
(cover image credit: https://tinyurl.com/576vc4jx)
In this tutorial, I will explain what rate limiting is and why it's so important to have this mechanism in large-scale systems.
Let's first understand the basic concept behind rate limiting.
Rate limiting is, as the name suggests, the limitation of some rate. That rate is the number of requests/operations a given client can do in a particular system, per unit of time. For example, limiting clients to only make 1 request every 3 seconds, or 5 requests every minute. It's forcing some kind of threshold on the interaction of the clients with our system.
If the client insists on sending more requests than the threshold defined, the server will respond saying that it can't handle more requests coming from him (using the appropriate HTTP code for this situation, which would be 429).
Now you might ask yourself: "Why is it important to have this in my system?". One important aspect is that you reinforce the security in your system. If you don't have rate limiting, you are more vulnerable to DoS (Denial of Service). Rate limiting helps our systems not getting flooded with requests.
Preventing DDOS (Distributed Denial of Service) is harder because DDOS in some way circumvents rate limiting. That's why from time to time, you see large corporates having their service unavailable, even if they have rate limiting policies in place.
Another thing you could do is rate limit per client basis. Let's say you have a very important corporate client that generates lots of business for you. You cannot give him the same rate limit as, say, a "normal" user that casually uses our system. You need to have this sensibility when projecting your rate limiting strategy.
Throughout this explanation, we have seen that somehow we need to store information about the client's requests to our system. But where exactly is the best place to store such information?
In our traditional large-scale system, we have many servers and a load balancer, as we can see in the figure below.
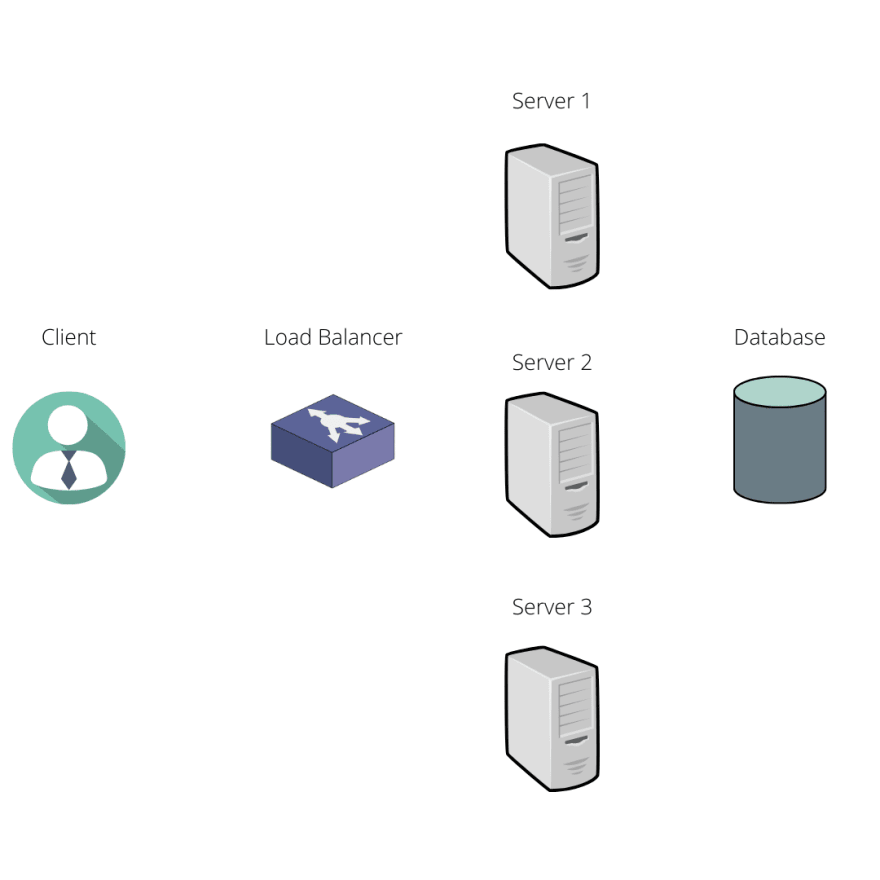
Our initial approach could be storing this information in-memory on the first server that our client hits, say server 1.
What would happen if the client issues another request?
