What is GraphQL. What are its design concepts. How is it different from its alternatives. What are its advantages and disadvantages.

I am writing the GraphQL In Action book for Manning and 6 chapters (out of 11) has been published to MEAP.
Below is the entire first chapter of the book. Feedback is welcome and very much appreciated.
This chapter covers
- What GraphQL is and the design concepts behind it
- How GraphQL is different from its alternatives, like REST APIs
- The language and service parts of a GraphQL system
- The advantages and disadvantages of GraphQL
Necessity is the mother of invention. The product that inspired the creation of GraphQL was invented at Facebook because they needed to solve many technical issues with their mobile application. However, I think GraphQL became so popular so fast not because it solves technical problems but rather because it solves communication problems.
Communication is hard. Improving our communication skills makes our lives better on many levels and, similarly, improving the communication between the different parts of a software application makes that application easier to understand, develop, maintain, and scale.
That's really why I think GraphQL is a game-changer. It changed the game of how the different "ends" of a software application (front-end and back-end) communicate with each other. It gave equal powers to them, it made them independent of each other, it decoupled their communication process from its underlying technical transport channel, and it introduced a new rich language in a place where the common previously spoken language was limited to just a few words.
GraphQL powers many applications at Facebook today, including the main web application at facebook.com, the Facebook mobile application, and Instagram. Developers' interest in GraphQL is very clear and GraphQL's adoption is growing fast. Besides Facebook, GraphQL is used in many other major web and mobile applications like GitHub, Yelp, Pinterest, Twitter, The New York Times, Coursera, and Shopify. Given that GraphQL is a young technology, this is an impressive list.
In this first chapter, let's learn what exactly is GraphQL, what problems it solves, and what problems it introduces!
What is GraphQL
The word "graph" in GraphQL comes from the fact that the best way to represent data in the real world is with a graph data structure. If you analyze any data model, big or small, you'll always find it to be a graph of objects with many relations between them.
That was the first "aha" moment for me when I started learning about GraphQL. Why think of data in terms of resources (in URLs) on even join tables when you can beautifully think of it as a graph?
The "QL" in GraphQL might be a bit confusing though. Yes, GraphQL is a "Query Language" for data APIs but that's from the perspective of only the frontend consumer of these data APIs. GraphQL is also a runtime layer that needs to be implemented on the back-end and that layer is what makes the front-end consumer able to use the new "language".
The GraphQL "language" is designed to be declarative and efficient. Developers of data APIs consumers (like mobile and web applications) can use that language to request their exact data needs in a language close to how they think about data in their heads instead of the language related to how the data is stored or how data relations are implemented.
On the back-end, GraphQL needs a runtime. That runtime provides a structure for servers to describe the data to be exposed in their APIs. This structure is what we call a "schema" in the GraphQL world.
Any client can then use the GraphQL language to construct a text that represents their exact data needs using the back-end schema. The client then sends that text to the API service through a transport channel (for example, HTTP). The GraphQL runtime layer accepts that text request and then communicates with other services in the backend stack to put together a suitable data response for the text request. It'll then send that data back to the consumer in a format like JSON.

NOTE: GraphQL is not specific to any back-end or front-end framework, technical stack, or database. It can be used in any frontend environment, on any backend platform, and with any database engine. You can use it on any transport channel and make it use any data representation format.
In frontend Web or Mobile applications, you can use GraphQL with a client like Apollo or Relay or by manually making Ajax calls to a GraphQL server. You can use a library like React (or React Native) to manage how your views use the data coming from a GraphQL service but you can also do that with APIs native to their UI environments as well (like the DOM API or the native iOS components).
While you do not need React, Apollo, or Relay to use GraphQL in your applications, these libraries add more value to how you can leverage GraphQL APIs without having to do complex data management tasks.
The Big Picture
An API, in general, is an interface that enables the communication between multiple components in an application. For example, an API can enable the communication that needs to happen between a web client and a database server. The client needs to tell the server what data it needs and the server needs to fulfill this client's requirement with objects representing the data they asked for.
There are different types of APIs and every big application needs them. When talking about GraphQL, we are specifically talking about the API type that is used to read and modify data, which is usually referred to as a "Data API".
GraphQL is one option out of many that can be used to provide applications with programmable interfaces to read and modify the data they need from data services. Other options include REST, SOAP, XML, and even SQL itself.
SQL (the Standard Query Language) might be directly compared to GraphQL because "QL" is in both names, after all. Both SQL and GraphQL provide a language to query data schemas. They can both be used to read and modify data.
For example, assuming that we have a table of data about a company's employees, the following can be an example SQL statement to read data about employees in one department:
SELECT id, first_name, last_name, email, birth_date, hire_date
FROM employees
WHERE department = 'ENGINEERING'
Here is another example SQL statement that can be used to insert data for a new employee:
INSERT INTO employees (first_name, last_name, email, birth_date, hire_date)
VALUES ('John', 'Doe', 'john@doe.name', '01/01/1990', '01/01/2020')
You can use SQL to communicate data operations like we did above. The relational databases that these SQL statements are sent to usually support different formats for their responses. Each SQL operation type will have a different response. A SELECT operation might return a single row or multiple rows. An INSERT operation might return just a confirmation, the inserted rows, or an error response.
TIP: While possible, SQL would not be a good language to use for communicating data requirements directly by mobile and web applications. SQL is simply too powerful and too flexible and it would introduce many challenges. For example, exposing your exact database structure publicly would be a challenging security problem. You can put SQL behind another service layer but that means you need to come up with a parser and analyzer to perform operations on users' SQL queries before sending them to the database. That parser/analyzer is something that you get out of the box with any GraphQL server implementation.
