
Search is everywhere. How would you survive a day without it!? It’s on every website and part of every product. Whether you’re purchasing underwear, trawling Netflix for a Friday night movie, or even leading a cutting-edge research team, it can be a modern miracle to summon what you need at the cost of a few key presses.
Despite being ubiquitous, why is search so often terrible? It’s frequently seen as second class, a bonus. It is plugged in and expected to work out of the box. It takes time, thought, and effort to craft a well-balanced search experience.
Before We Begin
Talking about concepts without an actual example to stare at can often become a challenge. For this post, we’ll be using a sample of around 10,000 books sourced from the Goodreads website. The data set itself, and scripts to load it into Elasticsearch, can be found here:
https://github.com/lucas-matt/search_playground
Principle 1. Search Engines Are Dumb, You Are Not
Often search engines are seen as just another database. They do look and act similar in many ways, but once you scratch the surface, you reveal a wealth of fancy algorithms and highly optimized data structures that differ quite drastically from a standard data store.
There are a number of parts to any search tool that we need to understand so that we can build upon them:
- analysis (zapping a chunk of text into fragments)
- the inverted index (a lightning-fast mapping of tokens to the documents in which they appear)
- the ranking algorithm (identification and ordering of information based upon its relevance to the query)
Analysis
As we push documents into our search engine, they get sliced and diced into lots of little chunks. These chunks, or tokens (as we should call them from now on), are the core currency of the search engine.

We control the way tokens get generated through an index’s schema definition. How we leverage this power has a huge effect on how the search engine behaves down the line — it’s one of the primary levers we can pull to master it. The choices are wide-ranging and include transformations such as token size (n-grams), removal of troubling stopwords (e.g., the, and, this), and stemming of terms (e.g., books to book). We will take a look at some of these in a moment.
The Index
Pick up any nonfiction textbook and flick to the back pages. Here we have a data structure that maps the key terms of the subject at hand to the passages in which they feature most heavily.
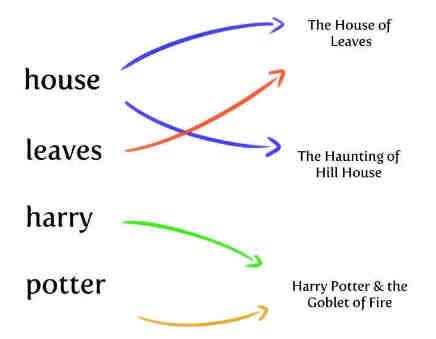
The inverted index of a search engine behaves very similarly. At a simple level, it maps the tokens present in a document to the documents in which it occurs.
Ranking
When you search for something, the engine matches your tokenized query against the index and scores each result using a ranking algorithm. Traditionally an algorithm such as TF-IDF is used. It rates a document higher the more frequently the document matches a term (TF, term frequency) offset by how common that term is (IDF, inverse document frequency).
All records are given a score and pitted against one another to identify the winners: your search results.
So search engines are smart, right?
Not exactly. Although the engineering underneath it all is a computer scientist’s dream, search engines are utter idiots! If the tokens generated from the query do not match any in the index exactly, you are out of luck. For example, if your index has horses but the query analyzer generates horse, too bad.
Garbage in, garbage out! It’s your job to curate.
Don’t just blindly add reams of data to the search engine. It’s your responsibility to turn the incoming mass of text into something useful.
Principle 2. It’s Not Just About Tokens but Features
The tokens generated from a document are more than just items in an index. They represent the core ideas about it.
What is a feature? Let’s take the example of the classic title Dracula from our dataset.
{
"title": "Dracula",
"genres": [
"classics",
"horror",
"fiction",
"gothic",
"paranormal",
"vampire"
],
"year": 1897,
"isbn": "393970124",
"description": "A Chronology and a Selected Bibliography are included.",
"publisher": "Norton",
"average_rating": 3.98,
"ratings_count": 618973,
"authors": [
"Bram Stoker"
]
}
Here we see just a few of the features concerning the novel — it’s a gothic classic, published in 1897 by the author Bram Stoker, and has an average rating of 3.98/5.
The source material will usually contain a wealth of features just sitting there ready to be picked, but often the most golden ones need to be mined from just beneath the surface. You need to model features to help communicate the ideas in your document. This technique is named feature extraction. Here you can play the mad scientist, distilling the text down to its bare essentials, stripping away all the confusion and muddiness within.
Feature engineering takes place during the analysis phase of indexing. The search engine has several tools to help us do this effectively. Let’s review a couple of them.
n-grams
The default tokenization strategy of any search engine is usually to (a) remove all punctuation and special characters, followed by (b) splitting on any whitespace. It can work quite well as an initial tactic because searching for a particular word will give you a successful match. For those long words that we have trouble spelling, however, this is not a great approach.
Imagine searching for the book Cryptonomicon. Half of your users are just going to type “Crypton” and hit return. With the standard analyzer, this is not going to get very far. Remember that search engines are dumb, and an out-of-the-box strategy is only going to produce the single token Cryptonomicon, which will not match our search request.