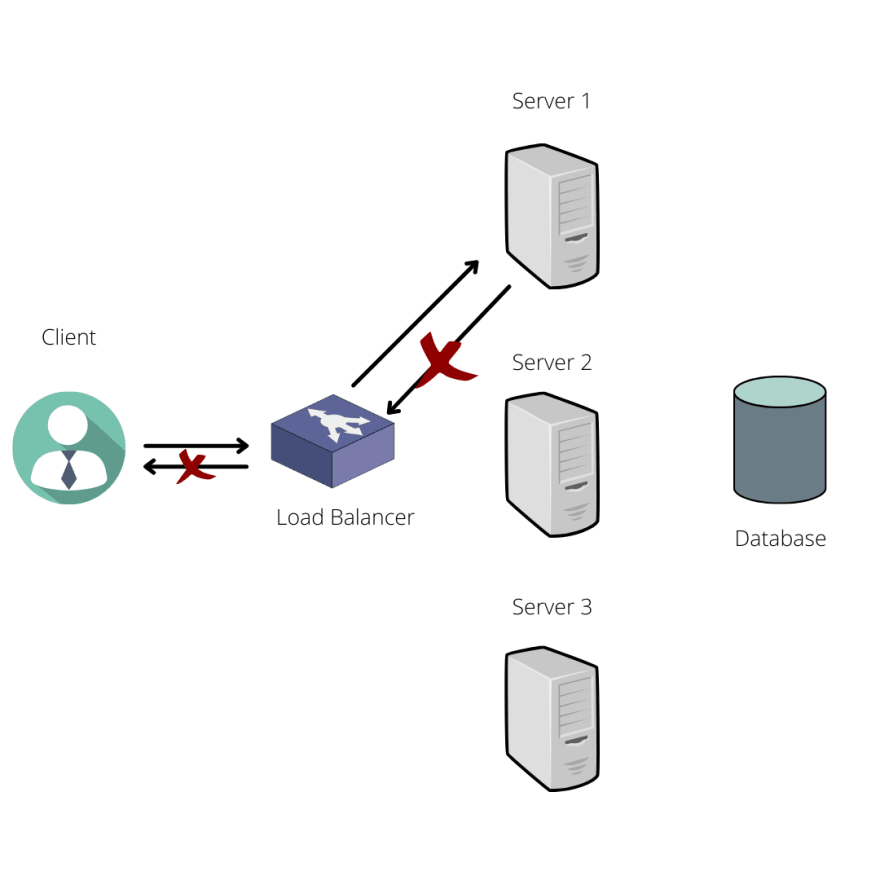
Well, it would depend on the load balancer policy. The only way you could have rate limiting in place properly would be if you have a load balancing strategy that would map a certain client to a specific server, meaning that the same client would always hit the same server.
In the below figures we can see how the client's request flow would happen if we follow this approach.
Let's say a client wants to read a value from our database. The load balancer, when receiving the request, will route it to server 1 (based on the load balancing policy). Server 1 will check in-memory if the client is obeying the rate limit defined. In this case, everything is ok, so we allow the client to read from the database.

What happens if server 1 checks that the client surpassed the rate limit?
It will immediately return to the client, stating the limit has been reached by him.
Although the previous strategy can work, with a lot of effort and a delicate load balancing strategy, there is a better approach.
The better approach is having a separate service, on which we store the client's request information, and whenever a server wants to check if the client is obeying the rate limit thresholds it will query this service. Redis is a popular choice for storing information and can be used in our service.
In the below figure, we can see what the user request flow would be like. Let's still imagine that the user wants to retrieve something from our database.
A client issues a request to our server, then our server will check our request service to validate the information regarding the rate limiting aspect. The information can be that the client is under the threshold and this means that the user can access our database. Otherwise, an error would be returned.
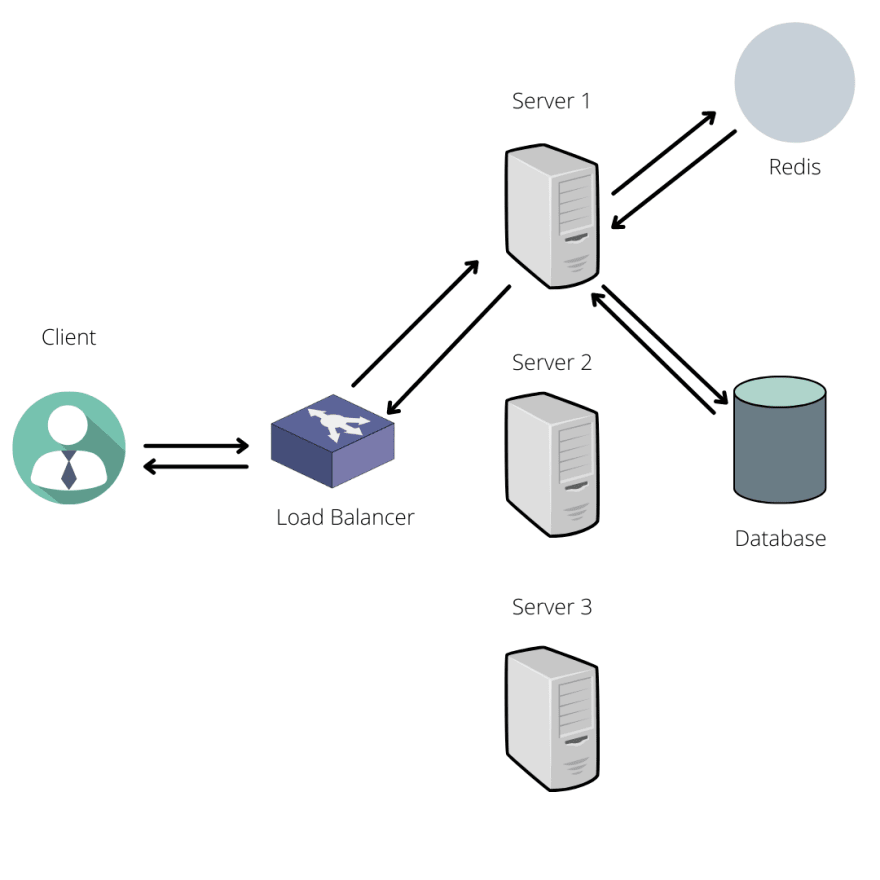
The advantage of this approach is that, by having this information stored in a separate service, we won't get affected by our load balancing strategy and can operate properly.
😁 I hope this has helped!
That's everything for now! Thank you so much for reading.
If you have any questions please feel free to drop them off.
Follow me if you want to read more about these kinds of topics!





Top comments (0)