In the past few years, more applications than ever before are being built on the public cloud and as microservices-based apps on Kubernetes. As a result, the nature of application development has changed significantly.
Firstly, applications are composed of increasing numbers of microservices which talk to each other using APIs. Secondly, applications are increasingly composed of heterogeneous components. This includes managed databases, message queues, data warehouses, serverless infrastructure, third party APIs, and so on.
With both of these changes occurring simultaneously, the development and testing process has gotten more complex than the days of the monolith. This has made it necessary to rethink tooling, processes, and methodologies in order to manage complexity and enable developers to not only move fast but do so with confidence.
The Software Development Lifecycle
With a modern DevOps process, code “travels” through different stages in its journey to production which helps ensure that it is functionally correct, has the right behavior, meets the business needs, is performant under load, etc. This process is what we call the software development lifecycle (SDLC). It is an iterative and agile process involving several feedback loops - some that are automated and some manual involving engineers, product / project managers and other stakeholders. In the context of microservices-based applications, two considerations that require special attention in the development lifecycle are:
- Quality and Accuracy of feedback from each stage of the software development process
- How early (in the sdlc process) is feedback available to developers
The quality of feedback is important because we want to make sure that each feedback loop catches real issues and improves code quality. Inaccurate feedback loops waste developer time and reduce trust in the checks themselves. The timing of feedback is important because the sooner in the development lifecycle it is available, the quicker it is to fix and verify. For example, an issue found before code merges is quicker to fix and verify than an issue found after code has merged.
Both quality and timing of feedback loops depend on the environment from which the feedback is generated. Next, we look at the different types of environments that exist in the typical development lifecycle.
Typical Environment Setup
In a moderate to large sized company that uses microservices, the environments which roughly correspond to the stages that code goes through are represented as follows. There are 3 major stages.
Development Environments
These are environments that are used during tight iterative development inner loops as a developer edits and adds new code on their IDE in the design phase. In a microservices-based application, they are focused on bringing up a minimal environment where some combination of manual and automated tests can be run quickly for immediate feedback.
These types of environments are often brought up locally using a tool like docker-compose, or in some cases, run within Kubernetes using a dedicated namespace that is running a copy of the microservices stack.
Continuous Integration Environments
These are environments used by continuous integration pipelines to run tests prior to code merging. Very often, these environments are closer to development environments in that they are designed to be quick to bring up and inexpensive to run a large number of tests in parallel. In this testing phase, the typical CI environment is optimized for speed rather than trying to be a copy of the production environment where the code will eventually run.
Staging Environments
The staging environment can be thought of as the first time all the changes come together into an environment that resembles production. The dependencies available in a staging environment are real databases, message queues, 3rd party APIs etc.
Code that ends up in the staging environment has gone through the prior two stages before ending up in staging and this roughly correlates with code being committed into the main branch of the code repository.
Staging Bottlenecks
When the number of microservices and the complexity of the stack scales up, the development lifecycle starts to bottleneck on the staging environment. This manifests in the following ways:
- Issues are missed in earlier environments and discovered on staging which results in long feedback loops for developers.
- Increased use of the staging environment for validation of code changes causes it to become unstable and increases the maintenance and operational burden for the development team.
Some creative solutions for the above problems that we’ve encountered at this point include introducing policies like “locking” a staging environment so as to allow a developer / team to test their changes without interference, or creating multiple staging Kubernetes clusters at increased cost of infrastructure and maintenance.
If we take a step back and take a look at the root cause of why a bottleneck exists at the staging environment, it is due to lack of isolation between various users & tenants that want to use this environment concurrently.
Scaling Staging Environments
If we could create a large number of staging-like environments with real dependencies, 3rd party APIs, data sources, and so on which is a replica of the production environment and make it available to every developer, that would solve the aforementioned bottleneck on the staging environment.
The brute force solution of just turning up new infrastructure and copies of the entire stack to solve this problem is feasible at small scale. This solution can also employ the built-in multi-tenancy offered by Kubernetes using namespaces. However, beyond the scale of few tens of microservices, this approach suffers from the following drawbacks:
- Maintainability & Cost: The cost of infrastructure and maintenance for each staging environment and the time required to set them up scale linearly with the number of microservices.
- Drift: The separate stacks of microservices are constantly drifting away from each other because updates are constantly being pushed to each component of the stack. This makes it hard to get high-quality software test signals.
In order to realize staging environments at scale without burning a hole in your pocket, we must consider a different approach.
Sandbox Environments
Sandbox Environments are virtual environments within a single shared Kubernetes cluster. These virtual environments are isolated from one another at the level of network requests. In this development model, the workloads under test are deployed into the same Kubernetes cluster side by side with other test workloads and the stable version. Requests that are targeted to a particular Sandbox Environment are routed through the test workload as opposed to the stable version.

