For the last couple of years, I have been working with various HTTP APIs. Quite often those APIs were not the public and only made available to partner companies. Also, I have seen APIs developed by fellow developers and participated in the development of several APIs myself. Quite often these APIs have a design flaw which makes it harder to create reliable integrations using the API.
The problem I’m talking about is duplicate resource creation on errors. It’s essential when resource creation is bound to critical real-world operations such as payments.
Let’s take Paypal’s Create Payment API as an example: when you create a new payment resource (by issuing a POST request to /v1/payments/payment), PayPal charges the user immediately. If the transaction is successful, you get back the status code 201 Created complemented with the payment id. That means that if you encounter network issues while sending this request, there is no easy way to tell if the payment was successful or not because you don’t know the payment id. What’s worse is that if you have an automatic retry on network errors, you will undoubtedly charge your users twice at some point.
Of course, this is a known problem with the API and PayPal offers a solution to it. See How to avoid duplicate payments? You can use the header PayPal-Request-Id (not documented at the Payments API page though), or you can misuse the invoice number to de-duplicate the requests. But does the solution have to be so complicated? Both ways are not user-friendly: the consumer needs to have a reliable mechanism for generating request IDs so that duplicate requests have the same request ID; in the second case, what if you need to support multiple payments per one invoice? There might be a more elegant solution.
Solving duplicate resource creation with POST/PUT resource creation
You can easily avoid the problem if the POST request would do nothing more than a database entry and generation of the resource id. The flow is like this:
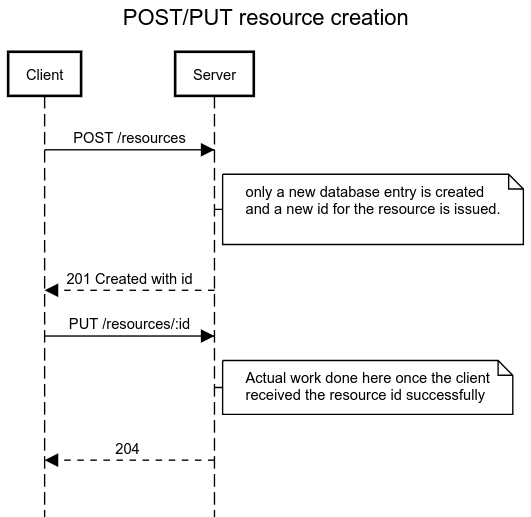
With this flow, it’s easy to retry requests when network failures happen. If you retry the POST request, it would just result in a duplicate empty resource. If you retry the PUT request, you are safe because PUT request is idempotent.
I find the pattern of POST/PUT creation to be more elegant despite the fact that it requires two requests to create a resource entirely. You may not like this approach, but my point is that you should support some way to de-duplicate POST requests if they result in significant real-world consequences. If you provide no such mechanism, your API is hardly suitable for stable and reliable integration.
Thanks for reading and hope it was helpful. Follow me on Twitter and share the problems you encountered with APIs and how you solved them.





Top comments (17)
I've worked with a similar approach, the difference was to do not rely on the server in order to generate the identifiers. I mean, it's the client who actually generate the identifier (UUID), and tells to the server all the resource details (including the identifier).
This way we would avoid having to always make the first POST request, and something also important, not having to return something such as the assigned identifier in this POST call response. This last concern is derived form CQRS concepts where the commands doesn't return information.
Thanks for sharing!
Thanks for the comment. Getting away with a PUT request only would be great but I am sure it's not always desirable to let clients decide on identifiers. Nevertheless, if possible, it's definitely better!
Just curious because maybe you've faced different scenarios which would justify that assertion. In which cases you would find not desirable to let the client decide on the resources identifiers?
Thx!
Mostly for these three reasons:
My point of view:
Thanks for sharing!
Thanks for the comment! I agree that what you suggest is a good solution and can work well for many use cases. But 1) you cannot always choose UUID as id for different reasons and an additional generated id may not help (if you can, use UUID though) 2) UUID generation on clients you don't control can break at any time in production if done wrong and then you will have frustrated users who always get an error. So what you say: give the clients a chance to mess up; what I say: give the clients no chance to mess up at the expense of two HTTP requests. You can decide what to do in any given case and if you want to optimize the two requests and compress the logic into one. But if the operation is quite important I would advocate for paying the price of two requests but having full control over IDs on the backend and making sure nothing can be messed up (by anyone except you as the backend developer)
👍👍👍
Thanks for the reply!
