A tool to automatically infer columns data types in .csv files
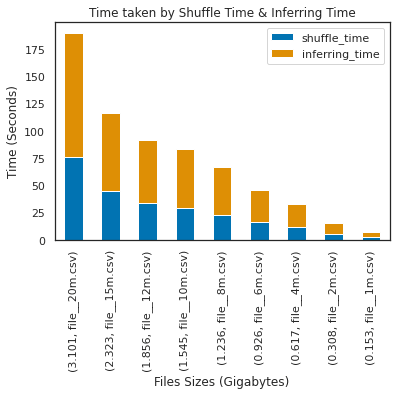
The tests were done with 9 .csv files, 21 columns, different sizes and number of records, an average of 5 executions was calculated for each process, shuffle time and inferring time.
- file__20m.csv: 20 million records
- file__15m.csv: 15 million records
- file__12m.csv: 12 million records
- file__10m.csv: 10 million records
- And so on...
If you want to know more about the shuffling process, you can check this other repository: A tool to automatically Shuffle lines in .csv files, the shuffling process will helps us to:
- Increase the probability of finding all the data types present in a single column.
- Avoid iterate the entire dataset.
- Avoid see biases in the data that may be part of its organic behavior and due to not knowing the nature of its construction.





Top comments (0)