While SQL is directly supported by most relational databases, GraphQL is its own thing. GraphQL needs a runtime service of its own. You cannot just start querying databases using the GraphQL query language (at least not yet). You will need to use a service layer that supports GraphQL or implement one yourself.
JSON is a language that can be used to communicate data. Here is a JSON text that can represent John's data:
{
"data": {
"employee":{
id: 42,
name: "John Doe",
email: "john@doe.name",
birthDate: "01/01/1990",
hireDate: "01/01/2020"
}
}
}
NOTE: Note how the data communicated about John does not have to be in the exact "structure" of how it is saved in the database. I used camel-case property names and I combined first_name and last_name into one name field.
JSON is a popular language to communicate data from API servers to client applications. Most of the modern data API servers use JSON to fulfill the data requirements of a client application. GraphQL servers are no exception; JSON is the popular choice to fulfill the requirements of GraphQL data requests.
JSON can also be used by client applications to communicate their data requirements to API servers. For example, here is a possible JSON object that can be used to communicate the data requirement for the employee object response:
{
"select": {
"fields": ["name", "email", "birthDate", "hireDate"],
"from": "employees",
"where": {
"id": {
"equals": 42
}
}
}
}
GraphQL for client applications is another language they can use to express their data requirements. The following is how the same previous data requirement can be expressed with a GraphQL query:
{
employee(id: 42) {
name
email
birthDate
hireDate
}
}
The GraphQL query above represents the same data need as the JSON object, but as you can see it has a different and shorter syntax. A GraphQL server can be made to understand this syntax and translate it into what the actual data storage engine can understand (for example, it would translate it into SQL statements for a relational database). Then, the GraphQL server can take what the storage engine responds with and translate it into something like JSON or XML and send it back to the client application.
This is nice because no matter what storage engine (or multiple storage engines) you have to deal with, with GraphQL you make API servers and client applications both work with a universal language for requests and a universal language for responses.
In a nutshell, GraphQL is all about optimizing data communication between a client and a server. This includes the client asking for the needed data and communicating that need to the server, the server preparing a fulfillment for that need and communicating that fulfillment back to the client. GraphQL allows clients to ask for the exact data they need and make it easier for servers to aggregate data from multiple data storage resources.
At the core of GraphQL, there is a strong type system that is used to describe the data and organize the APIs. This type system gives GraphQL many advantages on both the server and client sides. Types ensure that the clients ask for only what is possible and provide clear and helpful errors. Clients can use types to minimize any manual parsing of data elements. GraphQL type system allows for rich features like having an introspective API and being able to build powerful tools for both clients and servers. One of the popular GraphQL tools that relies on this concept is called GraphiQL, which is a feature-rich browser-based editor to explore and test GraphQL requests. You will learn about GraphiQL in the next chapter.
GraphQL is a specification
Although Facebook engineers started working on GraphQL in 2012, it was 2015 when they released a public specifications document for it. You can see the current version of this document by navigating to jscomplete.com/graphql-spec.
This document is maintained by a community of companies and individuals on GitHub. GraphQL is still an evolving language, but the specifications document was a genius start for the project because it defined standard rules and practices that all implementers of GraphQL runtimes need to adhere to. There have been many implementations of GraphQL libraries in many different programming languages and all of them closely follow the specification document and update their implementations when that document is updated. If you work on a GraphQL project in Ruby and later switch to another project in Scala, the syntax will change but the rules and practices will remain the same.
You can ultimately learn EVERYTHING about the GraphQL language and runtime requirements in that official specification document. It is a bit technical but you can still learn a lot from it by reading its introductory parts and examples. This book will not cover each and everything in that document, so I recommend that you skim through it once you are done with the book.
The specification document starts by describing the syntax of the GraphQL language. Let's talk about that first.
NOTE: Alongside the specification document, Facebook also released a reference implementation library for GraphQL runtimes in JavaScript. JavaScript is the most popular programming language and the one closest to mobile and web applications, which are two of the popular channels where using GraphQL can make a big difference. The reference JavaScript implementation of GraphQL is hosted at github.com/graphql/graphql-js and it's the one we will be using in this book. I'll refer to this implementation as "GraphQL.js".
GraphQL is a language
While the Q (for query) is right there in the name, querying is associated with reading but GraphQL can be used for both reading and modifying data. When you need to read data with GraphQL you use queries and when you need to modify data you use mutations. Both queries and mutations are part of the GraphQL language.
NOTE: Besides queries and mutations, Graphql also supports a third request type which is called a subscription and it's used for real-time data monitoring requests.
This is just like how you use SELECT statements to read data with SQL and you use INSERT, UPDATE, and DELETE statements to modify it. The SQL language has certain rules that you must follow. For example, a SELECT statement requires a FROM clause and can optionally have a WHERE clause. Similarly, the GraphQL language has certain rules that you must follow as well. For example, a GraphQL query must have a name or be the only query in a request. You will learn about the rules of the GraphQL language in the next few chapters.
A query language like GraphQL (or SQL) is different from programming languages like JavaScript or Python. You cannot use the GraphQL language to create User Interfaces or perform complex computations. Query languages have more specific use cases and they often require the use of other programming languages to make them work. Nevertheless, I would like you to first think of the query language concept by comparing it to programming languages and even to the languages that we speak, like English. This is a very limited-scope comparison, but I think in the case of GraphQL it will make you understand and appreciate a few things about it.
