
The capabilities of Large Language Models (LLMs) are enhanced by Retrieval-Augmented Generation (RAG). Thus, RAG comes up with a super powerful technique that distinguishes it from others.
RAG Frameworks are tools and libraries that help developers build AI models that can retrieve relevant information from external sources (like databases or documents) and generate better responses based on that information.
RAG and it's Flowchart 🎴
Imagine you have a big toy box filled with all your favorite toys. But sometimes, when you want to find your favorite teddy bear, it takes a long time because the toys are all mixed up.
Now, think of RAG (Retrieval-Augmented Generation) as a magical helper. This helper is really smart! When you ask, "Where is my teddy bear?", it quickly looks through the toy box, finds the teddy bear, and gives it to you right away.
In the same way, when you ask a computer a question, RAG helps it find the right information from a big book before giving you an answer. So instead of just guessing, it finds the best answer from the book and tells you! 😊
Flowchart
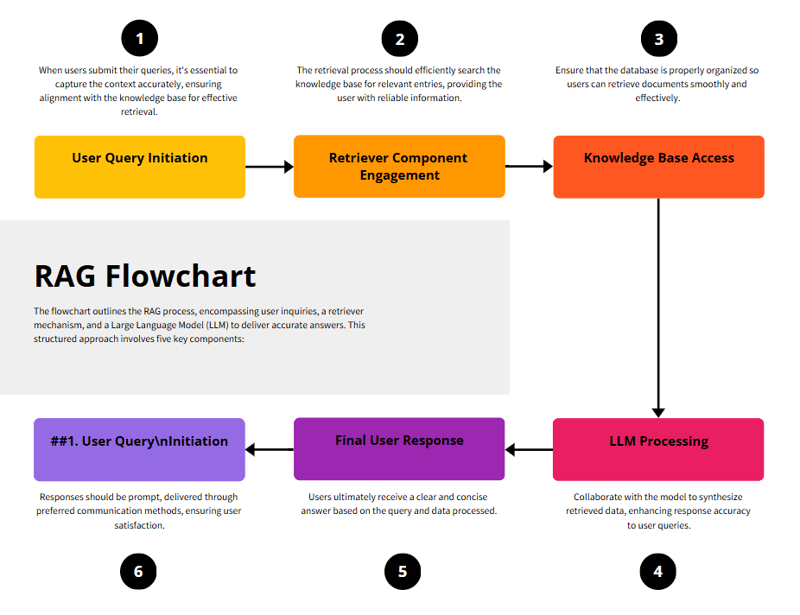
How RAG Frameworks Work ⚒️
- Retrieve → Search for relevant documents using a vector database.
- Augment → Feed those documents into the LLM as extra context.
- Generate → The LLM generates an informed response using both retrieved data and its own training knowledge.
Example
🔹 Step 1: User Question
Example: "Who discovered gravity?"
🔹 Step 2: Retrieve Relevant Information
Searches a knowledge base (e.g., Wikipedia, company documents)
Finds: "Isaac Newton formulated the law of gravity in 1687."
🔹 Step 3: Augment & Generate Answer
The LLM takes the retrieved information + its own knowledge
Generates a complete, well-structured response
🔹 Step 4: Final Answer
Example: "Gravity was discovered by Isaac Newton in 1687."
I hope now you're somewhat clear with the Rag concept. Now, in this blog, we will be discussing the top 10 Open-Source RAG frameworks that will help you boost your project or enterprise.
Top 10 Open-Source RAG Frameworks you need!! 📃
Here's a curated list of some famous and widely used RAG frameworks, you might not want to miss:
1️⃣ LLMWare.ai
11K Github Stars, 1.8K Forks
LLMWare provides a unified framework for building LLM-based applications (e.g., RAG, Agents), using small, specialized models that can be deployed privately, integrated with enterprise knowledge sources safely and securely, and cost-effectively tuned and adapted for any business process.
Core Features
- RAG support for enterprise-level AI apps.
- LLM Orchestration – Connects multiple LLMs (OpenAI, Anthropic, Google, etc.).
- Document Processing & Embeddings – Enables structured AI-driven search.
- Vector Database Integration – Works with Pinecone, ChromaDB, Weaviate, etc.
- Custom Fine-Tuning – Train models on private datasets.
🔹Use Cases
- Chatbots & virtual assistants
- AI-driven search and retrieval
- Summarization & text analysis
- Enterprise knowledge management
- Financial Analysis
Why LLMWare.ai?
- Faster AI development with pre-built tools
- Scalable & flexible for enterprise applications
- Open-source & extensible
 llmware-ai
/
llmware
llmware-ai
/
llmware
Unified framework for building enterprise RAG pipelines with small, specialized models
llmware

