avoid updating the rest of the data unnecessarily.
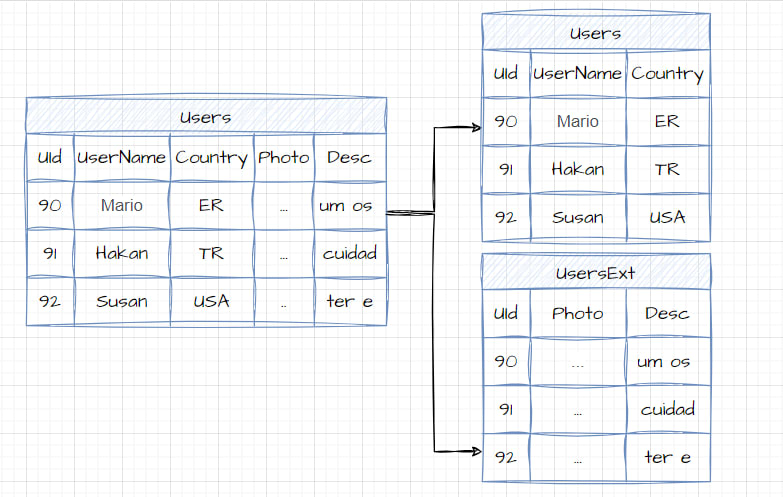
Horizontal Partitioning
Horizontal partitioning is a database optimization technique that divides a table into multiple partitions based on rows. Each partition contains a subset of the original table’s rows, which can improve query performance and manageability by distributing data across different partitions.
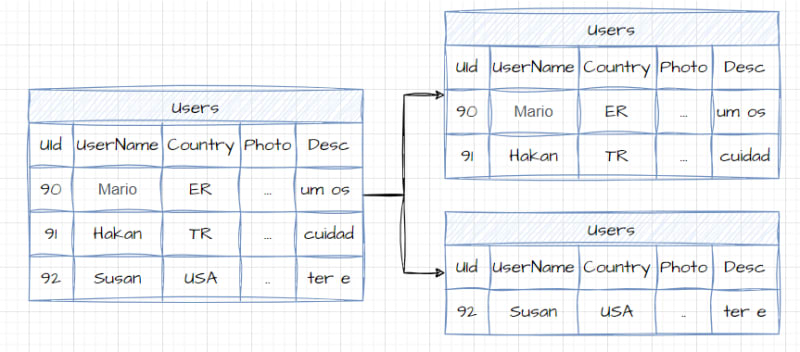
Sharding
Sharding is a subset of partitioning where different shards are distributed across distinct machines or nodes. This structure offers several benefits, including improved scalability, higher availability, enhanced parallel processing, and faster query execution.
Sharding is a strategy more commonly used in NoSQL databases, but it is also used in some modern RDBMS. For instance, solutions like Citus and TimescaleDB enable sharding and horizontal scaling with PostgreSQL. MySQL NDB Cluster automatically shards (partitions) tables across nodes.
Benefits of sharding:
Sharding distributes data across multiple machines, allowing the system to scale horizontally by adding more shards as data and traffic increase.
Queries can be distributed across different shards, enabling parallel processing and faster execution times.
Shards can be managed independently, optimizing hardware resources such as CPU, memory, and storage.
Sharding allows data to be distributed across different locations, beneficial for serving global user bases and reducing latency.
Shards can be tailored to specific workloads or data types, enabling more flexible data management and organization.
Replication
Data replication involves creating several copies of the same data and distributing them across different servers. This practice ensures data availability, reliability, and resilience for an organization. By storing data copies in various locations, organizations can safeguard against data loss due to unexpected events such as disasters, outages, or other disruptions. If one copy becomes inaccessible, another copy can be quickly utilized as a backup, enabling continued operations without significant downtime.
Replication and sharding are often used together. When combined, sharding divides the database into smaller partitions to scale it, while replication maintains multiple copies of each partition to enhance data reliability and availability. This approach allows the system to efficiently handle large volumes of data and remain resilient against potential failures.
MongoDB Sharded Cluster Architecture
Finally, I want to show the MongoDB sharded cluster architecture that sharding and replication are used together. Below is a diagram from MongoDB’s official documentation. This method enables MongoDB to efficiently handle large volumes of data while remaining robust and reliable, ensuring seamless operation even in the face of challenges.
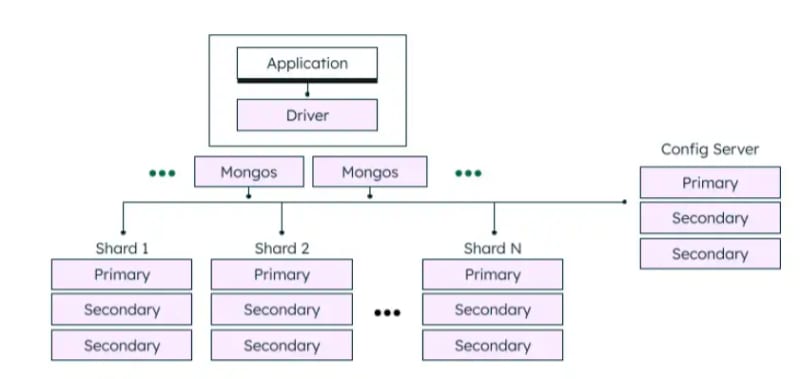
A MongoDB sharded cluster consists of the following components:
Shards: Data is divided across multiple shards, and each shard is a replication set, which consists of one primary node and one or more secondary nodes. The primary node handles read and write operations, while the secondary nodes replicate the primary’s data and can take over as primary if necessary.
Mongos: The mongos is a query router, providing an interface between client applications and the sharded cluster.
Config servers: Config servers store metadata and configuration settings for the cluster.





Top comments (0)