The Serverless architecture has brought some attention to its terminology while it became more and more popular. It went for a time before someone discovers that, actually, serverless applications run on servers !
To that discovery, we observed 2 major reactions :
- The ones who have known since the beginning, and didn't tell
- The ones who didn't know and whose life meaning is now compromised
Before I begin explaining why, really, Serverless can't be serverless, you should be familiar with this cloud concept and service. If you are not, here are a few articles on DEV that I strongly recommend you to read :
- Building RESTful APIs on Serverless architectures
- 10 ways to use Serverless functions


Please also note that Serverless is a type of architecture, which means that it is not basically standardized between providers, serverless solutions on Heroku differ to App Engine on Google Cloud Platform or Lambda on Amazon Web Services.
However, the discussion around clouds and deployment ends here, because this post is about systems and networks, and how the Internet doesn't really allow massive deployments without servers (blockchains and torrenting apart).
The "server" principle
I think you are mostly aware of the concept of servers, and what they are. In fact, they really are computers designed to run efficiently to deploy services to end-users and also to run 24/7 with less downtime as possible.
Servers are massively used, every website you browse to is hosted on a server, the DNS system you use to resolve hostnames is hosted on servers, and so on...
But can we actually deploy a service without them ?
I mean, can't we find architectures to share data without having centralized servers ? Can we think, for example, of a distributed network to expose services ?
We will try to answer those questions on the next sections, but first, let's talk about the already known distributed services (and networks).
Distributivity and the web
The most common example for distributed networks is the old famous BitTorrent protocol, which allows for file sharing without having servers ! That is awesome, right ?
Yes, it is. But let's run through the architecture of a typical BitTorrent network.
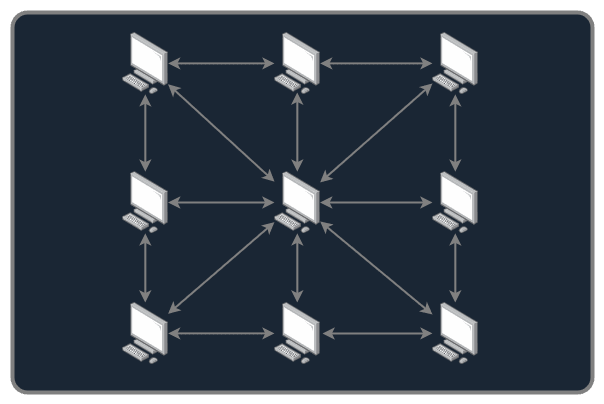
To share a file on BitTorrent, a computer (then called "the uploader") must have the whole file on its system. It will be originating the file sharing, by "seeding" it to the other computers. Once a computer has a bit of the file, it can also share it to the other computers, reducing the trafic on the uploader, and augmenting the seed of the file.
Of course, when downloaders have successfully downloaded the whole file, they are asked to do the same. BitTorrent has a "mesh" logical topology, which means that every PC on a BitTorrent network is able to have a communication with every other PCs connected to it.
The dream comes to an end, with no regulation whatsoever, this network isn't possible. You need to have what's called a "tracker", to coordinate the computers in their communications. And even, on some networks, to regulate the ratio download/upload, to avoid having computers that download files and then leave the network once they got it, avoiding the other computers to get it from them. Which is kind of the whole purpose of a Peer-to-Peer file sharing system. Peer-to-peer means that you talk directly with the computers, with no server between the two.
But, it is still possible to distribute the tracker with the DHT (Distributed Hash Table), but a bootstrapper server is still needed. So, while you don't have a direct communication with a server when you are sharing or receiving a file, you still need servers to organize the whole network.
Besides, the BitTorrent network requires a dedicated application that is built especially for this purpose.
The dream definitively comes to an end, because the web really is not designed for distributed architectures, well, in a way of having clients being servers and being able to reverse roles when they want.
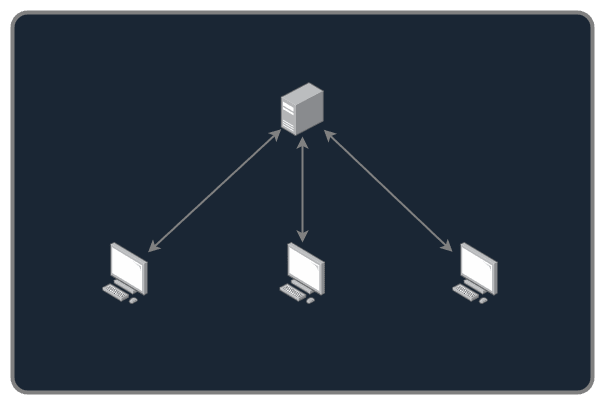
The HTTP protocol relies strongly on the server/client architecture, having an "unique" (or a distributed cluster) server that is responsible for sharing the data to the clients, sometimes with access restrictions or specific policies.
That is the key with HTTP and having central servers, you can have policies and access control. While we can imagine redesigning HTTP to be distributed on a "BitTorrent-like" network, it is not possible to have control over the data anymore, and it is causing a lot of security issues, like :
- Checking the original data integrity
- Regulating payments or financial informations over the distributed network
- Not divulgating the source code to everyone
- Restricting access to staff or specific users
- And so on...
One way to get over some of these aspects would be to use blockchain to check the integrity of the data shared over a distributed network, one very good example is the IPFS (InterPlanetary File System). I am not an expert of IPFS and will not try to debate over the fact that it can, or not, replace HTTP securely and keep all the aspects listed before, but it is to consider.
The main key for the whole Serverless architectures to be still deployed with servers is that you can use simple old protocols like HTTP and still be universally compatible with the browsers everyone uses, avoiding to have billions of people installing new softwares just to serve its purpose 😄
A final word
We had a brief, but quite explained, look over the simple architecture of the web that does not compare to a distributed one, and thus, proving that serverless, on today's WWW, is not possible.
But, by publishing this post, I break the whole Serverless principle : to not care over servers. It comes in a simple and humble way to remove server complexity for the DevOps engineers or even developers in smaller teams, they don't have to care about the server, the cloud platform does it for them.
I don't know if people really wanted to know the reason why we still use servers for Serverless, but here it is if you wanted it 😆
If you want to learn more about networks, topologies or communications between computers, check out my network series :






Top comments (4)
How'd you draw this conclusion thats it's only been a few weeks or months?
I have been seeing the debate of Serverless not really being serverless for like 2 or 3 months, that is what I wanted to tell by that sentence.
Serverless actually uses serverless has been talked about since its inception.
You may want to consider rewording that sentence to "has become really popular within my personal network"
I understand the misunderstanding here, so I have changed this sentence. Sorry for that !