![]()
🆕Check out Model Depot
Are you using a Windows/Linux x86 machine?
- Getting started with OpenVino example
- Getting started with ONNX example
Table of Contents
- Building Enterprise RAG Pipelines with Small, Specialized Models
- Key Features
- What's New
- Getting Started
- Working with the llmware Github repository
- Data Store Options
- Meet our Models
- Using LLMs and setting-up API keys & secrets
- Release notes and Change Log
🧰🛠️🔩Building Enterprise RAG Pipelines with Small, Specialized Models
llmware provides a unified framework for building LLM-based applications (e.g., RAG, Agents), using small, specialized models that can be deployed privately, integrated with enterprise knowledge sources safely and securely, and cost-effectively tuned and adapted for any business process.
llmware has two main components:
-
RAG Pipeline - integrated components for the full lifecycle of connecting knowledge sources to generative AI models; and
-
50+ small, specialized models fine-tuned for key tasks in enterprise process automation, including fact-based question-answering, classification, summarization…
2️⃣ LlamaIndex (Formerly GPT Index)
39.8K Github Stars, 5.7K Forks
LlamaIndex (GPT Index) is a data framework for your LLM application. Building with LlamaIndex typically involves working with LlamaIndex core and a chosen set of integrations (or plugins).
Core Features
- Indexing & Retrieval – Organizes data efficiently for fast lookups.
- Modular Pipelines – Customizable components for RAG workflows.
- Multiple Data Sources – Supports PDFs, SQL, APIs, and more.
- Vector Store Integrations – Works with Pinecone, FAISS, ChromaDB.
🔹Use Cases
- AI-powered search engines
- Knowledge retrieval for chatbots
- Code and document understanding
Why LlamaIndex?
- Easy to integrate with OpenAI, LangChain, etc.
- Highly flexible & modular for different AI tasks.
- Supports structured & unstructured data.
run-llama
/
llama_index
LlamaIndex is the leading framework for building LLM-powered agents over your data.
🗂️ LlamaIndex 🦙




LlamaIndex (GPT Index) is a data framework for your LLM application. Building with LlamaIndex typically involves working with LlamaIndex core and a chosen set of integrations (or plugins). There are two ways to start building with LlamaIndex in Python:
-
Starter:
llama-index. A starter Python package that includes core LlamaIndex as well as a selection of integrations. -
Customized:
llama-index-core. Install core LlamaIndex and add your chosen LlamaIndex integration packages on LlamaHub that are required for your application. There are over 300 LlamaIndex integration packages that work seamlessly with core, allowing you to build with your preferred LLM, embedding, and vector store providers.
The LlamaIndex Python library is namespaced such that import statements which
include core imply that the core package is being used. In contrast, those
statements without core imply that an integration package is being used.
# typical pattern
from llama_index.core…
3️⃣ Haystack (by deepset AI)
19.7K Github Stars, 2.1K Forks

