
En muchas ocasiones, los cientificos de datos nos enfrentamos a la decisión sobre qué modelo usar para una determinada tarea de regresión o clasificación. Pero ante este dilema hay una respuesta sencilla que puede encajar muy bien en la mayoría de los proyectos.
Esta respuesta es nada mas ni nada menos que el Ensemble Learning (o aprendizaje en conjunto en su traducción al español).
Introducción a Ensemble Learning
En el campo del aprendizaje automático, si agrupamos las predicciones de un conjunto de algoritmos (tanto para clasificación como para regresión) vamos a obtener mejores resultados que con el mejor predictor individual.
Por ejemplo:
Entrenamos un grupo de Decision Trees, cada uno con un sub-grupo diferente de datos de entrenamiento. Luego, para realizar predicciones lo que hacemos es obtener los resultados de cada arbol y predecir la clase que obtiene mas votos (en caso de regresión, es el promedio de todas las predicciones).
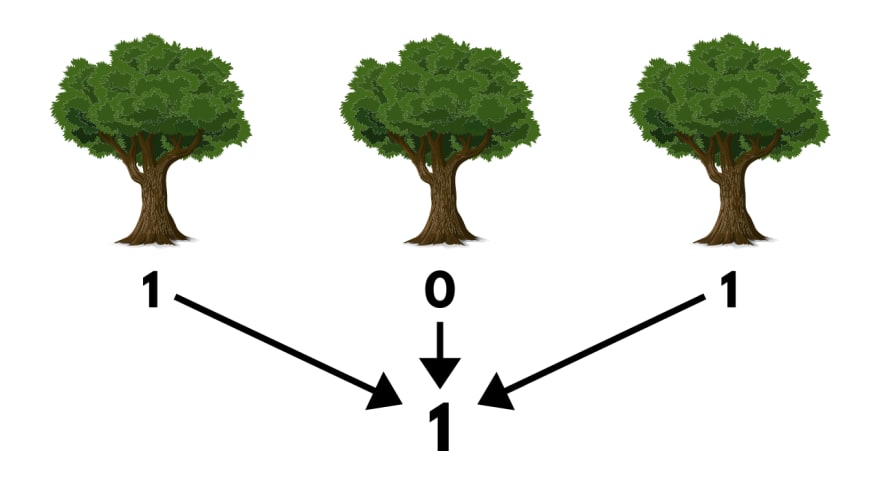
Veamos un ejemplo rapido para ver como funciona este metodo usando Scikit-Learn:
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
X, y = make_moons(n_samples=1000, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.35, random_state=42)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
LogisticRegression 0.8514285714285714
RandomForestClassifier 0.9142857142857143
SVC 0.9028571428571428
VotingClassifier 0.9057142857142857
Lo primero que hacemos es definir los modelos que vamos a agrupar para crear nuestro algoritmo. En este caso, vamos a usar RandomForestClassifier, LogisticRegression y SVC (Support Vector Classifier). Luego, agrupamos los tres modelos usando el metodo VotingClassifier y lo entrenamos.
El Ensemble Learning funciona mejor si los algoritmos a agrupar son los mas independientes posibles unos de otros. De esta manera, van a realizar distintos tipos de errores, mejorando la precisión del conjunto.
Diferencias entre hard y soft voting.
Si todos los clasificadores son capaces de estimar las probabilidades de cada clase (es decir, tienen disponible el metodo predict_proba()), entonces podemos configurar nuestro algoritmo grupal para que prediga la clase con la mayor probabilidad por clase, promediando los resultados dados por cada algoritmo. Esta tecnica es conocida como soft voting. En algunas ocasiones es capaz de obtener mejores resultados que el hard voting porque le da mayor peso a los votos mas probables de ser correctos. Lo unico que hay que hacer es reemplazar voting="hard" por voting="soft" y asegurarnos que todos los clasificadores estiman las probabilidades por clase. De manera predeterminada SVC no tiene esta opcion activada, por lo que debes configurar el hiper-parámetro probability como True (lo que hará que SVC use cross-validation para estimar las probabilidades de cada clase, volviendo mas lento el entrenamiento, y añadiendo el metodo predict_proba()).
Veamos como queda nuestro modelo en conjunto luego de estas modificaciones:
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC(probability=True)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
LogisticRegression 0.8514285714285714
RandomForestClassifier 0.92
SVC 0.9028571428571428
VotingClassifier 0.9142857142857143
Como podemos ver, nuestro modelo obtuvo unos resultados ligeramente mejores con soft voting.
