In this post, we will compare the implementation of Pandas and SQL for data queries. We'll explore how to use Pandas in a manner similar to SQL by translating SQL queries into Pandas operations.
It's important to note that there are various ways to achieve similar results, and the translation of SQL queries to Pandas will be done by employing some of its core methods.
New York Flights ✈️ 🧳 🗽

source image Image by upklyak on Freepik
We aim to explore the diverse Python Pandas methods, focusing on their application through the nycflights13 datasets. This datasets offer comprehensive information about airlines, airports, weather conditions, and aircraft for all flights passing through New York airports in 2013.
Through this exercise, we'll not only explore Pandas functionality but also learn to apply fundamental SQL concepts in a Python data manipulation environment.
Entity-relationship diagram [ERD]
The nycflights13 library contains tables with flight data from New York airports in 2013. Below, you can find a high-level representation of an entity-relationship diagram with its five tables.

Installation: Setting Up nycflights13
To install the nycflights13 library, you can use the following command:
!pip install nycflights13
This library provides datasets containing comprehensive information about flights from New York airports in 2013. Once installed, you can easily access and analyze this flight data using various tools and functionalities provided by the nycflights13 package.
🟢 Pandas, NumPy, and nycflights13 for Data Analysis in Python
In the next code snippet, we are importing essential Python libraries for data analysis.
- 📗 Pandas is a library for data manipulation and analysis,
- 📗 Numpy provides support for numerical operations
- 📗 Nycflights13 is a specialized library containing datasets related to flights from New York airports in 2013.
import pandas as pd
import numpy as np
import nycflights13 as nyc
In the following lines of code, we are assigning two specific datasets from the nycflights13 library to variables.
flights = nyc.flights
airlines = nyc.airlines
🟢 SELECT and FROM Statements
📗 SELECT: All Columns
The following SQL query retrieves all columns and rows from the "🛩️ flights" table. In Pandas, the equivalent is simply writing the DataFrame name, in this case, "flights." For example:
🔍 sql
SELECT * FROM flights;
🐍 python
flights
📗 SELECT: Specific Columns
To select specific columns from a Pandas DataFrame, you can use the following syntax:
🔍 sql
select
year,
month,
day,
dep_time,
flight,
tailnum,
origin,
dest
from flights;
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
)
🟢 Filtering Operators (WHERE)
📗 Utilizing 'WHERE' for Equality ( = )
To filter all ✈️ flights where the origin is 'JFK' in Pandas, you can use the following code:
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin = 'JFK'
limit 10;
🐍 python
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
.query("origin=='JFK'")
.head(10)
)
📗 Utilizing 'WHERE' for Equality ( = )
To achieve the same filtering in Pandas for specific criteria:
- ✈️ Flights departing from JFK, LGA, or EWR.
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
limit 10;
🐍 python
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
.query("origin in ['JFK', 'EWR', 'LGA']")
.head(10)
)
📗 Utilizing 'WHERE' with Inequality ( != )
To achieve the same filtering in Pandas for specific criteria:
- ✈️ Flights departing from JFK, LGA, or EWR.
- ✈️ Flights not destined for Miami (MIA).
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' ) and dest<>'MIA'
limit 10;
🐍 python
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
.query(
"(origin in ['JFK', 'EWR', 'LGA'])"
"and (dest != 'MIA')"
)
.head(10)
)
📗 Utilizing 'WHERE' for Comparisons (>=, <=, <, >)
To achieve the same filtering in Pandas for specific criteria:
- ✈️ Flights departing from JFK, LGA, or EWR.
- ✈️ Flights not destined for Miami (MIA).
- ✈️ Flights with a distance less than or equal to 1000 km.
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
limit 10;
🐍 python
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest',
'time_hour', 'distance'])
.query(
"(origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and (distance <= 1000)"
)
.head(10)
)
📗 Utilizing 'WHERE' with between operator
To achieve the same filtering in Pandas for specific criteria:
- ✈️ Flights departing from JFK, LGA, or EWR.
- ✈️ Flights not destined for Miami (MIA).
- ✈️ Flights with a distance less than or equal to 1000 km.
- ✈️ Flights within the period from September 1, 2013, to September 30, 2013.

🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
limit 10;
🐍 python
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest',
'time_hour', 'distance'])
.query(
"(origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA')"
" and (distance <= 1000)"
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
.head(10)
)
📗 Utilizing 'WHERE' with "LIKE" Clause
To achieve the same filtering in Pandas for specific criteria:
- ✈️ Flights departing from JFK, LGA, or EWR.
- ✈️ Flights not destined for Miami (MIA).
- ✈️ Flights with a distance less than or equal to 1000 km.