Haystack is an end-to-end LLM framework that allows you to build applications powered by LLMs, Transformer models, vector search and more. Whether you want to perform retrieval-augmented generation (RAG), document search, question answering or answer generation, Haystack can orchestrate state-of-the-art embedding models and LLMs into pipelines to build end-to-end NLP applications and solve your use case.
Core Features
- Retrieval & Augmentation – Combines document search with LLMs.
- Hybrid Search – Uses BM25, Dense Vectors, and Neural Retrieval.
- Pre-built Pipelines – Modular approach for rapid development.
- Integration Support – Works with Elasticsearch, OpenSearch, FAISS.
🔹Use Cases
- AI-powered document Q&A
- Context-aware virtual assistants
- Scalable enterprise search
Why Haystack?
- Optimized for production RAG applications.
- Supports various retrievers & LLMs for flexibility.
- Strong enterprise adoption & community.
run-llama
/
llama_index
LlamaIndex is the leading framework for building LLM-powered agents over your data.
🗂️ LlamaIndex 🦙
LlamaIndex (GPT Index) is a data framework for your LLM application. Building with LlamaIndex typically involves working with LlamaIndex core and a chosen set of integrations (or plugins). There are two ways to start building with LlamaIndex in Python:
-
Starter:
llama-index. A starter Python package that includes core LlamaIndex as well as a selection of integrations. -
Customized:
llama-index-core. Install core LlamaIndex and add your chosen LlamaIndex integration packages on LlamaHub that are required for your application. There are over 300 LlamaIndex integration packages that work seamlessly with core, allowing you to build with your preferred LLM, embedding, and vector store providers.
The LlamaIndex Python library is namespaced such that import statements which
include core imply that the core package is being used. In contrast, those
statements without core imply that an integration package is being used.
# typical pattern
from llama_index.core…
4️⃣ Jina AI
21.4K Github Stars, 2.2K Forks (jina-ai/serve)
Jina AI is an open-source MLOps and AI framework designed for neural search, generative AI, and multimodal applications. It enables developers to build scalable AI-powered search systems, chatbots, and RAG (Retrieval-Augmented Generation) applications efficiently.
Core Features
- Neural Search – Uses deep learning for document retrieval.
- Multi-modal Data Support – Works with text, images, audio.
- Vector Database Integration – Built-in support for Jina Embeddings.
- Cloud & On-Premise Support – Easily deployable on Kubernetes.
🔹Use Cases
- AI-powered semantic search
- Multi-modal search applications
- Video, image, and text retrieval
Why Jina AI?
- Fast & scalable for AI-driven search.
- Supports multiple LLMs & vector stores.
- Well-suited for both startups & enterprises.
Jina-Serve



![]()
Jina-serve is a framework for building and deploying AI services that communicate via gRPC, HTTP and WebSockets. Scale your services from local development to production while focusing on your core logic.
Key Features
- Native support for all major ML frameworks and data types
- High-performance service design with scaling, streaming, and dynamic batching
- LLM serving with streaming output
- Built-in Docker integration and Executor Hub
- One-click deployment to Jina AI Cloud
- Enterprise-ready with Kubernetes and Docker Compose support
Comparison with FastAPI
Key advantages over FastAPI:
- DocArray-based data handling with native gRPC support
- Built-in containerization and service orchestration
- Seamless scaling of microservices
- One-command cloud deployment
Install
pip install jina
See guides for Apple Silicon and Windows.
Core Concepts
Three main layers:
- Data: BaseDoc and DocList for input/output
- Serving: Executors process Documents, Gateway connects services
- Orchestration: Deployments serve Executors, Flows create pipelines
Build AI Services
Let's create a gRPC-based…
5️⃣ Cognita by truefoundry
3.9K Github Stars, 322 Forks
Cognita addresses the challenges of deploying complex AI systems by offering a structured framework that balances customization with user-friendliness. Its modular design ensures that applications can evolve alongside technological advancements, providing long-term value and adaptability.
Core Features
- Modular Architecture – Seven customizable components (data loaders, parsers, embedders, rerankers, vector databases, metadata store, query controllers).
- Vector Database Support – Compatible with Qdrant, SingleStore, and other databases.
- Customizability – Easily extend or swap components for different AI applications.
- Scalability – Designed for enterprise use, supporting large datasets and real-time retrieval.
- API-Driven – Seamless integration with existing AI pipelines.
🔹Use Cases
- AI-powered Customer Support with real-time retrieval.
- Enterprise Knowledge Management
- Context-Aware AI Assistants
Why Cognita?
- Open-source with modular design for custom RAG workflows.
- Works with LangChain, LlamaIndex, and multiple vector stores.
- Built for scalable and reliable AI solutions.
truefoundry
/
cognita
RAG (Retrieval Augmented Generation) Framework for building modular, open source applications for production by TrueFoundry
Cognita