I like your approach/idea but I didn't understand how you apply it to the "duplicate payment problem"
If I understood correctly you say that we should issue a POST to get the final resource id/url, and then PUT the request BUT if it's a payment transaction with a network error, doesn't it result in the same problem?
let's assume now there's a network error and the client doesn't know if it's PUT went through or not so it decides to resubmit it, thinking that PUT, being idemponent, is safe.
Aren't we still left with 2 payments?
Let me explain: HTTP says PUT should be idempotent (so without side effects and with the same result). This is fine to update a record or an image or whatever but a payment it's not a side effect free operation.
So if I try two times to PUT the payment and the server both times issues a payment to the third party, I'm still left with double the amount less in my account.
In the case of PUT operation, the server can easily check if a payment has been already sent for this particular payment id. When the server gets a new PUT request, it checks if the payment has been sent to a 3rd party and never sends it twice (this can be ensured internally via locks and/or transactions). For POST requests it's not that easy because it's hard to know the intent of the caller (whether it's a duplicate request or a new payment). Therefore, you need to come up with less elegant solutions such as adding a
RequestIdheader and by this you shift the responsibility to the caller.Oh now I got it, thanks! You use the id on the server instead of a generic "request id" on the client to shift responsibility.
I thought you were trying to do that still keeping the responsibility on the client, that's why I didn't understand.
Thanks! :-)
Have you ever dealt with the problem of duplicate requests yourself? If so, how?
Yep, but using request ids, not really handy.
I see that Stripe API uses "Idempotency IDs" which allows the client to tell the server "Hey, this POST request is idempotent, treat it as such"
See stripe.com/docs/api#idempotent_req... and masteringmodernpayments.com/blog/i...
„Both ways are not user-friendly: the consumer needs to have a reliable mechanism for generating request IDs“
Given that we are talking about payments and those are usually bound to a transaction like an order, there should already be such an identifier, e.g an order ID.
Although your idea looks interesting and nice, this doesn’t seem like the perfect use case for it.
Additionally having some sort of request ID included in the request could make troubleshooting easier if something goes wrong.
Normally, yes. Even more, if your implementation is thorough enough, you can save all outgoing requests with their request IDs in a database related to the, say, customer record. But is it the best possible way?
This is nice in any case. But is there really a need to use the request ID to turn non-idempotent POST requests into idempotent PUT-like requests? I would be really happy if all APIs in the world used at least request IDs to de-duplicate the POST requests. But it's not the best way because those requests IDs in the headers usually are optional and often overlooked. Heck, even PayPal's API doc does not mention it in the section about payment creation. I would prefer APIs to be designed in such way so that it's impossible to double-process things in the first place.
Do you know a better example from your experience to illustrate the problem?
There is no universal answer to that question. Everything has its drawbacks.
But, depending on what you are optimizing for: Yes, it can be the best solution.
In this case there are drawbacks with your solution: it requires a second roundtrip for something that is a single operation, actually.
If you are aiming for a lot of requests this might not be what you want.
Second, one could say that it is not very RESTful, since you are basically introducing state. What if network errors lead to a lot of first requests to happen but not the second one? Then you have records you need to cleanup.
Now that is a circular argument.
If sending a request ID is required for your use case, then you can use that field and be done with it, isn’t it so?
This is true. I mention this in the post.
I would argue that one can view it as two operations: 1) getting an id for a new resource and 2) creation of the resource using PUT.
The Request ID also introduces state because the second request with the same ID is rejected. Also, it changes the usual way POST requests work.
Indeed, you can clean them up later. It's easier than to cancel a duplicate payment though.
I would, and I would advocate for providing it, at least. Unfortunately, in practice, it's not always available because it's not a standard way of doing things. I would prefer to have a solution which eliminates duplication by design.
Btw great website with patterns: restalk-patterns.org/index.html