The evolution of programming languages in general is making them closer and closer to the human languages that we speak. Computers used to only understand imperative instructions and that is why we have been using imperative paradigms to program them. However, computers today are starting to understand declarative paradigms and you can program them to understand wishes. Declarative programming has many advantages (and disadvantages), but what makes it such a good idea is that we always prefer to reason about problems in declarative ways. Declarative thinking is easy for us.
We can use the English language to declaratively communicate data needs and fulfillments. For example, imagine that John is the client and Jane is the server. Here is an English data communication session:
John: Hey Jane, how long does it take the sun light to reach planet earth?
Jane: A bit over 8 minutes.
John: How about the light from the moon?
Jane: A bit under 2 seconds.
John can also easily ask both questions in one sentence and Jane can easily answer them both by adding more words to her answer.
When we communicate using the English language, we understand special expressions like "a bit over" and "a bit under". Jane also understood that the incomplete second question is related to the first one. Computers, on the other hand, are not very good (yet) at understanding things from the context. They need more structure.
GraphQL is just another declarative language that John and Jane can use to do that data communication session. It is not as good as the English language, but it is a structured language that computers can easily parse and use. For example, here's a hypothetical single GraphQL query that can represent both of John's questions to Jane:
{
timeLightNeedsToTravel(toPlanet: "Earth") {
fromTheSun: from(star: "Sun")
fromTheMoon: from(moon: "Moon")
}
}
This example GraphQL request uses a few of the GraphQL language parts like fields (timeLightNeedsToTravel and from), parameters (toPlanet, star, and moon), and aliases (fromTheSun and fromTheMoon). These are like the verbs and nouns of the English language. You will learn about all the syntax parts that you can use in GraphQL requests in Chapters 2 and 3.
GraphQL is a service
If we teach a client application to speak the GraphQL language, it will be able to communicate any data requirements to a backend data service that also speaks GraphQL. To teach a data service to speak GraphQL, you need to implement a runtime layer and expose that layer to the clients who want to communicate with the service. Think of this layer on the server side as simply a translator of the GraphQL language, or a GraphQL-speaking agent who represents the data service. GraphQL is not a storage engine, so it cannot be a solution on its own. This is why you cannot have a server that speaks just GraphQL and you need to implement a translating runtime layer.
A GraphQL service can be written in any programming language and it can be conceptually split into two major parts: structure and behavior.
The structure is defined with a strongly-typed schema. A GraphQL schema is like a catalog of all the operations a GraphQL API can handle. It simply represents the capabilities of an API. GraphQL client applications use the schema to know what questions they can ask the service. The typed nature of the schema is a core concept in GraphQL. The schema is basically a graph of fields which have types and this graph represents all the possible data objects that can be read (or updated) through the service.
The behavior is naturally implemented with functions that in the GraphQL world are named resolver functions and they represent most of the smart logic behind GraphQL's power and flexibility. Each field in a GraphQL schema is backed by a resolver function. A resolver function defines what data to fetch for its field.
A resolver function is where we give instructions for the runtime service about how and where to access the raw data. For example, a resolver function might issue a SQL statement to a relational database, read a file's data directly from the operating system, or update some cached data in a document database. A resolver function is directly related to a field in a GraphQL request and it can represent a single primitive value, an object, or a list of values or objects.
The GraphQL restaurant analogy
A GraphQL schema is often compared to a restaurant menu. In that analogy, the waiting staff act like instances of the GraphQL API interface. No wonder they use the term "server"!
Table servers take your orders back to the kitchen, which is the core of the API service. You can compare items in the menu to "fields" in the GraphQL language. If you order a steak, you need to tell your server how you'd like it cooked. That's where you can use field arguments!
order {
steak(doneness: MEDIUMWELL)
}Let's say this restaurant is a very busy one. They hired a chef with the sole responsibility of cooking steaks. This chef is the resolver function for the steak field!
TIP: Resolver functions are why GraphQL is often compared to the remote procedure call (RPC) distributed computing concept. GraphQL is essentially a way for clients to invoke remote - resolver - functions.
A schema and resolvers example
To understand how resolvers work, let's look at this simplified employee query and assume a client sent it to a GraphQL service:
query {
employee(id: 42) {
name
email
}
}
Simplified example query text
The service can receive and parse any request. It'll then try to validate the request against its schema. The schema has to support a top-level employee field and that field has to represent an object that has an id argument, a name field, and an email field. Fields and arguments need to have types in GraphQL. The id argument can be an integer. The name and email fields can be strings. The employee field is a custom type (representing that exact id/name/email structure).
Just like the client-side query language, the GraphQL community standardized a server-side language dedicated to creating GraphQL schema objects. This language is known as the "Schema Language". It's often abbreviated as SDL (Schema Definition Language) or IDL (Interface Definition Language).
Here's an example to represent the "Employee" type using GraphQL's schema language:
type Employee(id: Int!) {
name: String!
email: String!
}
This is the custom Employee type that represents the structure of an employee "model". An object of the employee model can be looked up with an integer id and it has name and email string fields.
NOTE: The exclamation marks after the types mean that they cannot be empty. A client cannot ask for an employee field without specifying an id argument and a valid server response to this field must include a name string and an email string.
TIP: The schema language type definitions are like the CREATE statements that we use to define tables (and other database schema elements).
Using this type, the GraphQL service can conclude that the employee GraphQL query is valid because it matches the supported type structure. The next step is to prepare the data it is asking for. To do that, the GraphQL service traverses the tree of fields in that request and invokes the resolver function associated with each field in it. It'll then gather the data returned by these resolver functions and use it to form a single response.