Why use Cognita?
Langchain/LlamaIndex provide easy to use abstractions that can be used for quick experimentation and prototyping on jupyter notebooks. But, when things move to production, there are constraints like the components should be modular, easily scalable and extendable. This is where Cognita comes in action Cognita uses Langchain/Llamaindex under the hood and provides an organisation to your codebase, where each of the RAG component is modular, API driven and easily extendible. Cognita can be used easily in a local setup, at the same time, offers you a production ready environment along with no-code UI support. Cognita also supports incremental indexing by default.
You can try out Cognita at: https://cognita.truefoundry.com

🎉 What's new in Cognita
- [September, 2024] Cognita now has AudioParser (https://github.com/fedirz/faster-whisper-server) and VideoParser (AudioParser + MultimodalParser).
- [August, 2024] Cognita has now moved to using pydantic v2.
- [July, 2024] Introducing
model gatewaya single file to…
6️⃣ RAGFlow by infiniflow
43.9K Github Stars, 3.9K Forks
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine developed by InfiniFlow, focusing on deep document understanding to enhance AI-driven question-answering systems.
Core Features
- Deep Document Understanding: RAGFlow excels in processing complex, unstructured data formats, enabling accurate information extraction and retrieval.
- Template-Based Chunking: It employs intelligent, explainable chunking methods with various templates to optimize data processing.
- Integration with Infinity Database: RAGFlow seamlessly integrates with Infinity, an AI-native database optimized for dense and sparse vector searches, enhancing retrieval performance.
- GraphRAG Support: The engine incorporates GraphRAG, enabling advanced retrieval-augmented generation capabilities.
- Scalability: Designed to handle extensive datasets, RAGFlow is suitable for businesses of all sizes.
🔹Use Cases
- Enterprise Knowledge Management
- Legal Document Analysis
- AI-Powered Customer Support
- Medical Research
- Financial Analysis
Why RAGFlow?
- Deep Document Processing – Structures unstructured data for complex analysis.
- Graph-Enhanced RAG – Uses graph-based retrieval for smarter responses.
- Hybrid Search – Combines vector and keyword search for accuracy.
- Enterprise Scalability – Handles large-scale AI search applications.
infiniflow
/
ragflow
RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding.

English | 简体中文 | 繁体中文 | 日本語 | 한국어 | Bahasa Indonesia | Português (Brasil)


📕 Table of Contents
- 💡 What is RAGFlow?
- 🎮 Demo
- 📌 Latest Updates
- 🌟 Key Features
- 🔎 System Architecture
- 🎬 Get Started
- 🔧 Configurations
- 🔧 Build a docker image without embedding models
- 🔧 Build a docker image including embedding models
- 🔨 Launch service from source for development
- 📚 Documentation
- 📜 Roadmap
- 🏄 Community
- 🙌 Contributing
💡 What is RAGFlow?
RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data.
🎮 Demo
Try our demo at https://demo.ragflow.io.


🔥 Latest Updates
- 2025-02-28 Combined with Internet search (Tavily), supports reasoning like Deep Research for any…
7️⃣ txtAI by NeuML
10.5K Github Stars, 669 Forks

txtAI is an open-source AI-powered search engine and embeddings database, designed for semantic search, RAG, and document similarity.
Core Features
- Embeddings Indexing – Stores and retrieves documents using vector-based search.
- RAG Integration – Enhances LLM responses with retrieval-augmented generation.
- Multi-Modal Support – Works with text, images, and audio embeddings.
- Scalable & Lightweight – Runs on edge devices, local systems, and cloud.
- APIs & Pipelines – Provides an API for text search, similarity, and question answering.
- SQLite Backend – Uses SQLite-based vector storage for fast retrieval.
🔹Use Cases:
- AI-Powered Semantic Search
- Chatbot Augmentation
- Content Recommendation
- Automated Tagging & Classification
Why txtai?
- Lightweight & Efficient – Runs on low-resource environments.
- Versatile & Extendable – Works with any embeddings model.
- Fast Retrieval – Optimized for local and cloud-scale deployments.
neuml
/
txtai
💡 All-in-one open-source embeddings database for semantic search, LLM orchestration and language model workflows
![]()
All-in-one embeddings database



![]()

txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.