- ✈️ Flights within the period from September 1, 2013, to September 30, 2013.
- ✈️ Flights where the tailnum contains 'N5' in the text.
You can use the following code:
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
and tailnum like '%N5%'
limit 10;
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
" and (tailnum.str.find('N5')>=0)"
)
.head(10)
)
📗 Utilizing 'WHERE' with Null or Not Null Values
To achieve the same filtering in Pandas for specific criteria:
- ✈️ Flights departing from JFK, LGA, or EWR.
- ✈️ Flights not destined for Miami (MIA).
- ✈️ Flights with a distance less than or equal to 1000 km.
- ✈️ Flights within the period from September 1, 2013, to September 30, 2013.
- ✈️ Flights where the tailnum contains 'N5' in the text.
- ✈️ Flights where dep_time is null
You can use the following code:
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
and tailnum like '%N5%'
and dep_time is null
limit 10;
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
" and (tailnum.str.find('N5')>=0)"
" and dep_time.isnull()"
)
.head(10)
)
🟢 Order by Statement
The .sort_values() methods in Pandas are equivalent to the ORDER BY clause in SQL.
1️⃣. **.sort_values(['origin','dest'], ascending=False)**: This method sorts the DataFrame based on the 'origin' and 'dest' columns in descending order (from highest to lowest). In SQL, this would be similar to the ORDER BY origin DESC, dest DESC clause.
2️⃣. **.sort_values(['day'], ascending=True)**: This method sorts the DataFrame based on the 'day' column in ascending order (lowest to highest). In SQL, this would be similar to the ORDER BY day ASC clause.
Both methods allow you to sort your DataFrame according to one or more columns, specifying the sorting direction with the ascending parameter. True means ascending order, and False means descending order.
🔍 sql
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
and tailnum like '%N5%'
and dep_time is null
order by origin, dest desc
limit 10;
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
" and (tailnum.str.find('N5')>=0)"
" and year.notnull()"
)
.sort_values(['origin','dest'],ascending=False)
.head(10)
)
🟢 Distinct Values: Removing Duplicates from Results
To perform a distinct select in pandas, you need to first execute the entire query, and then apply the drop_duplicates() method to eliminate all duplicate rows.
🔍 sql
select distinct origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and time_hour between '2013-09-01' and '2012-09-30'
order by origin, dest desc;
🐍 python
(
flights
.filter(['origin','dest','time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
.filter(['origin','dest'])
.drop_duplicates()
)
🟢 Adding Calculated Columns
Now, let's introduce a new calculated column called "delay_total," where we sum the values from the "dep_delay" and "arr_delay" columns.
🔍 sql
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
flights.dep_delay + flights.arr_delay as delay_total
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and time_hour between '2013-09-01' and '2012-09-30';
🐍 python
(
flights
.filter(['origin', 'dest', 'time_hour', 'dep_delay', '
arr_delay'])
.assign(delay_total = flights.dep_delay + flights.arr_delay )
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
)
🟢 Group by Statement
To perform a GROUP BY operation in pandas, we'll use the groupby method, which operates similarly to its SQL counterpart. Similarly, we can employ common aggregate functions such as sum, max, min, mean (equivalent to avg in SQL), and count. Below is a simple example to illustrate this process:
🔍 sql
select
year,
month,
max(dep_delay) as dep_delay,
from flights
group by
year,
month
🐍 python
(
flights
.groupby(['year','month'],as_index=False)
['dep_delay'].max()
)
🟢 Group by and Having Statement
In the following example, we'll explore how to implement a HAVING clause in pandas, leveraging the query method, as we've done previously for filtering.
🔍 sql
select
year,
month,
max(dep_delay) as dep_delay,
from flights
group by
year,
month
having max(dep_delay)>1000
🐍 python
(
flights
.groupby(['year','month'],as_index=False)['dep_delay']
.max()
.query('(dep_delay>1000)') # having
)
🟢 Group by with multiple calculations
When working with pandas and needing to perform multiple calculations on the same column or across different columns, the agg function becomes a valuable tool. It allows you to specify a list of calculations to be applied, providing flexibility and efficiency in data analysis.
Consider the following SQL query:
🔍 sql
select
year,
month,
max(dep_delay) as dep_delay_max,
min(dep_delay) as dep_delay_min,
mean(dep_delay) as dep_delay_mean,
count(*) as dep_delay_count,
max(arr_delay) as arr_delay_max,
min(arr_delay) as arr_delay_min,
sum(arr_delay) as arr_delay_sum
from flights
group by
year,
month
This query retrieves aggregated information from the "flights" dataset, calculating various statistics like maximum, minimum, mean, count, and sum for both "dep_delay" and "arr_delay" columns. To achieve a similar result in pandas, we use the agg function, which allows us to specify these calculations concisely and efficiently. The resulting DataFrame provides a clear summary of the specified metrics for each combination of "year" and "month."
