The use of empty strings when used to indicate a null value or lack of value, when the language you're using has a better way to support that will, will lead to bugs and hard to maintain code. With very few exceptions, empty strings should be avoided at all costs.
Several times over my career I have demonstrated the problem of using empty strings to colleagues, so I thought it was about time I write it up for you all to hopefully learn from.
Let's take a simple example. I'm going to use TypeScript for this article, but it's not a typescript article: it applies to any language that has a type system and that type system can express that a value is of type "string" or "undefined"/"null"/"nil"/"optional"/"maybe", etc.
So, let's take a look at a method that will return a name that supports a person having a nickname. Think of Dwayne "THE ROCK" Johnson.
function printName1(firstName: string, lastName: string, nickName: string) {
return `${firstName} "${nickName.toUpperCase()}" ${lastName}`;
}
For a simple call, this works fine. I can call it like this:
printName1('Dwayne', 'Johnson', 'The Rock')
And I get the output I expect. Dwayne "THE ROCK" Johnson
Now, I want to modify the code to support no nicknames. Not everyone has a nickname, so fair enough.
My first instinct might be to send no middle name.
printName1('Dwayne', 'Johnson')
But then the compiler kicks in, and my IDE tells me that I'm calling with 2 arguments instead of the expected three. Fair enough. But I'm in a hurry and I just need to get this done. So I can just work around this.
printName1('Dwayne', 'Johnson', '')
I don't bother to test it because I know that an empty string won't show anything. I roll it out to production and then my users start to complain.
Suddenly, we're seeing First "" Last in the UI - huh?
Ohhhhh. We didn't check for an empty string. Hmm. Okay then. Well, in this rare and privileged situation, I am both the author of and the consumer of the code. I wish the compiler could tell me to handle it, but alas, it does not, but I am smart and I can fix this.
function printName2(firstName: string, lastName: string, nickName: string) {
if (nickName.length > 0) {
return `${firstName} "${nickName.toUpperCase()}" ${lastName}`;
}
return `${firstName} ${lastName}`;
}
Good that works now. I've exploited the fact that I am in the lucky position of controlling both the function implementation and the caller of the code.
But what if you're not? Most the time you aren't.
We can do better, and lean on the compiler of our language to help us.
Let's say we instead chose to accurately express the function with more accurate types.
function printName3(firstName: string, lastName: string, nickName?: string) {
return `${firstName} "${nickName.toUpperCase()}" ${lastName}`;
}
Now we can call it both ways:
printName3('Dwayne', 'Johnson', 'The Rock')
printName3('Dwayne', 'Johnson')
And the compiler doesn't complain like it did the first time. No work arounds, no hacks. Much easier for the caller of the function.
And as the author of the function, we have an easier time too. We're able to communicate, without extra documentation or communication of any kind to the callers (which may be you, future you, a colleague or a person on the other side of the world..) what this method does and expects.
And secondly, as we're writing it, the compiler comes to the party and warns us that we haven't handled the possibility of a missing nickname.
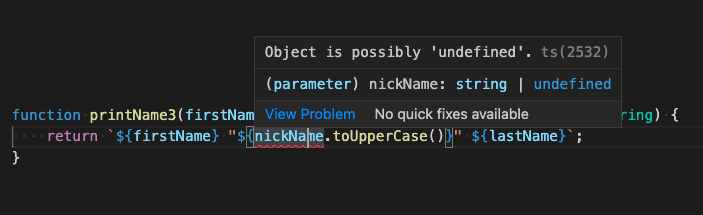
Awesome. We can fix that.
function printName3(firstName: string, lastName: string, nickName?: string) {
if (nickName) {
return `${firstName} "${nickName.toUpperCase()}" ${lastName}`;
}
return `${firstName} ${lastName}`;
}
The broader point here is that type systems are incredibly powerful and can check a lot of potential logical errors for you. However, it can only help you as much as you help it. By properly expressing to the compiler through the language that this string can be optional, we get the compiler helping us all the way through our code. By inventing our own indicator for optional strings - the empty string - we get no such help, and bugs find their way in very quickly, even with guards such as documentation.
So, this is why I consider empty string harmful in languages that have these features. It indicates a lack of understanding about the language and its ability to help you, the mistranslation of requirements into code and the possibility of future bugs.
However, there are a few exceptions to this rule. Generally these should only occur to the "entry point" and "exit point" of your codebase. For example, if you're dealing with an API, database or visual front end that has these contracts and may mean something semantically different, then it's fine at the last possible step to translate a value that is undefined into empty string.
eg:
drawHeading(article.heading, article.subtitle ?? '')
It's encouraged to do this at the final most step, and keep all your code between these "exits" and "entrances" to your code as accurately typed as possible, to maximise the above benefits.
I hope this has helped. Of course, this advices generalises to almost all primitives; using number | undefined instead of 0. Using boolean | undefined instead of false and even complex types, using combinations of the primitives.
Finally, have I got anything wrong here? Am I missing legitimate cases for empty strings? I'd love to hear about it :)





Top comments (0)