
Disclaimer: I'm not affiliated with AWS and this is not technical advice. In case you consider using this pattern in production, please be aware the core feature is very briefly documented and there is actually no performance guarantee.
According to the docs, DynamoDB's auto-split, split-for-heat or Adaptive Capacity auto-split is a (briefly documented) feature that "rebalances your partitions such that frequently accessed items don't reside on the same partition".
After performing some tests to have a better understanding on how this feature actually works, and to acknowledge that it isn't a replacement for write sharding, I came up with this architecture as a way to improve read costs for, maybe, some use cases.
Lazy Sharding
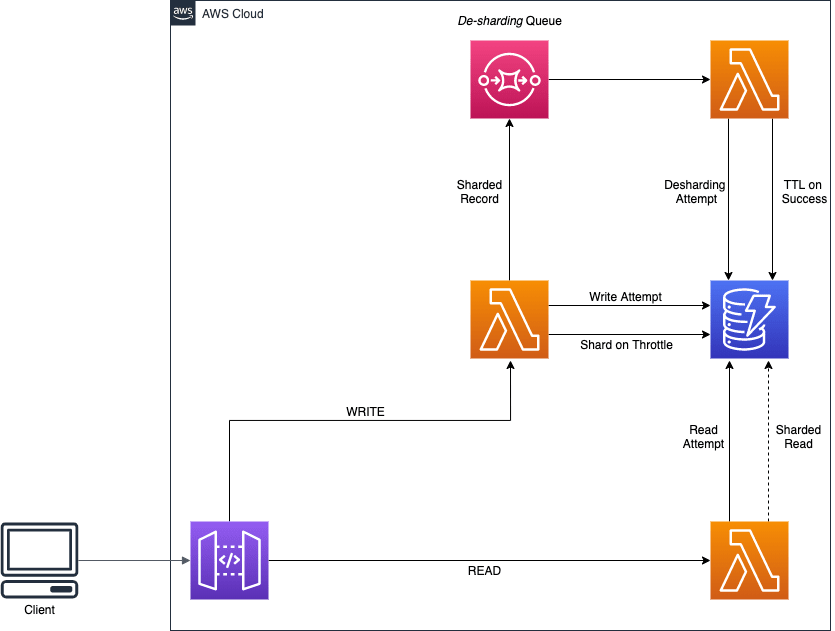
Basically, the idea here is to only write-shard the partition if our requests are being throttled. If they are, run a de-sharding strategy to rewrite the items to a single partition, while DynamoDB takes care of the repartitioning. When reading, also perform an attemptive read on the main partition first, only performing a sharded read as a second attempt.
Alternatively, for cases where the reads are disproportionally high, not allowing the partitioning to happen based on write velocities, similar de-sharding jobs can be run, so attemptive reads on a single partition can be done in order to save RCUs.
Is it Worth it? Would it work?
Honestly, in addition to the fact that there's no performance guarantee on the underlying feature, I'm not sure if there are many use cases for this. So, please tell me what you think, leave your feedback!
--
André





Top comments (0)