Bagging y Pasting
Como ya vimos, una manera de tener un diverso grupo de clasificadores es usar diferentes algoritmos en la etapa de entrenamiento. Pero otra forma de obtener esto es usando un solo algoritmo durante todo el proceso pero entrenarlos con distintas porciones del set de datos de entrenamiento. Cuando el muestreo de datos se realiza con reemplazamientos, este metodo se llama bagging (abreviatura de bootstrap aggregating). Y cuando el muestreo es sin reemplazamiento, es llamado pasting.
En otras palabras, tanto el bagging como el pasting permiten muestrear instancias de entrenamiento varias veces en varios predictores, pero solo el bagging permite muestrear instancias de entrenamiento varias veces para el mismo predictor.

Una vez que todos los predictores son entrenados, el conjunto puede realizar una predicción para una nueva instancia agregando las predicciones de todos los predictores. La función de agregación es normalmente el modo estadístico (es decir, la predicción más frecuente, como un clasificador hard voting) para clasificación, o el promedio para regresión. Cada predictor individual tiene un sesgo mayor que si hubiera sido entrenado con el set de datos original, pero la agregación reduce el sesgo y la varianza. Generalmente, el resultado final es que el conjunto tiene un sesgo similar pero una varianza menor que un solo predictor entrenado con el set original.
Bagging y Pasting en Scikit-Learn
Se puede usar BaggingClassifier para tareas de clasificación, y BaggingRegressor para regresión.
Algunos parámetros para bagging son:
-
n_estimators: número de predictores en el conjunto. -
max_samples: número de muestras del set de entrenamiento para entrenar cada predictor. -
bootstrap:Truepara usar bagging,Falsepara usar pasting. -
n_jobs: número de núcleos del CPU para usar en el entrenamiento (-1usa todos los núcleos disponibles).
Acá tenemos un ejemplo de bagging:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=1000,
max_samples=200, bootstrap=True, n_jobs=-1, random_state=0)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
0.9057142857142857
Y por acá un ejemplo de pasting:
pas_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=1000,
max_samples=200, bootstrap=False, n_jobs=-1, random_state=0)
pas_clf.fit(X_train, y_train)
y_pred = pas_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
0.9085714285714286
Y por el simple hecho de comparar, veamos como resulta un solo Decision Tree haciendo todo el trabajo:
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
y_pred = tree.predict(X_test)
print(accuracy_score(y_test, y_pred))
0.8714285714285714
Tal como se esperaba, tenemos mejores resultados usando 1000 arboles en lugar de 1.
Conclusión
Espero que este articulo les haya ayudado tanto como me ayudó a mi mientras lo confeccionaba. Muchas gracias por llegar hasta aquí y ¡hasta la proxima!
Fin
¡Sorpresa para quienes llegaron al final!
Evaluación Out-of-Bag
Cuando usamos bagging, algunas instancias pueden ser seleccionadas varias veces para cualquier predictor, mientras que otros pueden no ser seleccionados en absoluto. Predeterminadamente, BaggingClassifier selecciona m instancias de entrenamiento con reemplazamiento (bootstrap=True), donde m es el tamaño del set de entrenamiento. Esto significa que en promedio solo el 63 % de las instancias de entrenamiento son seleccionadas para cada predictor. El 37 % restante (que no son las mismas para todos los predictores) de las instancias que no son muestreadas son llamadas instancias out-of-bag (oob).
Ya que un predictor nunca ve las instancias oob durante el entrenamiento, pueden ser utilizadas para evaluar sin la necesidad de un set de validación. Puedes evaluar al conjunto en si al promediar las evaluaciones oob para cada predictor.
En Scikit-Learn, puedes configurar oob_score=True cuando estas creando un BaggingClassifier para pedir una evaluación oob luego del entrenamiento. El resultado de la evaluación esta disponible a través de la variable oob_score:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
bootstrap=True, n_jobs=-1, oob_score=True)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
0.9061538461538462
De acuerdo a esta evaluación oob, este BaggingClassifier es capaz de alcanzar un 90.6 % de precisión en el test set. Vamos a verificarlo:
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
0.9142857142857143
¡Obtuvimos un 91.4 % de precision en el set de prueba! Bastante acertado.
Incluso tambien tenemos disponible la función de decisión oob:
bag_clf.oob_decision_function_
array([[0. , 1. ],
[0.97206704, 0.02793296],
[1. , 0. ],
...,
[0.99408284, 0.00591716],
[0.88333333, 0.11666667],
[0. , 1. ]])
Ahora sí es el final, muchas gracias por leerme. ¡Hasta luego!





Top comments (0)