A setup similar to this has been realized at scale by leaders in the industry such as Doordash, Lyft and Uber. The workflow starts with a Kubernetes cluster into which all microservices are being continuously deployed at the version corresponding to the latest “main” or “master” branch. This environment is called the baseline. When a developer decides to test a new version of a microservice that they are building, they do the following:
- Deploy the test workload into the same cluster containing the baseline.
- Automation picks it up and stitches together a virtual sandbox environment containing that new workload along with the other services from the baseline environment. This automation ensures that requests that are intended for that sandbox environment are routed through that test workload as opposed to the baseline version of that service.
- The developer now runs manual and automated tests by making use of the sandbox environment that has been set up.
With Signadot, we automate and manage the above process of setting up Sandbox Environments. Using a Kubernetes-native approach, each sandbox gets its own unique identifier and endpoint, as well as ephemeral resources like databases or message queues for isolation. Once the Sandbox Environment is set up, requests to the endpoint can exercise your test service instead of the baseline service while not disrupting the baseline environment.
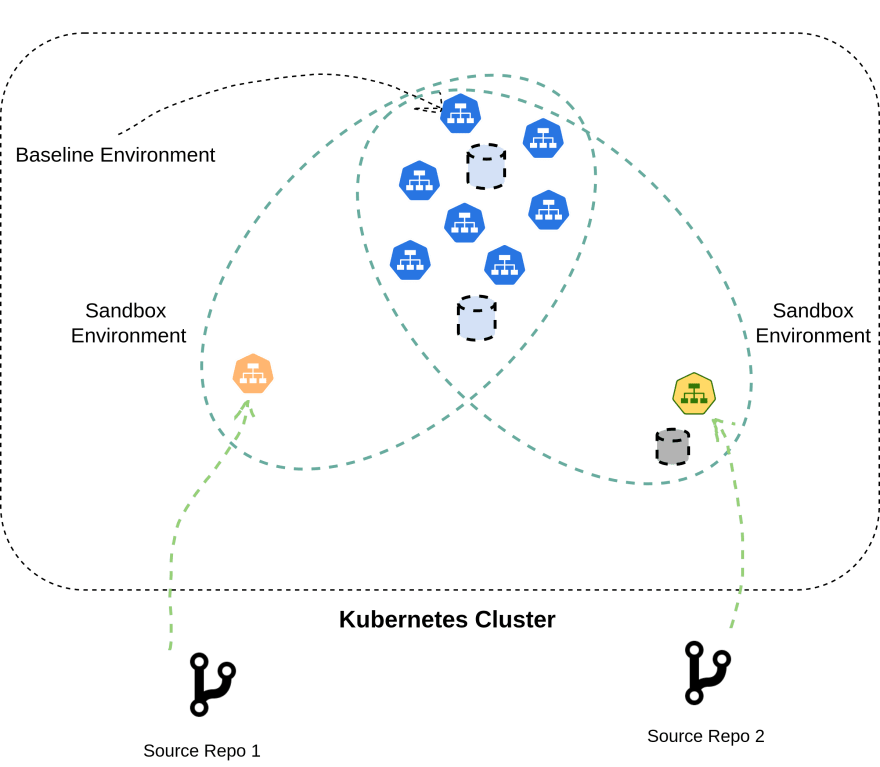
Bringing together multiple services for testing into a single sandbox environment is possible through multiple mechanisms such as context propagation and runtime configuration. Sandbox environments are dynamic and easy to construct on the fly. For each scenario, you can construct an environment with some combination of microservices, bring them up, run tests and tear them down once the tests are completed.
This model can easily scale to hundreds or thousands of sandbox environments that can run manual and automated tests in parallel. Effectively, the Sandboxes model is similar to the copy-on-write model of resource sharing, resulting in the infrastructure cost incurred being only that of deploying the test workloads as opposed to the entire set of dependencies. By making use of a baseline environment that is “live” and up-to-date with the master branches of each microservice, tests are always run with the latest dependencies which resolves the problems of drift and stale feedback.
The top-most consideration for isolation in these sandbox environments is dealing with state and stateful components correctly. To learn more about different approaches that can be used to solve it, as well as how we chose to solve it at Signadot using Sandbox Resources, look out for details in a future blog post.
Conclusion
With microservices, we have learned to manage the complexity of modern applications by splitting it into smaller and more manageable chunks that can all be developed and deployed separately. However, this change requires us to change the way we think about the development lifecycle and adopt a more holistic view of improving it. We need to think not just about tests themselves but also where they run and how we can make the most useful signals available as early as possible.
Sandbox environments are an important tool to consider in the software delivery lifecycle as a way to overcome an emerging bottleneck in the traditional staging environment, and enable development processes to scale without every developer paying the cost of additional complexity.





Top comments (0)