
Elixir is an rapidly developing programming language that combines syntax simplicity, a functional approach and the power of Erlang and BEAM virtual machine. And there are a lot of Ruby programmers who give Elixir a try, considering that the syntax is very similar. But this similarity may become a trap, since two languages are completely different and there may be different concepts lying under the same syntax.
I gathered ten things that can be confusing for Ruby developers who decided to try Elixir and make their first steps in this wonderful programming language.
- Functional mindset
- Immutable data structures
- Assignment operator
- Strings and charlists
- Lists and tuples
- Symbols and atoms
- Return statement
- Loops
- Keyword lists and maps
- Function clauses
Let’s discuss all items in this list one by one and (hopefully) make it a little bit more clear.
Functional mindset
This is the first thing programmers usually face when moving from the object-oriented programming language to the functional one. And it’s probably even worse when we talk about moving from Ruby, where everything is an object (well, almost). In Ruby, a programmer is used to thinking about classes and objects, object methods and attributes and there is nothing like that in Elixir. Instead, there are functions and modules, immutable data structures and recursion.
Even though the full understanding comes only with experience, there are several recommendations how you could apply functional programming better:
- try to consider you program not as sequence of commands or instructions, but as a series of filters and transformations
- think in functions and operations, not in objects
- try to avoid common procedural constructions (loops and conditions) and replace them with clauses, guards and recursion
Immutable data structures
Immutable data structures have a lot of advantages. They are thread-safe, so they can be shared among several threads or processes. Languages operating with mutable data structures have to copy the whole data on every fork. There are some optimizations like copy-on-write techniques that prevent the full copy, but they also represent some challenges
[1]. Also immutable data structures are almost bug-proof, as you can pass such structures to any function without worrying that it might be modified.
But immutability also has its drawbacks. And the main one, obviously, is the fact that you can’t change the value of an element. In other words, if you want to change the value of n-th element in the list, Elixir creates a new list, which copies the old one except the value you changed. However, there are some optimizations that allow Elixir to copy just part of the list before the n-th element and share the tail. That’s why adding an element to the beginning of the list is O(1) while adding to the end is O(n).
The main thing you should remember about data structures in Elixir is that every time you call a modifying function on the list, map or tuple, it creates and returns a new structure. That’s why it’s impossible to create a circular data structure in Elixir [2].
Assignment operator
The assignment operator is a common concept for all procedural and object-oriented programming languages. The assignment operator in Ruby (=) works exactly the same way it does in dozens of other languages, at least when we talk about a simple assignment operator, not combined (+=, -=, etc.) or conditional (||=).
Despite the fact that there is a similar = operator in Elixir, it doesn’t work the same. In fact, it isn’t an assignment operator at all! In Elixir it’s a match operator and its function is to match the left side with the right side [3]. The fact that it also assigns variables can be considered the side-effect, not the main purpose. We can see the difference in the following example:
irb(main):001:0> a = 1
=> 1
irb(main):002:0> 1 = a
syntax error, unexpected '=', expecting end-of-input (SyntaxError)
iex(1)> a = 1
1
iex(2)> 1 = a
1
The expression a = 1 returns the same result in both languages. The expression 1 = a causes an error in Ruby, because you can’t assign any new value to 1. But it works without errors in Elixir, because, as I mentioned, = is not an assignment but a match operator and 1 on the left side of = matches with the a on the right side. However, that doesn’t mean that Elixir doesn’t care how you assign a variable - on the left or the right side. The following will not work:
iex(3)> 1 = b
** (CompileError) iex:3: undefined function b/0
It means that all the unassigned variables should be on the left side of the match operator.
Assignment and match operators not only have similar syntax. Unlike most of the functional languages, Elixir has a feature called variable rebound:
iex(3)> a = 1
1
iex(4)> a = 2
2
It looks like a variable value re-assignment and despite the fact that it works differently under the hood, the behavior is still the same.