Embeddings databases are a union of vector indexes (sparse and dense), graph networks and relational databases.
This foundation enables vector search and/or serves as a powerful knowledge source for large language model (LLM) applications.
Build autonomous agents, retrieval augmented generation (RAG) processes, multi-model workflows and more.
Summary of txtai features:
- 🔎 Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing
- 📄 Create embeddings for text, documents, audio, images and video
- 💡 Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarization and more
- ↪️️ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows.
- 🤖 Agents that intelligently connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems
- ⚙️ Build with Python or…
8️⃣ STORM by stanford-oval
23.2K Github Stars, 2K Forks
STORM is an AI-powered knowledge curation system developed by the Stanford Open Virtual Assistant Lab (OVAL). It automates the research process by generating comprehensive, citation-backed reports on various topics.
Core Features
- Perspective-Guided Question Asking: STORM enhances the depth and breadth of information by generating questions from multiple perspectives, leading to more comprehensive research outcomes.
- Simulated Conversations: The system simulates dialogues between a Wikipedia writer and a topic expert, grounded in internet sources, to refine its understanding and generate detailed reports.
- Multi-Agent Collaboration: STORM employs a multi-agent system that simulates expert discussions, focusing on structured research and outline creation, and emphasizes proper citation and sourcing.
🔹Use Cases
- Academic Research: Assists researchers in generating comprehensive literature reviews and summaries on specific topics.
- Content Creation: Aids writers and journalists in producing well-researched articles with accurate citations.
- Educational Tools: Serves as a resource for students and educators to quickly gather information on a wide range of subjects.
Why Choose STORM?
- Automated In-Depth Research: STORM streamlines the process of gathering and synthesizing information, saving time and effort.
- Comprehensive Reports: By considering multiple perspectives and simulating expert conversations, STORM delivers well-rounded and detailed reports.
- Open-Source Accessibility: Being open-source, STORM allows for customization and integration into various workflows, making it a versatile tool for different users.
stanford-oval
/
storm
An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.
![]()
STORM: Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking
| Research preview | STORM Paper| Co-STORM Paper | Website |
Latest News 🔥
-
[2025/01] We add litellm integration for language models and embedding models in
knowledge-stormv1.1.0. -
[2024/09] Co-STORM codebase is now released and integrated into
knowledge-stormpython package v1.0.0. Runpip install knowledge-storm --upgradeto check it out. -
[2024/09] We introduce collaborative STORM (Co-STORM) to support human-AI collaborative knowledge curation! Co-STORM Paper has been accepted to EMNLP 2024 main conference.
-
[2024/07] You can now install our package with
pip install knowledge-storm! -
[2024/07] We add
VectorRMto support grounding on user-provided documents, complementing existing support of search engines (YouRM,BingSearch). (check out #58) -
[2024/07] We release demo light for developers a minimal user interface built with streamlit framework in Python, handy for local development and demo hosting (checkout #54)
-
[2024/06] We…
9️⃣ LLM-App by pathwaycom
22.5K Github Stars, 379 Forks
LLM-App is an open-source framework developed by Pathway.com, designed to integrate Large Language Models (LLMs) into data processing workflows.
Core Features
- Seamless LLM Integration: Allows for the incorporation of LLMs into various applications, enhancing data processing capabilities.
- Real-Time Data Processing: Utilizes Pathway's real-time data processing engine to handle dynamic data streams efficiently.
- Extensibility: Designed to be adaptable, enabling users to customize and extend functionalities based on specific requirements.
🔹Use Cases
- Data Analysis
- Natural Language Processing (NLP)
- Chatbots and Virtual Assistants
Why Choose LLM-App?
- Integration with Pathway's Engine: Combines the power of LLMs with Pathway's robust data processing engine for efficient real-time applications.
- Open-Source Flexibility: Being open-source, it allows for community contributions and customization to fit diverse use cases.
- Scalability: Designed to handle large-scale data processing tasks, making it suitable for enterprise applications.
pathwaycom
/
llm-app
Ready-to-run cloud templates for RAG, AI pipelines, and enterprise search with live data. 🐳Docker-friendly.⚡Always in sync with Sharepoint, Google Drive, S3, Kafka, PostgreSQL, real-time data APIs, and more.
Pathway AI Pipelines
Pathway's AI Pipelines allow you to quickly put in production AI applications that offer high-accuracy RAG and AI enterprise search at scale using the most up-to-date knowledge available in your data sources. It provides you ready-to-deploy LLM (Large Language Model) App Templates. You can test them on your own machine and deploy on-cloud (GCP, AWS, Azure, Render,...) or on-premises.
The apps connect and sync (all new data additions, deletions, updates) with data sources on your file system, Google Drive, Sharepoint, S3, Kafka, PostgreSQL, real-time data APIs. They come with no infrastructure dependencies that would need a separate setup. They include built-in data indexing enabling vector search, hybrid search, and full-text search - all done in-memory, with cache.
Application Templates
The application templates provided in this repo scale up to millions of pages of documents. Some of them are optimized for simplicity, some are optimized…
🔟 Neurite by satellitecomponent
1.4K Github Stars, 127 Forks