🐍 python
result = (
flights
.groupby(['year','month'],as_index=False)
.agg({'dep_delay':['max','min','mean','count'], 'arr_delay':['max','min','sum']})
)
# Concatenate function names with column names
result.columns = result.columns.map('_'.join)
# Print the results
result
🟢 Union Statement
To execute a UNION ALL operation in Pandas, it is necessary to create two DataFrames and concatenate them using the concat method. Unlike SQL, a DataFrame in Pandas can be combined to generate additional columns or additional rows. Therefore, it is essential to define how the concatenation should be performed:
- axis=1 => Union that appends another dataset to the right, generating more columns.
- axis=0 => Union that appends more rows.
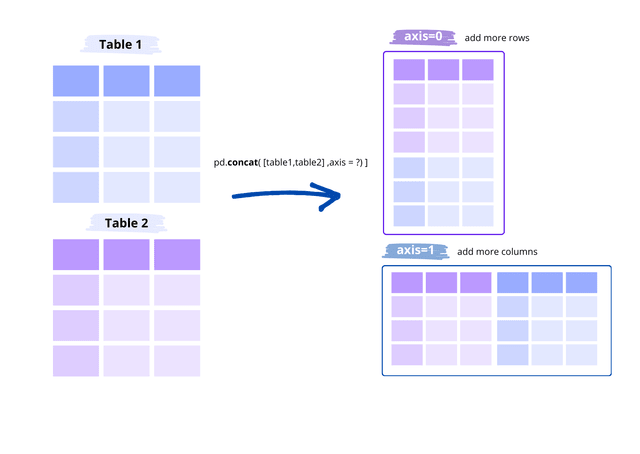
In our example, we will perform the equivalent of a UNION ALL in SQL, so we will use axis=0.
🔍 sql
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
flights.dep_delay + flights.arr_delay as delay_total ,
'NYC' group
FROM flights
WHERE origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and time_hour between '2013-09-01' and '2012-09-30'
ORDER BY flights.dep_delay + flights.arr_delay DESC
LIMIT 3
UNION ALL
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
flights.dep_delay + flights.arr_delay as delay_total ,
'MIA' group
FROM flights
WHERE origin in ( 'JFK', 'LGA', 'EWR' )
and time_hour between '2013-07-01' and '2012-09-30'
ORDER BY flights.dep_delay + flights.arr_delay DESC
LIMIT 2
;
🐍 python
Flights_NYC = (
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour',
'dep_delay', 'arr_delay'])
.assign(delay_total = flights.dep_delay + flights.arr_delay )
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
.assign(group ='NYC')
.sort_values('delay_total',ascending=False)
.head(3)
)
Flights_MIAMI = (
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour',
'dep_delay', 'arr_delay'])
.assign(delay_total = flights.dep_delay + flights.arr_delay )
.query(
" (dest in ['MIA', 'OPF', 'FLL'])"
" and ('2013-07-01' <= time_hour <= '2013-09-30')"
)
.assign(group ='MIA')
.sort_values('delay_total',ascending=False)
.head(2)
)
# union all
pd.concat([ Flights_NYC,Flights_MIAMI],axis=0)
🟢 CASE WHEN Statement
To replicate the CASE WHEN statement, we can use two different methods from NumPy:
1️⃣. If there are only two conditions, for example, checking if the total delay exceeds 0, then we label it as "Delayed"; otherwise, we label it as "On Time". For this, the np.where method from NumPy is utilized.
🔍 sql
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
(case
when flights.dep_delay + flights.arr_delay >0 then 'Delayed'
else 'On Time' end) as status ,
FROM flights
LIMIT 5;
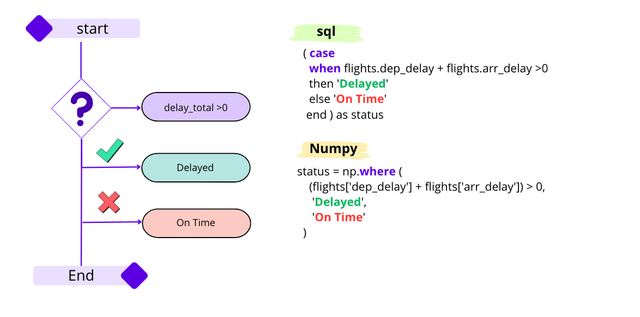
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour',
'dep_delay', 'arr_delay'])
.assign(status=np.where((flights['dep_delay'] + flights['arr_delay']) > 0, 'Delayed', 'On Time'))
.head(5)
)
2️⃣. In case there are more conditions, such as identifying Miami airports and labeling them as "MIA", labeling "ATL" airports that they are in Altanta, and for any other cases, using the label "OTHER". For this, the np.select method from NumPy is employed.
