
At the Apache SeaTunnel (Incubating) Meetup in April, Wang Zichao, a senior backend engineer from oppo Smart Recommendation Sample Center, gave us a talk entitled The technical innovation in oppo Smart Recommendation Sample Centre based on Apache SeaTunnel (Incubating).
The presentation consisted of four main parts.
- Background of oppo’s introduction of Apache SeaTunnel(Incubating)
- The needs and goals of oppo
- The application of Apache SeaTunnel (Incubating) in practice
- oppo Sample Center

Wang Zichao, Senior Backend Engineer at oppo, responsible for oppo’s smart recommendation related data flow and platform construction, enjoys exploring new technologies
01 Background
01 Business background
The business background for the introduction of Apache SeaTunnel (Incubating) in the oppo Smart Recommendation Sample Centre is to meet the demand for intelligent recommendation online learning in the recommendation, search, and advertising scenarios. From the architecture diagram of the push and search platform above, we can see that the oppo Smart Sample Recommendation Center push platform is mainly divided into three layers, which are the engine, push search basis platform, and operation and maintenance layer, and we carry smart learning on the push and search basis platform.
The whole push and search platform support three main scenarios, which are recommendation, search, and advertising. The platform hosts a variety of businesses, including software shops, information flow, game centers, etc.
02 Intelligent recommendation for current data flow

The current data flow is divided into three parts, which are offline, nearline, and online. The offline part is to take some data reported by the recommendation engine, store it offline, and then carry out sample splicing, feature extraction, and a series of data processing to generate a brand new offline sample, the sample generation process usually takes more than a month or even more than half a year. Machine learning generates the BASE model through the training of the offline model.
The nearline data processing mainly uses the data reported by the recommendation engine as an offline log stream to complete the near real-time data processing process. After sample stitching, feature extraction, and other processing, offline samples of perhaps an hour or ten minutes period are generated for incremental model training, and the incremental models are subsequently pushed to online use.
03 Stove-piped development
Due to the need for quick gains in the early stages of development, we adopted the stove-piped development method, i.e. slicing and dicing for business scenarios, which resulted in more than 10 sets of business logic online, over 200 data processing tasks, and a wide range of languages, including Flink, Spark, Storm, MapReduce, SQL, Python, Java, C++, etc.
04 Business background
1、Operation and maintenance
The lack of uniformity in processes and data formats brings significant cost overhead to O&M and iterative work.
The complexity of technical frameworks places stringent requirements on technical staff.
The different calibers of offline and nearline bring risks to data consistency and increase the workload of data verification for algorithm and data engineers
2、Operation
As the data volume of feature snapshot will increase with the expansion of the number of features, currently a single feature snapshot data volume reaches 10M, and the current data flow of feature snapshot is between 2GB/s and 3GB/s, the excessive data volume will cause high overhead of computing resources and storage resources.
Second, the redundant rows of data links, the current length of data processing, from reporting to generation may take about three hours.
3、Iteration
The algorithm engineer needs to start from scratch to build the process if they want to complete the data iteration, which will cost up to a month. But in reality, 80% of the algorithm engineer’s energy is consumed in data samples, which is a great loss for development.
02 oppo’s needs and goals
Goal 1. Process unification
For this, we first need to unify the process of each business scenario, to maintain all scenarios and unified storage all by one set of engine code. Only one implementation process is needed for offline and nearline, and the final samples are stored in ICEBERG, which supplies both offline and nearline model training.
Goal 2. Structural unification
The second goal is to achieve structural uniformity. Although the sample format is different for each of our businesses, the overall data structure can be divided into the following three categories. Similarly, we hope to unify the storage structure, too, with a Pb serialization at the bottom, to reduce the consumption of data storage.

The sample structure, as we show above, is divided into three main parts.
The first is the business unit, which contains the meta information of the sample, such as user ID, advertising material ID, etc. The second part, real-time features, is mainly used to update user features or track user actions in real-time, such as which portrait or material corresponds to the user’s last 100 clicks, and subsequently pushing the content of the relevant category to users.
Finally, there are offline features, which are updated in a slightly longer period than before, such as the user’s age, city, gender, and other information, thus completing the abstraction of a sample.
Structured pipeline
In this section we want to abstract the entire data sample generation process into functional modules, hiding the details so that salesman can simply call the functional modules to build the data pipeline and focus more on the business itself. We have abstracted the structure into the following six parts.

03 Apache SeaTunnel (Incubating) in practice
Reasons for choosing Apache SeaTunnel (Incubating)
1、Apache SeaTunnel(Incubating) is based on Flink and Spark, two industry-recognized and more versatile engines, which are capable of synchronizing and processing data in both offline and real-time in the case of large data volumes.
2、Apache SeaTunnel (Incubating)’s abstraction and configuration logic philosophy is more in line with our goal of structuring the pipeline.
3、Apache SeaTunnel(Incubating) is highly extensible, so we can develop our components when we need some customization that Apache SeaTunnel(Incubating) itself does not offer.

01 stove-piped development changes to configurable development
The stove-piped development method we mentioned before has now changed to configurable development, using Apache SeaTunnel (Incubating) for the entire process, and can be used in practice after being configured via the configuration file below.