Neurite is an open-source project that offers a fractal graph-of-thought system, enabling rhizomatic mind-mapping for AI agents, web links, notes, and code.
Core Features
- Fractal Graph-of-Thought: Implements a unique approach to knowledge representation using fractal structures.
- Rhizomatic Mind-Mapping: Facilitates non-linear, interconnected mapping of ideas and information.
- Integration Capabilities: Allows integration with AI agents, enhancing their knowledge management and retrieval processes.
🔹Use Cases
- Knowledge Management
- AI Research
- Educational Tools
Why Choose Neurite?
- Innovative Knowledge Representation: Offers a novel approach to organizing information, beneficial for complex data analysis.
- Open-Source Accessibility: Allows users to customize and extend functionalities to suit specific needs.
- Community Engagement: Encourages collaboration and sharing of ideas within the knowledge management community.
satellitecomponent
/
Neurite
Fractal Graph-of-Thought. Rhizomatic Mind-Mapping for Ai-Agents, Web-Links, Notes, and Code.

🌐 neurite.network 🌐
Warning: Contains flashing lights and colors which may affect those with photosensitive epilepsy.
🌱 This is an open-source project in active development.

Introduction
Bridging Fractals and Thought
💡 neurite.network unleashes a new dimension of digital interface...
...the fractal dimension.
🧩 Drawing from chaos theory and graph theory, Neurite unveils the hidden patterns and intricate connections that shape creative thinking.
For over two years we've been iterating out a virtually limitless workspace that blends the mesmerizing complexity of fractals with contemporary mind-mapping techniques.
|
Bonus 🙂↕️: R2R by SciPhi-AI
5.4K Github Stars, 400 Forks
R2R is an advanced AI retrieval system that implements agentic Retrieval-Augmented Generation (RAG) with a RESTful API, developed by SciPhi-AI.
Core Features
- Agentic RAG System: Combines retrieval systems with generation capabilities to provide comprehensive responses.
- RESTful API: Offers a standardized API for easy integration into various applications.
- Advanced Retrieval Mechanisms: Utilizes sophisticated algorithms to fetch relevant information efficiently.
🔹Use Cases
- Intelligent Search Engines
- Content Generation
- Research Assistance
Why Choose R2R?
- Comprehensive AI Retrieval: Offers advanced retrieval capabilities, making it suitable for complex information retrieval tasks.
- Easy Integration: The RESTful API design allows for seamless integration into existing systems.
- Open-Source Community: Being open-source, it benefits from community contributions and continuous improvements.
SciPhi-AI
/
R2R
The most advanced AI retrieval system. Agentic Retrieval-Augmented Generation (RAG) with a RESTful API.

