GitOps
GitOps, a term coined in 2017, describes the practice of performing infrastructure operations from a Git repository. In this practice, we easily develop the ability to re-deploy any broken infrastructure (like application managers), but that doesn't really help infrastructure engineers.
From the perspective of an Infrastructure Engineer, Git has a great deal to offer us:
- Versioning: Particularly with the load balancer example, many NEPs (Network Equipment Providers) expose object-oriented profiles, allowing services consuming the network to leverage versioned profiles by simply applying them to the service.
-
Release Management: Most enterprises don't have non-production networks to test code, but having a release management strategy is a must for any infrastructure engineer. At a minimum, Git provides the following major tools for helping an infrastructure engineer ensure quality when releasing changes :
- Collaboration/Testing : Git's Branch/Checkout features contribute a great deal to allowing teams to plan changes on their own infrastructure . If virtual (simulated production) instances of infrastructure are available, this becomes an incredibly powerful tool
- Versioning : Git's Tags feature provides an engineer the capability of declaring "safe points" and clear roll-backs sets in the case of disaster.
- Peer Review : Git's Pull Request feature is about as good as it gets in terms of peer review tooling. When releasing from the "planning" branch to a "production" branch, just create a Pull Request providing notification that you want the team to take a look at what you indent to do. Bonus Points for performing automated testing to help the team more effectively review the code.
Applying GitOps

On Tooling
Before visiting this individual implementation , none of these tools are specific or non-replaceable. The practice is what matters more than the tooling, and there are many equivalents here:
- Jenkins: Harness, Travis CI, etc
- GitHub: GitLab, Atlassian, Gitea, etc.
- Python: Ansible, Terraform, Ruby, etc.
GitOps is pretty easy to implement (mechanically speaking). Any code designed to deploy infrastructure will execute smoothly from source control when the CI tooling is completely set up. All of the examples provided in this article are simple and portable to other platforms.
On Practice
This is just an example to show how the work can be executed. The majority of the work in implementing GitOps lies with developing release strategy, testing, and peer review processes. The objective is to improve reliability , not to recover an application if it's destroyed.
It does help deploy consistently to new facilities, though.
Let's go!
Since we've already developed the code in a previous post, most of the work is already completed - the remaining portion is simply configuring a CI tool to execute and report.
A brief review of the code (https://github.com/ngschmidt/python-restify/blob/main/nsx-alb/apply_idempotent_profiles.py) shows it was designed to be run headless and create application profiles. Here are some key features for pipeline executed code to keep in mind:
- If there's a big enough problem, crash the application so there's an obvious failure. Choosing to crash may feel overly dramatic in other applications, but anything deeper than pass/fail takes more comprehensive reporting. Attempt to identify "minor" versus "major" failures when deciding to crash the build. It's OK to consider everything "major".
- Plan the code to leverage environment variables where possible, as opposed to arguments
- Generate some form of "what was performed" report in the code. CI tools can email or webhook notify, and it's good to get a notification of a change and what happened (as opposed to digging into the audit logs on many systems!)
- Get a test environment. In terms of branching strategy, there will be a lot of build failures and you don't want that to affect production infrastructure.
- Leverage publicly available code where possible! Ansible (when fully idempotent) fits right into this strategy, just drop the playbooks into your Git repository and pipeline.
Pipeline Execution
Here's the plan. It's an (oversimplified) example of a CI/CD pipeline - we don't really need many of the features required by a CI tool here:
-
Pull code from a Git Repository + branch
- Jenkins can support a schedule as well, but with GitOps you typically just have the pipeline check in to SCM and watch for changes.
Clear workspace of all existing data to ensure we don't end up with any unexpected artifacts
Load Secrets (username/password)
"Build". This stage, since we don't really have to compile, simply lets us execute shell commands.
"Post-build actions". Reporting on changed results is valuable and important, but the code will also have to be tuned to provide a coherent change report that turns to code. Numerous static analysis tools can also be run and reported on from here.
The configuration is not particularly complex because the code is designed for it:


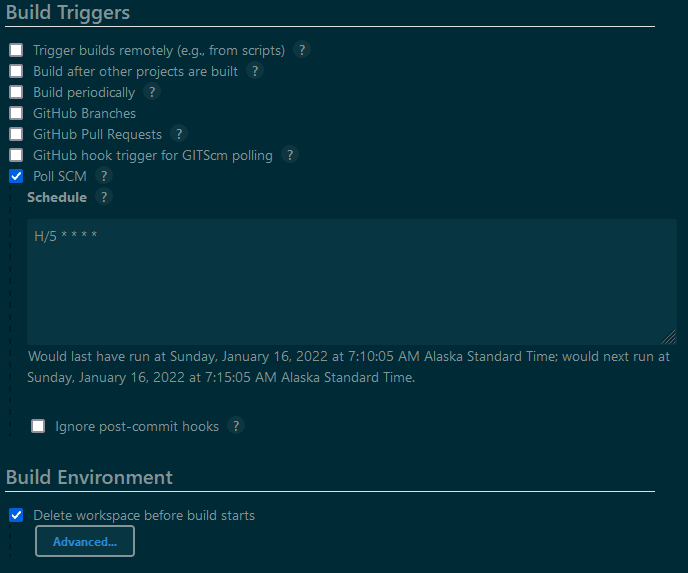

This will perform unit testing first, then execute and provide a report on what changed.
Building from Code
The next phase to GitOps would be branch management. since the production or _ main _ branch now represents production, it's not particularly wise to simply commit to it when we attempt to create a new feature or capability. We're going to prototype next:
-
Outline what change we want to make with a problem statement

-
Identify the changes desired, and build a prototype. Avi is particularly good at this, because each object created can be exported as JSON once we're happy with it.
- This can be done either as-code, or by the GUI with an export. Whichever works best.
Determine any versioning desired. Since we're going to make a functional but not breaking change, SemVer doesn't let us increment the third number. Instead, we'll target version v0.1.0 for this release.
Create a new branch, and label in a way that's useful, e.g. _ clienttls-v0.1.0-release _
Generate the code required. Note: If you use the REST client, this is particularly easy to export :
-
python3 -m restify -f nsx-alb/settings.json get_tls_profile --vars '{\"id\": \"clienttls-prototype-v0.1.0\"}'
- Place this as a JSON file in the desired profile folder.
- Add the new branch to whatever testing loop (preferably the non-prod instance!) is currently used to ensure that the build doesn't break anything.
- After a clean result from the pipeline, create a pull request (Example: https://github.com/ngschmidt/python-restify/pull/17). Notice how easy it is to establish peer reviews with this method!
After the application, we'll see the generated profiles here:
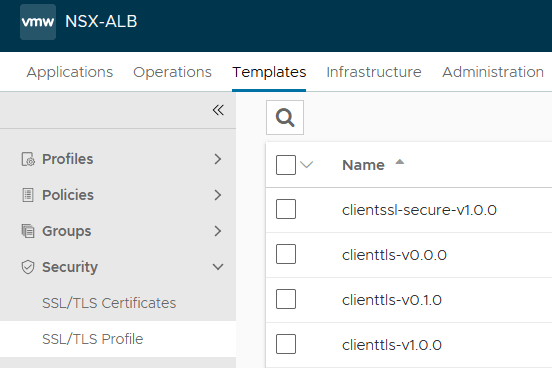
What's the difference?
When discussing this approach with other infrastructure engineers, the answer is "not much". GitOps is not useful without good practice. GitOps, put simply, makes disciplined process easier :
- Peer Review : Instead of meetings, advance reading, some kind of Microsoft Office document versioning and comments, a git pull request is fundamentally better in every way, and easier too. GitHub even has a mobile app to make peer review as frictionless as possible
- Testing: Testing is normally a manual process in infrastructure if performed at all. Git tools like GitHub and Bitbucket support in-line reporting , meaning that tests not only cost zero effort, but the results are automatically added to your pull requests!
- Sleep all night: It's really easy to set up a 24-hour pipeline release schedule, so that roll to production could happen at 3 AM with no engineers awake unless there's a problem
To summarize, I just provided a tool-oriented example, but the discipline and process is what matters. The same process would apply to:
- Bamboo and Ansible
- Harness and Nornir The only thing missing is more systems with declarative APIs.

Top comments (0)