This example GraphQL service needs to have at least 3 resolver functions: one for the employee field, one for the name field, and one for the email field.
The employee field's resolver function might, for example, do a query like: select * from employees where id = 42. This SQL statement returns all columns available on the employees table. Let's say the employees table happens to have the following fields: id, first_name, last_name, email, birth_date, hire_date
So the employee field's resolver function for employee #42 might return an object like:
{
id: 42,
first_name: 'John',
last_name: 'Doe',
email: 'john@doe.com'
birth_date: "01/01/1990",
hire_date: "01/01/2020"
}
The GraphQL service continues to traverse the fields in the tree one by one invoking the resolver function for each. Each resolver function is passed the result of executing the resolver function of its parent node. So both the name and email resolver function receive this object (as their first argument).
Let's say we have the following (JavaScript) functions representing the server resolver functions for the name and email fields:
// Resolver functions
const name => (source) => `${source.first_name} ${source.last_name}`;
const email => (source) => source.email;
The source object here is the parent node. For top-level fields, the source object is usually undefined (because there is no parent).
TIP: The
The GraphQL service will use all the responses of these 3 resolver functions to put together the following single response for the employee GraphQL query:
{
data: {
employee: {
name: 'John Doe',
email: 'john@doe.com'
}
}
}
We'll start to explore how to write custom resolvers in Chapter 5.
TIP: GraphQL does not require any specific data serialization format but JSON is the most popular one. All the examples in this book will use the JSON format.
Why GraphQL
GraphQL is not the only - or even first - technology to encourage creating efficient data APIs. You can use a JSON-based API with a custom query language or implement the Open Data Protocol (OData) on top of a REST API. Experienced backend developers have been creating efficient technologies for data APIs long before GraphQL. So why exactly do we need a new technology?
If you ask me to answer the "Why GraphQL" question with just a single word, that word would be: Standards.
GraphQL provides standards and structures to implement API features in maintainable and scalable ways while the other alternatives lack such standards.
GraphQL makes it mandatory for data API servers to publish "documentation" about their capabilities (which is the schema). That schema enables client applications to know everything that's available for them on these servers. The GraphQL standard schema has to be part of every GraphQL API. Clients can ask the service about its schema using the GraphQL language. We'll see examples of that in Chapter 3.
Other solutions can be made better by adding similar documentations as well. The unique thing about GraphQL here is that the documentation is part of how you create the API service. You cannot have out-of-date documentation. You cannot forget to document a use-case. You cannot offer different ways to use APIs because you have standards to work with. Most importantly, you do not need to maintain the documentation of your API separately from that API. GraphQL documentation is built-in and it's first class!
The mandatory GraphQL schema represents the possibilities and the limits of what can be answered by the GraphQL service, but there is some flexibility in how to use the schema because we are talking about a graph of nodes here and graphs can be traversed using many paths. This flexibility is one of the great benefits of GraphQL because it allows backend and frontend developers to make progress in their projects without needing to constantly coordinate that progress with each other. It basically decouples clients from servers and allows both of them to evolve and scale independently. This enables much faster iteration in both frontend and backend products.
I think this standard schema is among the top benefits of GraphQL but let's also talk about the technological benefits of GraphQL as well.
One of the biggest technological reasons to consider a GraphQL layer between clients and servers, and perhaps the most popular one, is efficiency. API clients often need to ask the server about multiple resources and the API server usually knows how to answer questions about a single resource. As a result, the client ends up having to communicate with the server multiple times to gather all the data it needs.

With GraphQL, you can basically shift this multi-request complexity to the backend and have your GraphQL runtime deal with it. The client asks the GraphQL service a single question and gets a single response that has exactly what the client needs. You can customize a REST-based API to provide one exact endpoint per view, but that's not the norm. You will have to implement it without a standard guide.
Another big technological benefit about GraphQL is communicating with multiple services. When you have multiple clients requesting data from multiple data storage services (like PostgreSQL, MongoDB, and a REDIS cache), a GraphQL layer in the middle can simplify and standardize this communication. Instead of a client going to the multiple data services directly, you can have that client communicate with the GraphQL service. Then, the GraphQL service will do the communication with the different data services. This is how GraphQL isolates the clients from needing to communicate in multiple languages. A GraphQL service translates a single client's request into multiple requests to multiple services using different languages.
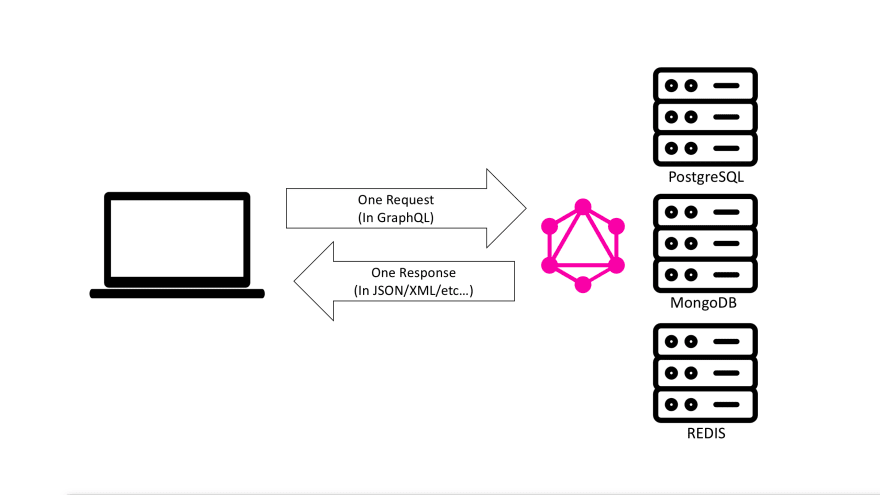
GraphQL is a translator
Imagine that you have three people who speak three different languages and have different types of knowledge. Then imagine that you have a question that can only be answered by combining the knowledge of all three people together. If you have a translator who speaks all three languages, the task of putting together an answer to your question becomes easy. This is what a GraphQL service can easily do for clients. This point is valid with other data API options, but GraphQL provides standard structures that enable implementing this kind of data need in easier and more maintainable ways.