The most advanced AI retrieval system
Agentic Retrieval-Augmented Generation (RAG) with a RESTful API.



About
R2R (Reason to Retrieve) is an advanced AI retrieval system supporting Retrieval-Augmented Generation (RAG) with production-ready features. Built around a RESTful API, R2R offers multimodal content ingestion, hybrid search, knowledge graphs, and comprehensive document management.
R2R also includes a Deep Research API, a multi-step reasoning system that fetches relevant data from your knowledgebase and/or the internet to deliver richer, context-aware answers for complex queries.
Getting Started
Cloud Option: SciPhi Cloud
Access R2R through SciPhi's managed deployment with a generous free tier. No credit card required.
Self-Hosting Option
# Quick install and run in light mode
pip install r2r
export OPENAI_API_KEY=sk-
python -m r2r.serve
# Or run in full mode with Docker
# git clone git@github.com:SciPhi-AI/R2R.git && cd R2R
# export…
Here's a Quick Recap (only for you) 🙈
Below is a table that contains the list of all the RAG Frameworks mentioned in this blog:
| Framework | Key Features | Use Cases | Why Choose It? |
|---|---|---|---|
| LLMWare | End-to-end RAG pipeline, hybrid search, multi-LLM support | Enterprise search, document Q&A, knowledge retrieval | Highly optimized for unstructured data processing |
| LlamaIndex | Data connectors, structured retrieval, adaptive chunking | RAG-based chatbots, document search, financial/legal data analysis | Strong ecosystem with integrations and indexing optimizations |
| Haystack | Modular RAG, retrievers, rankers, scalable inference | Enterprise AI assistants, Q&A systems, contextual document search | Powerful for production-ready search applications |
| Jina AI | Neural search, multi-modal data, vector indexing | AI-powered semantic search, image/video/text retrieval | Scalable and fast for AI-driven search solutions |
| Cognita | RAG with knowledge graphs, retrieval re-ranking | AI-driven knowledge graphs, intelligent document search | Advanced retrieval using structured and unstructured data |
| RAGFlow | Graph-enhanced retrieval, hybrid search, deep document processing | Legal, finance, research document retrieval | Enterprise-ready, scalable, optimized for structured search |
| txtAI | Lightweight RAG, embeddings-based retrieval, easy deployment | Document similarity search, lightweight search engines | Fast and simple RAG for developers needing flexibility |
| STORM | Multi-hop retrieval, knowledge synthesis, LLM chaining | AI-driven research assistants, contextual understanding | Optimized for complex knowledge retrieval tasks |
| LLM-App | Fast streaming RAG, parallel retrieval, scalable indexing | Live AI chatbots, customer support automation | Efficient RAG with fast response time for high-load applications |
| Neurite | Multi-agent reasoning, multi-modal retrieval | Research assistance, AI-powered document analysis | Supports multi-modal inputs and collaborative AI reasoning |
| R2R | Reasoning-based retrieval, automated knowledge extraction | Scientific document processing, in-depth Q&A | Tailored for complex and logical reasoning in RAG |
But wait, Why can't we use LangChain over RAG Frameworks??
While LangChain is a powerful tool for working with LLMs, it is not a dedicated RAG framework. Here’s why a specialized RAG framework might be a better choice:
- LangChain helps connect LLMs with different tools (vector databases, APIs, memory, etc.), but it does not specialize in optimizing retrieval-augmented generation (RAG).
- LangChain provides building blocks for RAG but lacks advanced retrieval mechanisms found in dedicated RAG frameworks.
- LangChain is good for prototypes, but handling large-scale document retrieval or enterprise-level applications often requires an optimized RAG framework.
Conclusion: Choosing the right framework 😉
With a variety of open-source RAG frameworks available—each optimized for different use cases—choosing the right one depends on your specific needs, scalability requirements, and data complexity.
- If you need a lightweight and developer-friendly solution, frameworks like txtAI or LLM-App are great choices.
- For enterprise-scale, structured retrieval, LLMWare, RAGFlow, LlamaIndex, and Haystack offer robust performance.
- Jina AI and Neurite are well-suited for the task if you focus on multi-modal data processing.
- For reasoning-based or knowledge graph-powered retrieval, Cognita, R2R, and STORM stand out.
Finally, we are at the end of the blog. I hope you found it insightful. Please save it for the future. Who knows, when you need it!
Follow me on Github
RS-labhub (Rohan Sharma) · GitHub
Hi there!🧟 You're the most beautiful person I've ever met! Building @developersHub - RS-labhub
Thank you so much for reading! You're the most beautiful person I ever met. I have a lot of trust in you. Keep believing in yourself, and one day you will become motivation for others. 💖