Strings and charlists
Let’s start from the code example here:
irb(main):001:0> 'hello' == "hello"
=> true
same code in Elixir:
iex(1)> 'hello' == "hello"
false
Again, we see the code that is identical in both languages but behaves differently. The reason why it happens is that single and double-quoted literals have absolutely different meanings in Elixir and Ruby. In Ruby, both single and double quotes are used to represent String data type. There is only a small difference between them, as double-quoted strings allow interpolation whereas single-quoted don't. But the result will still be the same - we’ll get a String object.
As opposed to Ruby, Elixir has two different data types to represent text strings: binary strings and charlists [4]. This duality was inherited from Erlang. Double-quoted literals are binary strings, while single-quoted are charlists. That’s exactly why the comparison returned false in our example - those two objects are not equal, because they are not even of the same type.
Charlists are not widely used in Elixir, in fact they can be considered an Erlang legacy. Nevertheless, developers may mistakenly use them, thinking that they use strings, which can cause some unexpected program behavior.
Lists and tuples
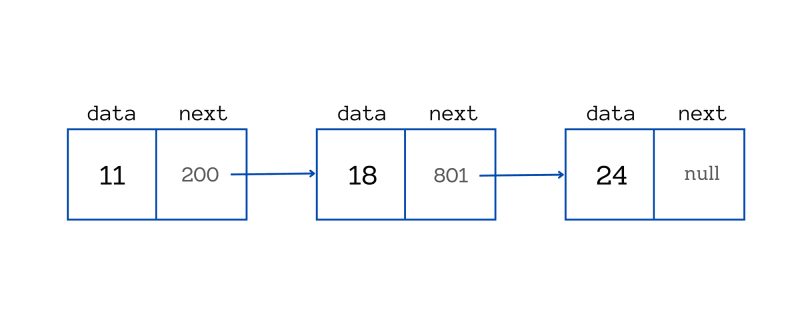
Again, we have similar syntax but very different internal representation.
iex(1)> [1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
This looks the same in both Ruby and Elixir. But in Elixir it’s a list, while in Ruby it’s an array. It sounds like just two different names for the same concept, but the truth is quite otherwise. Ruby arrays are intended to be used for the random access to its elements by index and usually there is no difference in access time for the 1st, 10th or 100th element. It works this way, because internally an array is a chunk of allocated memory that contains a set of items of the same size (in Ruby case it is the collection of pointers to other Ruby objects). Having only one pointer to the beginning of the memory chunk, a programming language can access every element by its index calculating the memory offset for this element. To do this calculation it should multiply the element’s index to the size of each element.
Elixir’s lists have a different nature, as they are the representation of the linked list data structure[6]. A linked list is a collection of objects, where each of them has a pointer to the next one. It means that to access the 10th element, you should start from the first one and move forward through the pointers 9 times. It makes access time different for different elements - the bigger index the element has, the longer it takes to access this element.
But this is not the end of the story. Elixir has one more data type, which contains a collection of elements and stores them contiguously in memory. It’s called tuple[7]. Tuples is a familiar concept for Python developers, but there is no analogue in Ruby. Tuples have constant access time to any elements they contain, but it still doesn’t mean that they should be used anywhere it’s possible, because updates/deletes of tuple elements are expensive as it requires to create new tuple on every update (remember that data structures are immutable in Elixir?).
Conclusion
In this part of the article, I gave an overview of some concepts that may seem familiar to rubyists when they code in Elixir for the first time. But however close these two languages are syntactically, they are still based on completely different paradigms and it may lead to confusions.
In the second part I will cover 5 remaining concepts mentioned in the beginning of the article.
Links
- https://brandur.org/ruby-memory
- https://guitcastro.medium.com/elixir-immutability-and-data-structure-c5f40734d870
- https://elixir-lang.org/getting-started/pattern-matching.html
- https://elixir-lang.org/getting-started/binaries-strings-and-char-lists.html
- https://en.wikipedia.org/wiki/Array_(data_structure)
- https://en.wikipedia.org/wiki/Linked_list
- https://elixir-lang.org/getting-started/basic-types.html#tuples





Top comments (0)