| City | Name | Acronym |
|---|---|---|
| Miami | Miami International | (MIA) |
| Miami | Opa-locka Executive | (OPF) |
| Miami | Fort Lauderdale-Hollywood | (FLL) |
| Atlanta | Hartsfield-Jackson Atlanta | (ATL) |
| Atlanta | DeKalb-Peachtree | (PDK) |
| Atlanta | Fulton County | (FTY) |
🔍 sql
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
(case
when dest in ('ATL','PDK','FTY') then 'ATL'
when dest in ('MIA','OPF','FLL') then 'MIA'
else 'Other'
end) as city ,
FROM flights
LIMIT 10;
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight', 'tailnum', 'origin', 'dest', 'time_hour', 'dep_delay', 'arr_delay'])
.assign(city=np.select([ flights['dest'].isin(['ATL','PDK','FTY']),
flights['dest'].isin(['MIA', 'OPF', 'FLL']),
],
['ATL','MIA'],
default='Other')
)
.head(10)
)
🟢 JOIN Statement
Entity relationship diagram [DER]
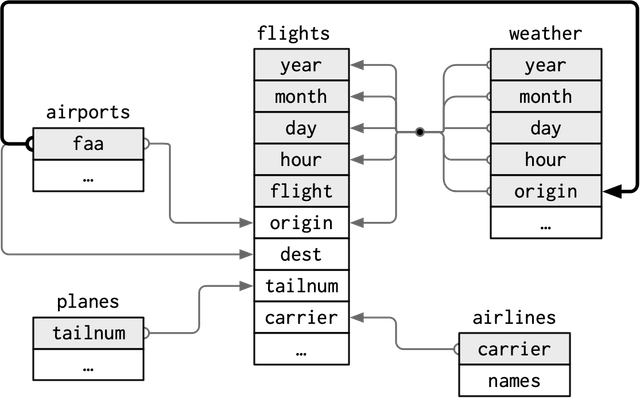
When performing a join in Pandas, the merge method should be used.
📗 Join Types
How: Specifies the type of join to be performed. Available options: {'left', 'right', 'outer', 'inner', 'cross'}

📗 Join Key
On: The key on which the tables will be joined. If more than one column is involved, a list should be provided. Examples:
- Single variable:
on='year'
fligths.merge(planes, how='inner', on='tailnum')
- Two variables: on=['year','month','day']
fligths.merge(weather, how='inner', on=['year','month','day'])
- left_on/right_on: When the columns have different names, these parameters should be used. For example:
fligths.merge(airports, how='inner', left_on = 'origin', rigth_on='faa')
Here's an example using the airlines and flights tables:
🔍 sql
select
f.year,
f.month,
f.day,
f.dep_time,
f.flight,
f.tailnum,
f.origin as airport_origen,
f.dest,
f.time_hour,
f.dep_delay,
f.arr_delay,
f.carrier,
a.name as airline_name
FROM flights f
left join airlines a on f.carrier = a.carrier
LIMIT 5;
🟢 Rename
The rename method is used to rename columns, similar to the "as" clause in SQL.
🐍 python
(
flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest',
'time_hour', 'dep_delay', 'arr_delay',
'carrier'])
.merge(airlines, how = 'left', on ='carrier')
.rename(columns= {'name':'airline_name',
'origin':'airport_origen'})
.head(5)
)
You can find all the code in a 🐍 python notebook in the following link
 r0mymendez
/
sql-to-pandas
r0mymendez
/
sql-to-pandas
New York Flights ✈️ 🧳 🗽 - Python Vs. SQL
 New York Flights
New York Flights ✈️ 🧳 🗽 - Python Vs. SQL

source image Image by upklyak on Freepik
In this exercise, we will compare the implementation of Pandas and SQL for data queries. We'll explore how to use Pandas in a manner similar to SQL by translating SQL queries into Pandas operations. It's important to note that there are various ways to achieve similar results, and the translation of SQL queries to Pandas will be done by employing some of its core methods.
We'll dive into the nycflights13 dataset, which contains comprehensive data on airlines, airports, weather conditions and aircraft for all flights passing through New York airports in 2013. Through this exercise, we'll not only explore Pandas functionality but also learn to apply fundamental SQL concepts in a Python data manipulation environment. This comparison serves as an initial step to delve into translating SQL queries to Pandas, utilizing…
📚 References
If you want to learn more about Pandas and NumPy...





Top comments (0)