Top comments (30)
Let me know if you want a blog on a specific framework!!
Thank you for reading!
Follow me on GH: github.com/RS-labhub
Langchain
Basically, everyone is trying to build their own RAG pipeline for their specific use case and then market them as a side gig... And I believe this abundance create analysis paralysis and as a result — creating another new RAG tool instead of selecting existing one 😅
In fact, I worked with llamaindex and in result needed to (re)implement some of their TS APIs because they were lacking at the moment. So all in all, implementing your own dedicated and specialized RAG tool is not such a bad idea actually (and not such a big deal too, depending on use case).
LangChain and GPTIndex started this way when ChatGPT was released first. And now they've grown bigger.
+1
You're right.
This factor decides a lot! But it's still great to use the pre-built tools to save time. If they are missing a specific feature, do contribute to that as they are open-source. 😉
Great post! I don't how many times i will return to reread it to check them out..
save it for later.. Ehehe 😉
Nice and detailed article. However, LlamaIndex and JinaAI are not RAG frameworks. They serve their purpose in a RAG or AI project pipeline/stack.
yes, but they help developers build production RAG pipelines. And this is much needed! So, I put them in the RAG framework. However, they are ultimately a RAG framework.
Thanks for including us!
Just to clarify, “LLM-App” is actually a set of ready-to-run AI pipelines built on top of Pathway’s core engine (rather than a standalone framework). It’s Docker-friendly, uses YAML-based configuration to define sources and pipeline logic, and stays continuously in sync with SharePoint, S3, databases, etc. We also have built-in indexing (vector/hybrid/full-text) for real-time search and RAG use cases.
If you’re curious about how it compares to other RAG solutions, feel free to check our in-depth comparison at pathway.com/rag-frameworks. Let us know if you have any questions—we’re always happy to help!
Thank you Saksham for sharing this with us. But every framework is different and there are pros and cons in all of them. 😉
This post provides an excellent introduction to RAG (Retrieval-Augmented Generation) frameworks and highlights their importance in enhancing LLM capabilities. The simplified explanation using a toy analogy makes it accessible even for beginners, while the step-by-step breakdown of RAG’s workflow effectively demonstrates its functionality.
The list of top open-source RAG frameworks is a valuable resource, starting with LLMWare.ai, which stands out due to its enterprise-friendly features like LLM orchestration, document processing, vector database integration, and custom fine-tuning. Its scalability and security make it particularly appealing for businesses looking to deploy AI-powered applications.
Thank you, Hassan!
Also, LLMWare.ai is one of the best RAG Frameworks. You can try it and let me know the feedback.
Awesome work man. I can see some really new ones here. 🔥 That table recap is nice too.
Thank you, Anmol. (and thank you for always helping me)
I thought a summarized table would be great as this blog was a little longer to read. I'm glad that you liked it! 🙈
Amazing listicle !
I'm glad you liked it!
check out github.com/FalkorDB/GraphRAG-SDK/t...
Graph Rag.. That's cool!!
Amazing, keep it up
Thank you!! I hope you enjoyed reading it. 😉
Some comments may only be visible to logged-in visitors. Sign in to view all comments.