N-grams, and in particular edge n-grams, are great for those fields in which you want to partially match. Take a look at the wealth of tokens generated by taking an n-grammed approach to “Cryptonomicon.”

Using this strategy, because crypto is one of those tokens generated by the n-gram analyzer, we get our match.

Stemming
Stemming involves getting to the root of a word. Many terms have the same core meaning: quick, quickly, and quicker all come from the same place, as do happy, happier, happiest, and happiness.

By reducing a term to its stem, you are distilling it to its core essence. Utilizing this approach, you can translate those thoughts in the head of a user into a successful search result. You’re allowing them to converse at the level of ideas rather than worrying about syntax.
For a more detailed dive into stemming, check out the following section in Elasticsearch’s documentation.
Principle 3. Tuning In to Signals
Feature extraction is paramount to building a well-tuned search experience, but you must always keep the end user in mind while tackling it. What are the use cases for search? What kinds of items are users likely to be tracking down? What properties are most helpful in identifying or suggesting this? How can we manipulate features for maximum effect?
We must understand the user and anticipate their intent. One approach to thinking about this (as described in the book Relevant Search) is the strength of a signal.
Signals
When someone makes a search request, they’re hunting for documents that resonate most strongly with their wants. They are giving us several clues to help us help them: author, genre, title, year, etc. The documents that align most closely with the concepts respond with the strongest signal (as measured by the relevance score).

Not all signals are as clear as others, and some may actively work against you. While one feature may allow for a resounding match, others may generate noise, causing a false positive and detracting from the overall quality of the search results. We have the tools, however, to amplify those signals that are crystal clear and to quieten those that may occasionally be useful but more often than not get in the way.
Boosting
It is commonly the case that a hit on one property (title, for example) is much more valuable than on another (e.g., description). We can influence the search engine to take our preferences into account.
By raising one field above another, it increases the importance of its match over a peer. Those that resonate with your query will do so much more clearly, and those false positives will fade into insignificance. Boosting one field over another is as simple as assigning it a positive number.
Let’s say we fancy a classic Charles Dickens book, and we feed our search algorithm with the term dickens.

The results are a mixed bag. Some are Charles Dickens books, for sure, were but beaten to the podium by a number of others. Your users may think it strange for Moby-Dick to win this competition! We can change that outcome by levelling the playing field and adding a boost to the authors field.