The unification of the overall build eases the pressure on our O&M staff and frees the algorithm engineers from the repetitive code development work.
02 Scenarios of tag generation
This is how oppo solves the problem of tagging, as mentioned above. Tag generation relies on positive and negative samples, for example, when we recommend the app to the user, we will get positive feedback if the user clicks to download, otherwise, if the user does not take any action, it is recorded as negative feedback.
There are two ways of generating tags. The first way is to combine the two events, exposure and click, into one event by a dual-stream/stream join, which will be trained by the model below. The dual-stream joins are usually done using Interval join and session windows, and can be easily implemented by using the SQL component of Apache SeaTunnel (Incubating).
The second way is the no join approach, which means that the two samples are not merged and both samples are sent down to the simulation training. At this point, we need to develop a plugin called time delay.
There is a time lag between the positive and negative samples, but we need to keep them as synchronized as possible to reach the model training. This is where the negative samples need to be delayed. The component below is a time-delay model that derives the time that the negative samples need to be delayed based on some meta-information in the negative samples, ensuring that the samples are time-consistent.

03 Feature stitching scenario
This scenario is the log join of user behavior logs and feature snapshots as we mentioned above. we first store the feature snapshots in a KV database, such as HBase, ScyllaDB, etc., currently, we use HBase more often.


Therefore, we have developed a JoinHbaseProcessor plugin, which can be used directly without any additional development by the algorithm engineer, as long as configured with the HBase address, corresponding field names, and other information.
04 Business background
Monitoring and alerting are very important in the development work of data streams. There are usually two monitoring metrics, one is the data volume and the second is the time. And there are two ways of monitoring, the first is our custom-developed monitoring plug-in which will report on buried points based on the upstream input data stream. The diagram below shows the use of a plugin that simply sets the name of the monitor and the tags of the buried point to be monitored.

The second way is assuming that we have some more customized monitoring requirements, which may require computational processing of the data to get the desired monitoring data. Our HBase plug-in has a built-in reporting burial point, which will continue to report the monitoring data as the task runs, and the corresponding calculations can be performed to get the desired data on the monitoring board.

04 Background
After using Apache SeaTunnel (Incubating) to implement all the data processes, we need to re-develop on top of it to build the platform of the sample center.
We hope the sample center featured four characters.
- Structured design, i.e. pipeline
- Stream and batch integration, i.e. the proximity line can be implemented with one set of configurations
- Multi-version switching
- Algorithm engineers can use it autonomously

(A platform process in the sample center, where samples can be generated by simply entering sample units and real-time features)
Here I would like to emphasize the multi-version switching function. Generally, there is a mainline process on the line, and after the mainline has gone through the functional components, a baseline sample library is generated for use on the line. However, if an algorithm engineer needs business exploration or algorithm experimentation, a convenient copy can be made on the business process pipeline.
If the user validates the new version of the data process and finds that the second version works better and wants to switch between versions, they can switch directly to the second version as the online version.

In our feature center, we mainly provide some of the features such as features registration, quality, sharing, production, storage, and services, which are re-developed based on Apache SeaTunnel (Incubating).
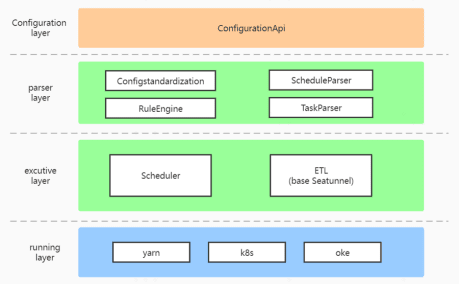
This is the technical architecture of the sample center, which is divided into four layers: the configuration layer, the parsing layer, the execution layer, and the runtime layer. We will focus on two points, the first is the ETL in the execution layer, which is re-developed based on Apache SeaTunnel and allows for graphical task configuration and task start/stop management based on individual data tasks.
The second is the configuration layer, which allows users to generate and configure uniform task links and to start and stop work. The configuration layer parses the information into two parts, the scheduling information among tasks and the individual ETL task configuration information.
The ETL translates the configuration information into SeaTunnel task information, which is run down to the runtime layer, and finally reaches the system interaction process of the sample center.
With the current sample center, the overall data link has been upgraded from offline to real-time, which is a significant improvement in the effectiveness of the algorithm strategy. In terms of the sample construction cycle time, it has been reduced from weekly to hourly; in terms of data latency, it has been reduced from three hours to ten minutes; in terms of stability, SLA service availability has reached the standard of three 9s, with no major failures so far.
05 Future plan
- Cloud-native scheduling, with all execution layers migrated to the cloud, which fits with Apache SeaTunnel (Incubating) support for K8s
- One-stop machine learning
- Full link data quality construction
That’s all for my talk, thanks for your patience.
Join the Community
There are many ways to participate and contribute to the DolphinScheduler community, including:
Documents, translation, Q&A, tests, codes, articles, keynote speeches, etc.
We assume the first PR (document, code) to contribute to be simple and should be used to familiarize yourself with the submission process and community collaboration style.
So the community has compiled the following list of issues suitable for novices: https://github.com/apache/dolphinscheduler/issues/5689
List of non-newbie issues: https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
How to participate in the contribution: https://dolphinscheduler.apache.org/en-us/community/development/contribute.html
GitHub Code Repository: https://github.com/apache/dolphinscheduler
Official Website:https://dolphinscheduler.apache.org/
Mail List:dev@dolphinscheduler@apache.org
Twitter:@DolphinSchedule
YouTube:https://www.youtube.com/channel/UCmrPmeE7dVqo8DYhSLHa0vA
Slack:https://s.apache.org/dolphinscheduler-slack
Contributor Guide:https://dolphinscheduler.apache.org/en-us/community/index.html
Your Star for the project is important, don't hesitate to lighten a Star for Apache DolphinScheduler ❤️





Top comments (0)