Introduction
Hi, this is Tecca, and this post is a summary of the project, for more details check previous posts about stage1 and stage2 of the project.
In stage 2, I implemented auto-vectorization to the project and in this post I will go over some details and see if there are places that auto-vectorization was not applied and why.
Re-cap
Before applying auto-vectorization running djpeg

After applying auto-vectorization and running djpeg on qemu-aarch64

number of whilelo after applying auto-vectorization
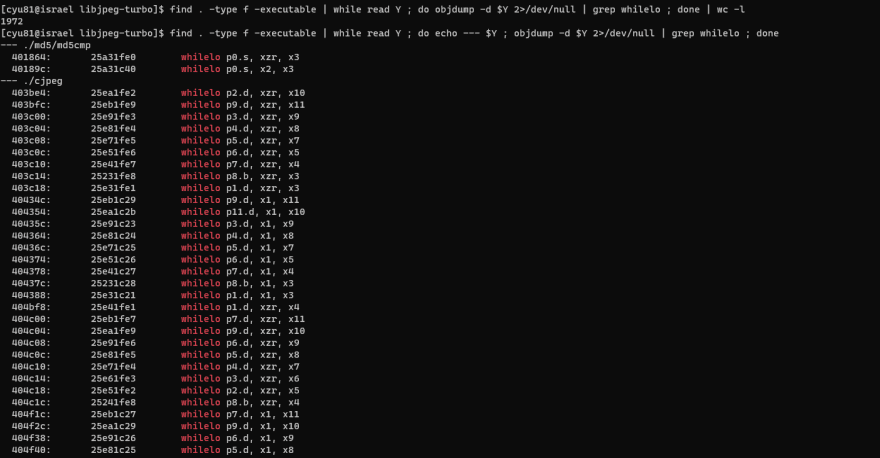
I assumed the above screen shots evidently show that auto-vectorization was successfully applied to the project and the original function djpeg works fine without crashing. But I wonder if all the necessary locations were auto-vectorized.
I believe my implementation will actually run slower than the original code if I test it on qemu-aarch64 due to the nature of qEmu-aarch64 that it will allow regular code to run at full speed on processors, and run SVE2 instructions at a slower speed.
Anyways, to get a log of all the vectorized file and not vectorized file, I need to rebuild the project the way I did in stage 2.
make -j$((`nproc`+1)) |& tee make.log
Through this we are storing the make process detail in the make.log file.
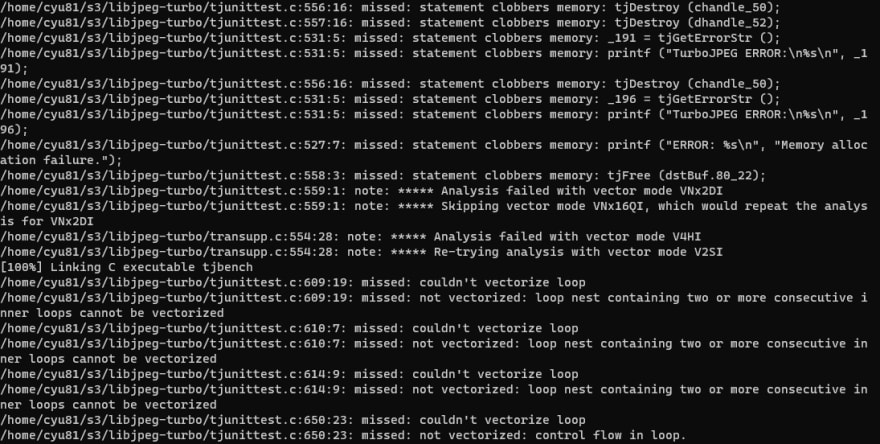
We can tell from the log that there are definitely places that were "missed" from auto-vectorization.
Detail of not vectorized files
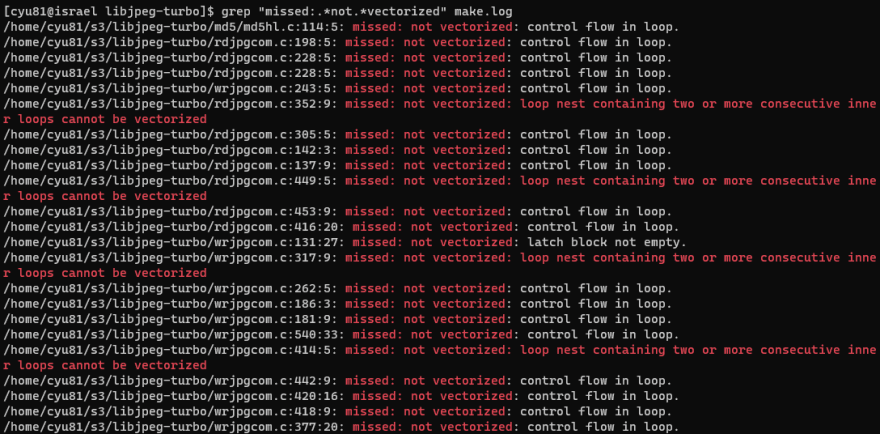

We can tell from the above screen shot, the amount of files vectorized are way less than the files that are not vectorized.
My guess is that only the files with loops that will process large amount of data will get optimized by auto-vectorization, because optimizing the loops that does not process large amount of data will very unlikely benefit from auto-vectorization. And it make sense that the important loops are way less than the less important ones.
Different vectorization
two types of vectors were used variable length and specified byte vector

Trying to look into not vectorized code and apply modifications
I tried to modify the codes that are not vectorized and try to see if I could manually auto-vectorize them. But none of the methods I try work, and there could be various reasons to that and it was actually explained in to make.log.
I did a bit of research and some say in most cases, a C/C++ compiler cannot vectorize the for-loop because it cannot match its structure to a predefined vectorization template.
Conclusion
Throughout the 3 stages, I selected candidate open-source package for optimization, in stage 3 I tried adding SVE2 support manually but I couldn't add more vectorization through modifying the source code, but I successfully added auto-vectorization in stage 2 to presumably all the necessary locations in the library by modifying compiler options.

Top comments (0)