Names are often a more precise match than something in a title or description — especially a full name, but we’ll see that later. By adding a boost to the authors field, we’re emphasising those records to show as more relevant to our search.
A word of warning though. It is a bit of an art weighting and balancing fields. Overly promote and you may end up fixing one problem (e.g., searching for the title) but introduce another (e.g., ability to search by publisher).
Match difficulty and boosting
One solution to the balancing problem is to correlate the size of the weight with the difficulty of obtaining a winning match on the field.
Properties that provide us with a crystal-clear signal include:
- ID
- Full name
- ISBN
Hit upon one of these and you’re on to a winner. Match against the description field, however, and you can never be completely confident because of the wide breadth of the content.
You can sleep easier elevating a feature that’s almost akin to a binary signal: It either matches or it doesn’t.
Same text, different analysis
Consider the author’s name. There are at least two different signals you can see here:
- Partial match, e.g., surname: King
- Complete match, e.g., full name: Stephen King
The latter signal is clearly of more significance than the former. It is much more valuable for us to know that the user is looking for an author by their full name. However, that doesn’t mean a partial match isn’t valuable at all, even if it could just be coincidental — you don’t always know the exact spelling of an author’s full name.
How can we handle both cases when we have but one name field? We can use feature modelling here to split this into two separate fields. Each feature can be tuned independently, the balance giving higher precedence to the more thorough match but allowing the weaker one to add value when appropriate.
Multi-matching
You do not always look for just one feature, but often mash a ton of different clues into one search string. You might search not only for an author but also specific subject matter from that author — Christmas novels by Charles Dickens, for instance.

By using a best-fields approach, Elasticsearch is going to pick the best match of the bunch: the signal giving us the strongest reaction. This approach can get in a bit of a muddle with the cross-feature query we just saw. What we want is to match primarily against the strongest signal, Christmas, and then augment this with a second field to emphasize its importance.

By setting up a tie-breaker, a value between 0 and 1, the search engine will still proceed to match on the best field, but then it will go one step further and use the other signals to further refine the results. In our example, Christmas could be our primary hit, with Dickens adding enough additional weight to hoist those novels into first place.
Principle 4. Feedback, feedback, feedback
Search isn’t a one-way street. It’s not just about handling a search request and blindly serving the user; it’s critical to have a conversation with them.

Suggestions
Often the user does not quite know what they’re seeking. They bash out a vague notion of what they want on the keyboard and see what bounces back. Without a little assistance, this can be a bit of a shot in the dark. They try, fail, and try again until they either flounder into something usable or give up.
By presenting auto-completing suggestions, you’re giving immediate feedback on the kinds of things available, with the bonus of not needing perfect recall or spelling ability.
Suggestions are supported out of the box by most, if not all, search engines. In Elasticsearch, it is just another (albeit special) field into which you copy your titles, author names, genres, and the like.

Highlighting
Have you ever searched for something and wondered how the heck you got the results you did? If your documents are data-rich, it can sometimes become unclear what you’ve hit when searching.
Providing feedback by highlighting the terms that were matched can turn out to be invaluable, allowing the user to tweak their request to be more specific or to filter out unwanted results.
For more information, read about how to highlight in the Elasticsearch documentation.
Monitoring and iteration
“What gets measured gets managed” — Peter Drucker
Building a truly useful search experience requires learning from your users. Domain expertise is clearly important, but actually seeing what your users come up with can reveal some key insights.
Bouncing around? Search after search after search and still not sticking on any one result. Why is this? What terms are being looked for?
No results? Are a lot of different users looking for something that doesn’t return anything useful? Is your search engine badly tuned, or maybe there’s an opportunity to be pounced upon.
A successful outcome? Did the session have a successful outcome? Was something bought, watched, read?
Gather and analyze this information to continually improve your solution.
The Last Word
We’ve touched upon quite a few different aspects that need to be considered when putting together an engaging search experience. We’ve only just scratched the surface here, and I’d advise checking out the resources below for more information.
Search is a complete subject area in its own right, branching out at the more cutting edges into related topics, including recommendations and machine learning. As with most engineering projects, a successful outcome can be achieved by approaching it in small steps. Make sure you start simple, collect feedback, iterate, and evolve as required.
Thanks for reading!





Top comments (0)