
Using Docker to run Large Language Models (LLMs) locally? Yes, you heard that right. Docker is now much more than just running a container image. With Docker Model Runner, you can run and interact with LLMs locally.
It’s a no-brainer that we’ve seen a huge shift in development towards AI and GenAI. And it’s not easy to develop a GenAI-powered application, considering all the hassle—from cost to setup. As always, Docker steps in and does what it’s known for: making GenAI development easier so developers can build and ship products and projects faster. We can run AI models on our machines natively! Yes, it runs models outside of containers. Right now, Docker Model Runner is in Beta and available for Docker Desktop for Mac with Apple Silicon, requiring Docker Desktop version 4.40 or later.
In this blog, we will explore the benefits of the Docker Model Runner and how to use it in various forms. Let’s get straight in!
Benefits of Docker Model Runner
Developer Flow: One of the most important aspects as a developer that we don’t like is the context switching and using 100 different tools, and Docker, used by almost every other developer, make things easy and reduces the learning curve.
GPU Acceleration: Docker Desktop runs llama.cpp directly on your host machine. The inference server can access Apple's Metal AP, which allows direct access to the hardware GPU acceleration on Apple Silicon.
OCI Artifcats: Store AI models as OCI artifcats instead of storing them as Docker Images. This saves disk space and reduces the extraction of everything. Also, this will improve compatibility and adaptability as it’s an industry-standard format.
Everything Local: You don’t need to face the hassle of Cloud LLMs API Key, rate limiting, latency, etc, while binding products locally and paying those expensive bills. Another big aspect is data privacy and security comes on top of it. Models are dynamically loaded into memory by llama.cpp when needed.
In Action
Make sure you have Docker Desktop v4.40 or above installed in your system. Once you have that, make sure you have enabled the Enable Docker Model Runner by going to settings > Features in development. You can also check Enable host-side TCP support to communicate form your localhost (we will see a demo below for that).
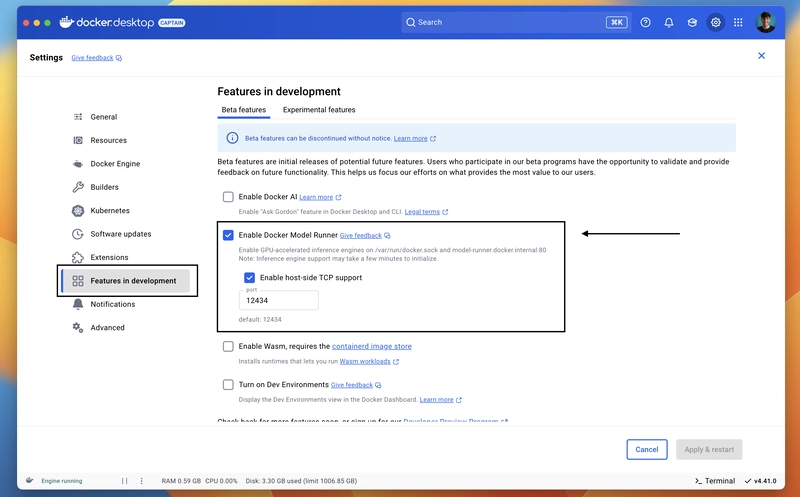
Once you are done. Click on Apply & restart, and we are all set. To test it’s working, open any terminal any type docker model, you will see the output of all the available commands and this verifies everything is working as expected.
So, to intrext with the LLMs, we have two methods (as of now, stay tuned) from the CLI or the API (OpenAI-compatible). The CLI is pretty straightforward on the API front. We can interact with API either from inside a running container or from the localhost. Let’s look at these in much more detail.
From the CLI
If you have used docker cli (which almost every developer has who ever worked with the container) and used the commands, like docker pull, docker run, etc, the docker model uses the same pattern, only there is sub command addition which is the model keyword, so to pull a model we will do docker model pull <model name> or to run a pulled model docker model run <model name>. It makes things so much easier because we don’t need to learn whole new wording for a new tool.