One other benefit for GraphQL that I think is often underrated is how it improves the frontend "developer experience". The GraphQL schema gives frontend developers a lot of power and control to explore, construct, validate, test, and accurately perform their data need communication without depending on backend developers. It eliminates the need for the server to hardcode the shape or size of the data and it decouples clients from servers. This means that clients and servers can be developed and maintained separately from each other, which is a big benefit on its own.
More importantly, with GraphQL, developers express the data requirements of their user interfaces using a declarative language. They express WHAT they need, not HOW to make it available. There is a tight relationship between what data is needed by a UI and the way a developer can express a description of that data need in GraphQL.
What about REST APIs?
GraphQL APIs are often compared to REST APIs because the latter has been the most popular choice for data APIs demanded by web and mobile applications. GraphQL provides a more efficient "technology" alternative to REST APIS. But why do we need an alternative? What is wrong with REST APIs?
The biggest "relevant" problem with REST APIs here is the clients' need to communicate with multiple data API endpoints. REST APIs are an example of servers that require clients to do multiple network round-trips to get data. A REST API is a collection of endpoints where each endpoint represents a resource. So, when a client needs data about multiple resources it needs to perform multiple network requests to that REST API and then put together the data it needs by combining the multiple responses it receives. This is a big problem, especially for mobile applications, because mobile devices usually have processing, memory, and network constraints.
Furthermore, in a REST API there is no client request language. Clients do not have control over what data the server will return because they do not have a language to communicate their exact needs. More accurately, the language available for clients of a REST API is very limited. For example, the READ REST API endpoints are either:
-
GET /ResourceName- to get a list of all the records for that resource, or -
GET /ResourceName/ResourceID- to get a single record identified by an ID.
In a pure REST API (not a customized one) a client cannot specify which fields to select for a record in that resource. That information is in the REST API service itself and the REST API service will always return all of the fields regardless of which ones the client actually needs. GraphQL's term for this problem is over-fetching of information that is not needed. It is a waste of network and memory resources for both the client and the server.
One other big problem with REST APIs is versioning. If you need to support multiple versions that usually means new endpoints. This leads to more problems while using and maintaining these endpoints and it might be the cause of code duplication on the server.
NOTE: The REST APIs problems mentioned here are the ones specific to what GraphQL is trying to solve. They are certainly not all of the problems of REST APIs.
REST APIs eventually turn into a mix that has regular REST endpoints plus custom ad-hoc endpoints crafted for performance reasons. This is where GraphQL offers a much better alternative.
It is important to point out here that REST APIs have some advantages over GraphQL APIs. For example, caching a REST API response is a lot easier than caching a GraphQL API response, as you will see in the last section of this chapter. Also, optimizing the code for a REST endpoint is potentially a lot easier than optimizing the code for a generic single endpoint. There is no one magical solution that fixes all problems without introducing new challenges. REST APIs have their place and when used correctly both GraphQL and REST have their great applications. There is also nothing that prohibits the use of both of them together in the same system.
REST-ish APIs
Please note that in this book I am talking about pure REST APIs. Some of the problems mentioned here and solved by GraphQL can also be solved by customizing REST APIs. For example, you can modify the REST API to accept an "include" query string that accepts a comma-separated list of fields to return in the response. This will also avoid the over-fetching problem. You can also make a REST API include sub-resources with some query flags. There are tools out there that you can add on top of your REST-based systems and they can enable such customizations or make them easier to implement.
Such approaches might be okay on a small scale and I have personally used them before with some success. However, when compared to what GraphQL can offer, these approaches require a lot of work and will cause slower iterations in projects. They are also not standardized and will not scale very well for big projects.
The GraphQL Way
To see the GraphQL way for solving the problems of REST APIs that we talked about, you need to understand the concepts and design decisions behind GraphQL. Here are the major ones:
1) The Typed Graph Schema
To create a GraphQL API, you need a typed schema. A GraphQL schema contains fields that have types. Those types can be primitive or custom. Everything in the GraphQL schema requires a type. This static type system is what makes a GraphQL service predictable and discoverable.
2) The Declarative Language
GraphQL has a declarative nature for expressing data requirements. It provides clients with a declarative language for them to express their data needs. This declarative nature enables a thinking model in the GraphQL language that is close to the way we think about data requirements in English and it makes working with a GraphQL API a lot easier than the alternatives.
3) The Single Endpoint and the Client Language
To solve the multiple round-trip problem, GraphQL makes the responding server work as just one endpoint. Basically, GraphQL takes the custom endpoint idea to an extreme and just makes the whole server a single smart endpoint that can reply to all data requests.
The other big concept that goes with this single smart endpoint concept is the rich client request language that is needed to work with that single endpoint. Without a client request language, a single endpoint is useless. It needs a language to process a custom request and respond with data for that custom request.
Having a client request language means that the clients will be in control. They can ask for exactly what they need and the server will reply with exactly what they are asking for. This solves the problem of over-fetching the data that is not needed.
