PostgreSQL, a widely adopted open-source relational database management system (RDBMS), offers robust capabilities and is favored by numerous individuals and organizations globally. When starting with PostgreSQL, it is crucial to grasp the conceptual and physical composition of a PostgreSQL database cluster.
Logical Structure of Database Cluster
In PostgreSQL, a database cluster refers to a group of databases that are overseen by a PostgreSQL server operating on a single host. A database, within this context, encompasses various database objects like tables, indexes, views, sequences, and functions. It's worth noting that databases in PostgreSQL are considered as database objects themselves and are logically segregated from one another. The rest of the database objects are associated with their respective databases and are internally organized using object identifiers (OIDs).

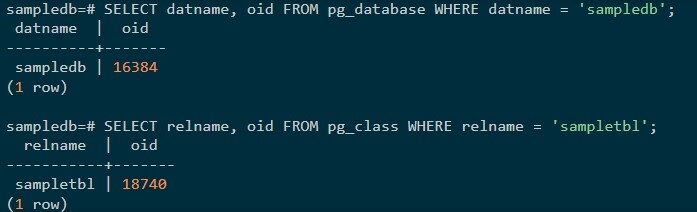
The relationships between database objects and their corresponding OIDs are stored in specific system catalogs, which vary depending on the type of object. For instance, the OIDs of databases are stored in the "pg_database" catalog, while the OIDs of heap tables are stored in the "pg_class" catalog. To retrieve the desired OIDs, you can utilize SQL queries to query the appropriate catalogs.
Physical Structure of Database Cluster
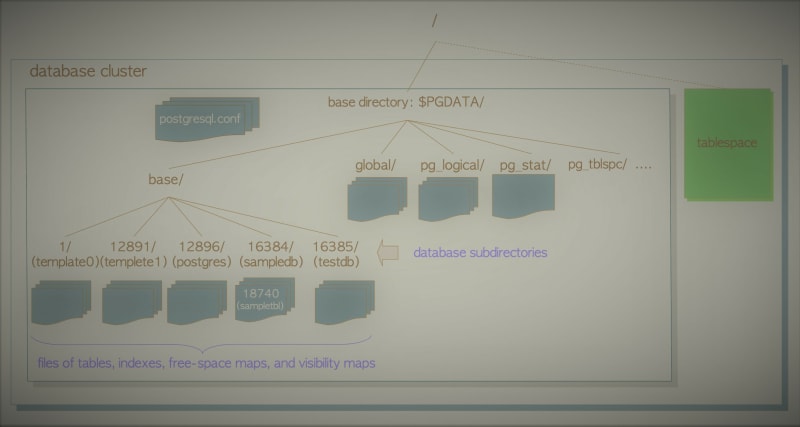
When you initialize a new PostgreSQL database cluster using the initdb utility, it creates a base directory. This base directory serves as the foundation for the cluster and encompasses several subdirectories and numerous files. Each database within the cluster is represented by a subdirectory within the base directory. Additionally, every table and index associated with a database is stored as at least one file within the respective subdirectory of that database.
In PostgreSQL, there is also support for tablespaces, which are directories that hold data outside of the base directory. Tablespaces are a unique feature specific to PostgreSQL and differ from tablespaces in other relational database management systems (RDBMS). These tablespaces offer flexibility in storing data in locations separate from the base directory.
For a clearer understanding of the PostgreSQL database cluster structure, please refer to the attached snapshot.
Layout of a Database Cluster
The layout of the PostgreSQL database cluster is described in the official documentation. Main files and subdirectories are listed under the base directory, including pg_xlog, pg_wal, pg_twophase, and pg_multixact.
Layout of Databases
A database is a subdirectory under the base directory, and the database directory names are identical to the respective OIDs. For example, when the OID of the database sampledb is 16384, its subdirectory name is 16384.
Layout of Files Associated with Tables and Indexes
Tables and indexes in PostgreSQL, as long as their size is less than 1GB, are stored as single files under the database directory to which they belong. These files are managed internally using individual Object IDs (OIDs). On the other hand, the actual data files are managed by a variable called "relfilenode." In general, the relfilenode values of tables and indexes correspond to their respective OIDs, establishing a basic matching relationship between them.
The Internal Layout of a Heap Table File
Data files in PostgreSQL, which include heap tables, indexes, as well as the free space map and visibility map, are divided into fixed-length pages or blocks. The default page size in PostgreSQL is 8 KB. Each page is assigned a unique block number, starting from 0 and increasing sequentially.
When a data file becomes full, PostgreSQL appends a new empty page to the end of the file to accommodate additional data and increase its size.
The internal structure of a page within a table consists of three main components: heap tuples, line pointers, and header data. Heap tuples represent the actual record data and are stored in a sequential order from the bottom of the page. Line pointers, which are 4 bytes in length, serve as pointers to each heap tuple. They form a simple array, acting as an index to the tuples. Each line pointer is assigned a unique offset number, starting from 1, to reference its corresponding tuple. When a new tuple is added to the page, a new line pointer is appended to the array to point to the newly added tuple.
This page layout allows for efficient storage and retrieval of data within a PostgreSQL data file.






Top comments (0)