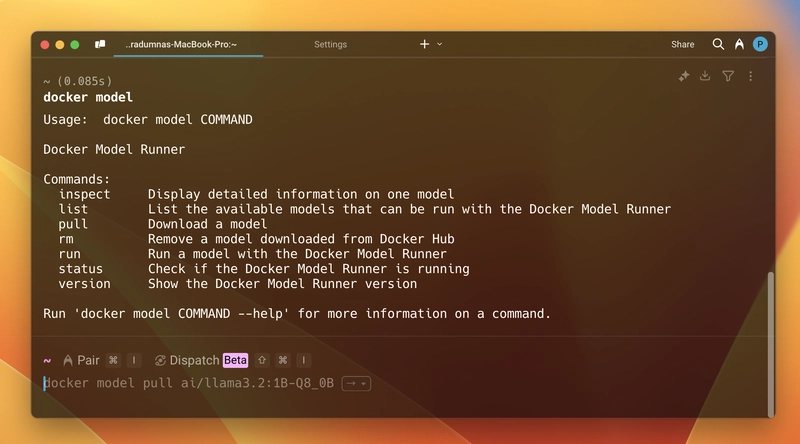
Here are all the commands that are currently supported. Some more are coming soon (some are my favourites, too). Stay tuned!
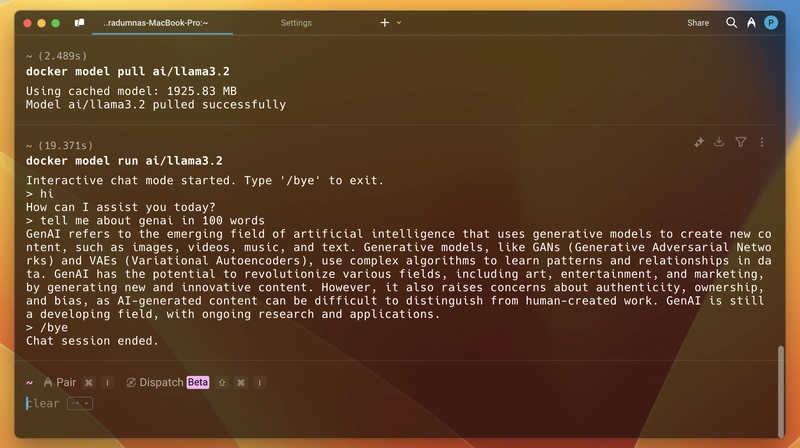
Now, to run a mode, we first need to pull it. So, for example, we will run llama3.2. You will find all available models on the Docker Hub’s GenAI Catalog. So, open the terminal and run docker model pull ai/llama3.2. It will take some time to pull it depending on the Model size and your internet bandwidth. Once you pull it, run the docker model run ai/llama3.2, and it will start an inactive chat like you have a normal chatbot or ChatGPT, and once you are done, you can use /bye it to exit the interactive chat mode. Here is a screenshot:
From the API (OpenAI)
One of the fantastic things about Model Runner is that it implements OpenAI-compatible endpoints. We can interact with the API in many ways, like inside a running container or from the host machine using TCP or Unix Sockets.
We will see examples of different ways, but before that, here are the available endpoints. The endpoints will remain the same whether we interact with the API from inside a container or from the host. Only the host will change.
# OpenAI endpoints
GET /engines/llama.cpp/v1/models
GET /engines/llama.cpp/v1/models/{namespace}/{name}
POST /engines/llama.cpp/v1/chat/completions
POST /engines/llama.cpp/v1/completions
POST /engines/llama.cpp/v1/embeddings
Note: You can also omit llama.cpp.
From Inside the Container
From inside the container, we will use http://model-runner.docker.internal it as the base URL, and we can hit any endpoint mentioned above. For example, we will hit /engines/llama.cpp/v1/chat/completions the endpoint to do a chat.
We will be using the curl. You can see it uses the same schema structure as OpenAI API. Make sure you have already pulled the model that you are trying to use.
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 100 words about the docker compose."