Furthermore, having clients asking for exactly what they need enables backend developers to have more useful analytics of what data is being used and what parts of the data is in higher demand. This is very useful data. For example, it can be used to scale and optimize the data services based on usage patterns. It can also be used to detect abnormalities and clients' version changes.
4) The Simple Versioning
When it comes to versioning, GraphQL has an interesting take. Versioning can be avoided altogether. Basically, you can just add new fields and types without removing the old ones because you have a graph and you can flexibly grow it by adding more nodes. You can leave paths on the graph for old APIs and introduce new ones. The API just grows and no new endpoints are needed. Clients can continue to use older features and they can also incrementally update their code to use new features.
By using a single evolving version, GraphQL APIs give clients continuous access to new features and encourage cleaner and more maintainable server code.
This is especially important for mobile clients because you cannot control the version of the API they are using. Once installed, a mobile app might continue to use that same old version of the API for years. On the web, it is easy to control the version of the API because you can just push new code and force all users to use it. For mobile apps, this is a lot harder to do.
This simple versioning approach has some challenges. Keeping old nodes forever introduces some downsides. More maintenance effort will be needed to make sure old nodes still work as they should. Furthermore, users of the APIs might be confused about which fields are old and which are new. GraphQL offers a way to deprecate (and hide) older nodes so that readers of the schema only see the new ones. Once a field is deprecated, the maintainability problem becomes a question of how long old users will continue to use it. The great thing here is that as a maintainer, you can confidently answer the questions "is a field still being used?" and "how often is a field being used?" thanks to the client query language. The removal of not-used deprecated fields can even be automated.
REST APIs and GraphQL APIs in action
Let's go over a one-to-one comparison example between a REST API and a GraphQL API. Imagine that you are building an application to represent the Star Wars films and characters. The first UI you are tackling is a view to show information about a single Star Wars character. This view should display the character's name, birth year, planet name, and the titles of all the films in which they appeared. For example, for Darth Vader, along with his name, the view should display his birth year (41.9BBY), his planet's name (Tatooine), and the titles of the 4 Star Wars film in which he appeared (A New Hope, The Empire Strikes Back, Return of the Jedi, Revenge of the Sith).
As simple as this view sounds, you are actually dealing with three different resources here: Person, Planet, and Film. The relationship between these resources is simple. We can easily guess the shape of the data needed here. A person object belongs to one planet object and it will have one or more films objects.
The JSON data for this view could be something like:
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}
Assuming that a data service can give us this exact structure, here is one possible way to represent its view with a frontend component library like React.js:
// The Container Component:
<PersonProfile person={data.person}></PersonProfile>
// The PersonProfile Component:
Name: {data.person.name}
Birth Year: {data.person.birthYear}
Planet: {data.person.planet.name}
Films: {data.person.films.map(film => film.title)}
This is a very simple example. Our experience with Star Wars helped us here to design the shape of the needed data and figure out how to use it in the UI.
Note one important thing about this UI view. Its relationship with the JSON data object is very clear. The UI view used all the "keys" from the JSON data object. See the values within curly brackets above.
Now, how can you ask a REST API service for this data?
You need a single person's information. Assuming that you know the ID of that person, a REST API is expected to expose that information with an endpoint like:
GET - /people/{id}
This request will give you the name, birthYear, and other information about the person. A REST API will also give you access to the ID of this person's planet and an array of IDs for all the films this person appeared in.
The JSON response for this request could be something like:
{
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planetId": 1
"filmIds": [1, 2, 3, 6],
... [other information that is not needed for this view]
}
Then to read the planet's name, you ask:
GET - /planets/1
And to read the films titles, you ask:
GET - /films/1
GET - /films/2
GET - /films/3
GET - /films/6
Once you have all six responses from the server, you can combine them to satisfy the data needed by the view.
Besides the fact that you had to do 6 network round-trips to satisfy a simple data need for a simple UI, the whole approach here is imperative. You gave instructions for how to fetch the data and how to process it to make it ready for the view. For example, you have to deal with the planet's and the films' IDs although the view did not really need them. You had to manually combine multiple data objects although you are implementing a single view that naturally need just a single data object.
Try asking for this data from a REST API yourself. The Star Wars data has an excellent REST API which is hosted at https://swapi.co where you can construct the same previous data object. The names of the data elements might be a bit different, but the endpoints structure is the same. You will need to do exactly 6 API calls. Furthermore, you will have to over-fetch information that the view does not need.
Of course, SWAPI is just one pure implementation of a REST API for this data. There could be better custom implementations that will make this view's data needs easier to fulfill. For example, if the API server implemented nested resources and understood the relationship between a person and a film, you could read the films data (along with the person data) with something like:
GET - /people/{id}/films
However, a pure REST API would not have that out-of-the-box. You would need to ask the backend engineers to create this custom endpoint for your view. This is the reality of scaling a REST API. You just add custom endpoints to efficiently satisfy the growing clients' needs. Managing custom endpoints like these is hard.
For example, if you customized your REST API endpoint to return the films data for a character, that would work great for this view that you are currently implementing. However, in the future, you might need to implement a shorter or longer version of the character's profile information. Maybe you will need to show only one of their films or show the description of each film in addition to the title. Every new requirement will mean a change is needed to customize the endpoint furthermore or even come up with brand new endpoints to optimize the communication needed for the new views. This approach is simply limited.
Let's now look at the GraphQL approach.
A GraphQL server will be just a single smart endpoint. The transport channel would not matter. If you are doing this over HTTP, the HTTP method certainly would not matter either. Let's assume that you have a single GraphQL endpoint exposed over HTTP at /graphql.
Since you want to ask for the data you need in a single network round-trip, you will need a way to express the complete data needs for the server to parse. You do this with a GraphQL query:
GET or POST - /graphql?query={...}
A GraphQL query is just a string, but it will have to include all the pieces of the data that you need. This is where the declarative power comes in.
Let's compare how this simple view's data requirement can be expressed with English and with GraphQL.
# In English:
The view needs:
a person's name,
birth year,
planet's name,
and the titles of all their films.
# In GraphQL:
{
person(ID: ...) {
name
birthYear
planet {
name
}
films {
title
}
}
}
Can you see how close the GraphQL expression is to the English one? It is as close as it can get. Furthermore, compare the GraphQL query with the original JSON data object that we started with.
# GraphQL Query (Question):
{
person(ID: ...) {
name
birthYear
planet {
name
}
films {
title
}
}
}
# Needed JSON (Answer):
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}
The GraphQL query is the exact structure of the JSON data object, except without all the "value" parts. If you think of this in terms of a question-answer relation, the question is the answer statement without the answer part.
If the answer statement is: +
The name of the Star Wars character who has the ID 4 is Darth Vader.A good representation of the question is the same statement without the answer part: +
(What is) the name of the Star Wars character who has the ID 4?
The same relationship applies to a GraphQL query. Take a JSON data object, remove all the "answer" parts (which are the values), and you end up with a GraphQL query suitable to represent a question about that JSON data object.
Now, compare the GraphQL query with the UI view that used it. Every element of the GraphQL query is used in the UI view and every dynamic part that is used in the UI view appears in the GraphQL query.
This obvious mapping is one of the greatest powers of GraphQL. The UI view knows the exact data it needs and extracting that requirement from the view code is fairly easy. Coming up with a GraphQL query is simply the task of extracting what is used as variables directly from the UI views. If you think about this in terms of multiple nested UI components, every UI component can ask for the exact part of the data that it needs and the application data needs can be constructed by putting these partial data needs together. GraphQL provides a way for a UI component to define the partial data need via a feature called "Fragments". You will learn about GraphQL fragments in Chapter 3.
Furthermore, if you invert this mapping model, you will find another powerful concept. If you have a GraphQL query, you know exactly how to use its response in the UI because the query will be the same "structure" as the response. You do not need to inspect the response to know how to use it and you do not need any documentation about the API. It is all built-in.
Star Wars data has a GraphQL API hosted at graphql.org/swapi-graphql. You can use the GraphiQL editor available there to test a GraphQL query. We'll talk about the GraphiQL editor in the next Chapter but you can go ahead and try to construct the example data person object there. There are a few minor differences that you will learn about later in the book, but here is the official query you can use against this API to read the data requirement for the same view (with Darth Vader as an example):
{
person(personID: 4) {
name
birthYear
homeworld {
name
}
filmConnection {
films {
title
}
}
}
}
Just paste this query in the editor area and hit the run button. This request will give you a response structure very close to what the view used, you expressed this data need in a way that is close to how you would express it in English, and you will be getting all of this data in a single network round-trip.
Is GraphQL a REST killer?
When I first learned about GraphQL, I tweeted that "REST APIs can REST IN PEACE!". Joking aside however, I don't really think that GraphQL is a REST APIs "killer". I do think however that more people will pick GraphQL over REST for APIs used by web and mobile applications. REST APIs have their place and I don't think that place is for web and mobile applications.
I like to think that GraphQL will do to REST what JSON did to XML. XML is still pretty heavily used but almost every web-based API I know of today uses the JSON format.
GraphQL offers many advantages over REST APIs but let's also talk about the challenges GraphQL brings to the table as well.
GraphQL Problems
Perfect solutions are fairy tales. With the flexibility GraphQL introduces, a door opens to some clear problems and concerns.
Security
One important threat that GraphQL makes easier is resource exhaustion attacks (AKA Denial of Service attacks). A GraphQL server can be attacked with overly complex queries that will consume all the resources of the server. It is very simple to query for deep nested relationships (user -> friends -> friends -> friends …) or use field aliases to ask for the same field many times. Resource exhaustion attacks are not specific to GraphQL, but when working with GraphQL you have to be extra careful about them.
NOTE: This resource-exhaustion problem can also come from non-malignant client applications which have certain bugs or just bad implementations. Remember that a GraphQL client is free to ask for whatever data it requires so it might just ask for too much data at once.
There are some mitigations you can do here. You can implement cost analysis on the query in advance and enforce some kind of limits on the amount of data one can consume. You can also implement a time-out to kill requests that take too long to resolve. Also, since a GraphQL service is just one layer in any application stack, you can handle the rate limits enforcement at a lower level under GraphQL.
If the GraphQL API endpoint you are trying to protect is not public and is designed for internal use by your own client applications (web or mobile), you can use a whitelist approach and pre-approve queries that the server can execute. Clients can just ask the servers to execute pre-approved queries using a query unique identifier. While this approach introduces back some dependencies between the servers and the clients, there are some automation strategies that can be used here to mitigate against that. For example, you can give the frontend engineers the freedom to modify the queries and mutations they need to use in development and then automatically replace them with their unique IDs during deployment to production servers. Some client-side GraphQL frameworks are already testing similar concepts.
Authentication and authorization are other concerns that you need to think about when working with GraphQL. Do you handle them before, after, or during a GraphQL resolve process?