}
]
}'
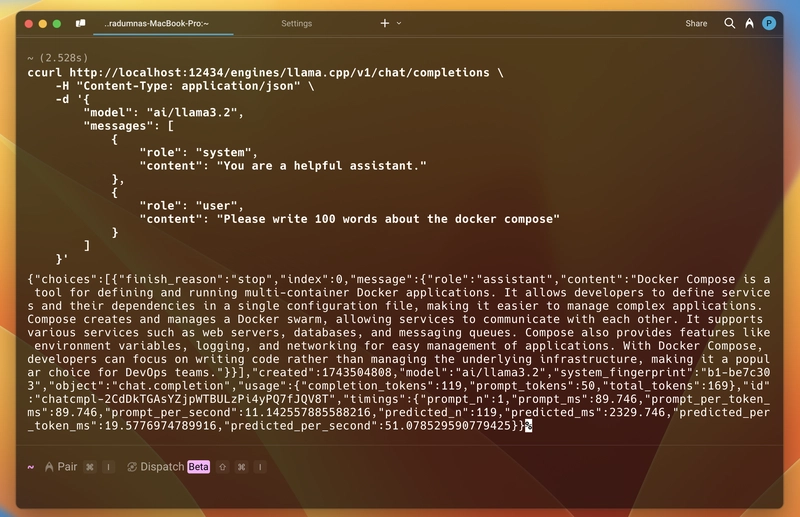
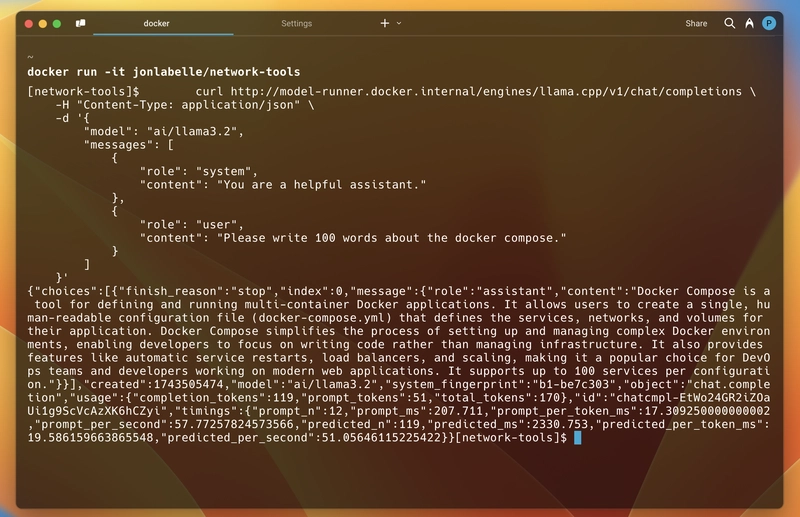
So, to test it out, that it works from inside the running container, I am running the jonlabelle/network-tools image in an interactive mode and then using the above curl command to talk to the API. And it worked.
As you can see, below is the response I got. The response is in JSON format, including the generated message, token usage, model details, and response timing. Just like the standard.
From the Host
As I mentioned previously, to interact with the A, you must be sure you have enabled the TCP. You can verify it’s working by visiting the localhost:12434. You will see a message saying Docker Model Runner. The service is running.
In this, we will have http://localhost:12434 as the base URL and the same endpoints will be followed. The same goes for the curl command; we will just replace the base URL, and everything will remain the same.
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 100 words about the docker compose."
}
]
}'
Let’s try it out by running it in our terminal:
It will return the same JSON format response as the other one, including the generated message, token usage, model details, and response timing.
With this TCP support, we are not just limited to interacting with the applications that are running inside our container but anywhere.
That’s it about the Blog. You can learn more about the Docker Model Runner from the official docs here. And keep an eye out for the Docker announcements; there will be a lot more coming. As always, I'm glad you made it to the end—thank you so much for your support. I regularly share tips on Twitter (It will always be Twitter ;)). You can connect with me there.

Top comments (11)
Nice! This is interesting, Ollama essentially is a wrapper around llama.cpp that provides "docker" like functionality, so you probably will get better performance with that, but it's nice to see this support coming to the Docker engine as well.
I'm not sure Ollama will give better perf since both Ollama and Docker Model Runner are running natively on the hardware.
Yeah, this will be very interesting. I like this model runner approach. Ollama is another daemon process to manage. Most of the time, you have Docker already there, so it makes sense to just run Docker if the performance is on par.
I would say this is true for a low managed machine, or a box that you will just used to expose LLMs, where installing ollama or llmstudio and maintaining the latest versions are not possible.
The performances are very similar (of course). One of our captains compared both in a blog, you can check it out: connect.hyland.com/t5/alfresco-blo....
Thanks for the comment!
How is it better than using LLM Studio?
Performance-wise, they both wrap llama.ccp (so we should expect similar performances), but LM Studio is more mature with multiple engines support and more OS support so far. The Model Runner will get there, but it will require some time.
The integration with the Docker technology (compose but also the Docker Engine for pipelines) is going to come soon, and it will give the model runner an advantage to developers to be well integrated in their development lifecycle.
🚀
Let's go!
Back in the day, Docker did the same thing with Kubernetes. You could just run K8s right there in Docker Desktop - it worked. Very handy for beginners.
I guess it's the same in this case too. 😄
100%. Thank you.