To answer this question, think of GraphQL as a DSL (Domain Specific Language) on top of your own backend data-fetching logic. It is just one layer that you could put between the clients and your actual data services. Think of authentication and authorization as another layer. GraphQL will not help with the actual implementation of the authentication or authorization logic. It is not meant for that. But if you want to put these layers behind GraphQL, you can use GraphQL to communicate the access tokens between the clients and the enforcing logic. This is very similar to the way authentication and authorization are usually implemented in REST APIs.
Caching and Optimizing
One task that GraphQL makes a bit more challenging is client's caching of data. Responses from REST APIs are a lot easier to cache because of their dictionary nature. A certain URL gives a certain data so you can use the URL itself as the cache key.
With GraphQL, you can adopt a similar basic approach and use the query text as a key to cache its response. But this approach is limited, not very efficient, and can cause problems with data consistency. The results of multiple GraphQL queries can easily overlap and this basic caching approach would not account for the overlap.
There is a brilliant solution to this problem. A Graph Query means a Graph Cache. If you normalize a GraphQL query response into a flat collection of records and give each record a global unique ID, you can cache those records instead of caching the full responses.
This is not a simple process though. There will be records referencing other records and you will be managing a cyclic graph there. Populating and reading the cache will need query traversal. You will probably need to implement a separate layer to handle this cache logic. However, this method will be a lot more efficient than response-based caching.
One of the other most "famous" problems that you would encounter when working with GraphQL is the problem that is commonly referred to as N+1 SQL queries. GraphQL query fields are designed to be stand-alone functions and resolving those fields with data from a database might result in a new database request per resolved field.
For a simple REST API endpoint logic, it is easy to analyze, detect, and solve N+1 issues by enhancing the constructed SQL queries. For GraphQL dynamically resolved fields, it is not that simple.
Luckily, Facebook is pioneering one possible solution to both the caching problem and the data-loading-optimization problem. It's called DataLoader.
As the name implies, DataLoader is a utility you can use to read data from databases and make it available to GraphQL resolver functions. You can use DataLoader instead of reading the data directly from databases with SQL queries and DataLoader will act as your agent to reduce the SQL queries you send to the database.

DataLoader uses a combination of batching and caching to accomplish that. If the same client request resulted in a need to ask the database about multiple things, DataLoader can be used to consolidate these questions and batch-load their answers from the database. DataLoader will also cache the answers and make them available for subsequent questions about the same resources.
TIP: There are other SQL optimization strategies that you can use. For example, you can construct the optimal join-based SQL queries by analyzing GraphQL requests. If you are using a relational database with native efficient capabilities to join tables of data and re-use previously parsed queries, then a join-based strategy might actually be more efficient in many cases than IDs-based batching. However, IDs-based batching is probably a lot easier to implement.
Learning Curve
Working with GraphQL requires a bigger learning curve than the alternatives. A developer writing a GraphQL-based frontend application will have to learn the syntax of the GraphQL language. A developer implementing a GraphQL backend service will have to learn a lot more than just the language. They'll have to learn the API syntax of a GraphQL implementation. They'll have to learn about schemas and resolvers among many other concepts specific to a GraphQL runtime.
This is less of an issue in REST APIs for example because they do not have a client language nor do they require any standard implementations. You have the freedom of implementing your REST endpoints however you wish because you don't have to parse, validate, and execute a special language text.
Summary
The best way to represent data in the real world is with a graph data structure. A data model is a graph of related objects. GraphQL embraces this fact.
A GraphQL system has 2 main components. The query language that can be used by consumers of data APIs to request their exact data needs, and the runtime layer on the backend that publishes a public schema describing the capabilities and requirements of data models. The runtime layer accepts incoming requests on a single endpoint and resolves incoming data requests with predictable data responses. Incoming requests are strings written with the GraphQL query language.
GraphQL is all about optimizing data communication between a client and a server. GraphQL allows clients to ask for the exact data they need in a declarative way, and it enables servers to aggregate data from multiple data storage resources in a standard way.
GraphQL has an official specification document that defines standard rules and practices that all implementers of GraphQL runtimes need to adhere to
A GraphQL service can be written in any programming language and it can be conceptually split into two major parts: A structure that is defined with a strongly-typed schema representing the capabilities of the API and a behavior that is naturally implemented with functions known as resolvers. A GraphQL schema is a graph of fields which have types. This graph represents all the possible data objects that can be read (or updated) through the GraphQL service. Each field in a GraphQL schema is backed by a resolver function
The difference between GraphQL and its previous alternatives is in the fact that it provides standards and structures to implement API features in maintainable and scalable ways. The other alternatives lack such standards. GraphQL also solves many technical challenges like needing to do multiple network round-trips and having to deal with multiple data responses on the client
GraphQL comes with some many challenges especially in the areas of security and optimization. Because of the flexibility it provides, securing a GraphQL API requires thinking about more vulnerabilities. Caching a flexible GraphQL API is also a lot harder than caching fixed API endpoints (as in REST APIs). The GraphQL learning curve is also bigger than many of its alternatives.
Thanks for reading! The book is available at bit.ly/graphql-in-action





Top comments (3)
Here's a feedback. Comparing REST and GraphQL makes us authors sound stupid. I've learnt that the hard way and that's why I built the following to explain why:
medium.com/@fagnerbrack/the-real-d...
Excellent write-up. Fits nicely with the GraphQL 101 I'm holding with my employees next week. The benefits are really varied, but the philosophy goes in line with a lot of the concerns about API design that have plagued us for ages.
Thanks for the great ideas on how to approach this didactically!
I was just searching for what GraphQL is and this gave me a lot of insights, even more than what I was actually looking for.
Great Post BTW.