For some, web crawling and web scraping are the same things. If you are one of those people - you've come to the right place, because web crawling and web scraping are not really synonymous. Here we explore what both of them actually are, what they are used for, and what is the difference between them.

What is Web Crawling?
Ultimately, web crawling is indexing all the information on a web page. Bots, also called crawlers or spiders, review every page, every URL, hyperlink, meta tag, and HTML text on the website, looking at all pieces of data presented there. The information found is then indexed and archived. Web crawlers keep track of what they've already visited, so they don't get stuck on the same site.
What is Web Scraping?
Web scraping is a process of automated data extraction from publicly available internet pages. The bots used for this are called web scrapers. Usually, they target specific data sets, such as prices, product details, etc. The data gathered is structured in a usable and downloadable format, e.g. Excel spreadsheets or databases in CSV, HTML, JSON, or XML formats. The data collected by the scrappers are then used for comparison, verification, or analysis relevant to the specific needs. The automated process takes significantly less time and provides more accuracy in comparison with the manual collection.
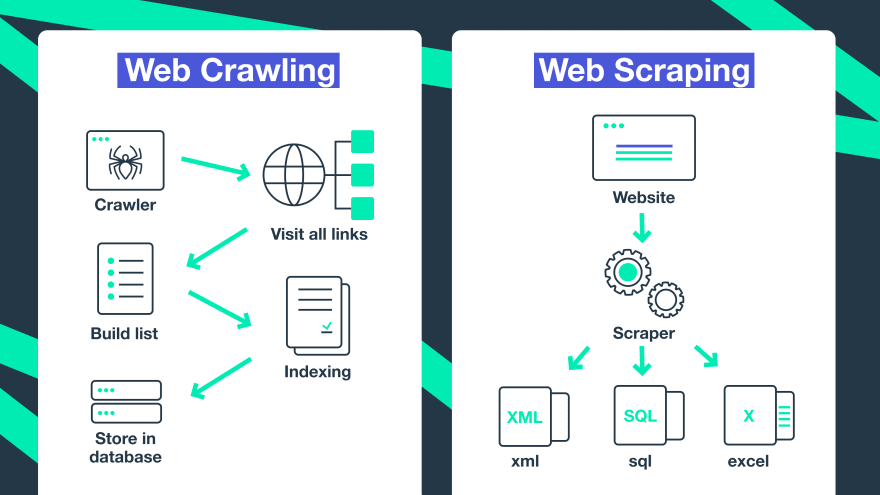
What Crawling and Web Scraping Can Be Used for?
The most notable application of web crawlers is in search engines. Google, Bing, Yahoo, Yandex, large online aggregators, and alike are constantly deploying their bots to keep their search results accurate. With so much information appearing on the internet every day, their bots never rest, constantly going through the pages and refreshing their indexes.
There are multiple applications for web scraping.
It can be used for all kinds of research, from purely academic to specifically business-oriented. Web scraping allows collating of quantitative and qualitative data for scholarly research in different fields. Retail and e-commerce companies can benefit from competitors' analysis and market intelligence performed by scrapers. It is an easy automated way of collecting information about the inventory, special promotions, changes in prices, reviews, and the emergence of new trends in the field. It can be also used in marketing for lead generation and fine-tuning SEO strategy. Furthermore, it can help with brand protection and news aggregation. Scrapers are able to collect user-generated content to help companies address any grievances and changes in the customers' perceptions. It can also help track the activity of any wrongdoers trying to benefit from the brand. Web scrapers are also utilized in the real estate business. It can quickly gather data about the properties in the specific area placed on the different web resources. This allows keeping track of any changes and good offers available.
So, web scraping can be a great tool to gather data for further analysis and decision-making.
What are the Advantages of Crawling and Web Scraping?
Crawling and scraping are performing different functions within any data-driven research. They can and are often used together as they complement each other.
The Benefits of Crawling:
- Full picture. Crawling allows indexing every page of the targeted source. This means nothing can hide from the eyes of eager researchers.
- Updated information. Web crawling keeps the target data sets up-to-date. This results in the up-and-coming competitors and information sources not slipping through and being included in further analysis.
- Quality assurance. A web crawler is a good tool for the assessment of content quality.
The Benefits of Web Scraping:
- Accuracy. The information users receive through web scraping equals the information the bot found online. There are no humans involved in the data collection, so it is reflecting the source 100%.
- Cost efficiency. Manual collection of data is laborious and time-consuming. Outsourcing it to a scraper allows for saving staff hours.
- Targeted approach. It is possible to set up a scraper to target the information you specifically need, for example, prices, images, or descriptions. This saves time and bandwidth, and, as a result, money.
What are the Challenges of Crawling and Web Scraping?
Both web crawling and web scraping share the same challenges.
- Preventative policies. Many domains have anti-crawling and anti-scraping policies in place. This can cause delays in data gathering or even an IP address block. To avoid this proxy for business can be employed. They substitute the real IP address of the user with an alternative one from a wide range of IPs. This protects the user's privacy and makes data harvesting more efficient.
- Capacity. Web crawling and web scraping as well as the analysis of the data acquired can be laborious and time-consuming. At the same time, the demand for information and data-driven decisions is constantly on the rise. Using automated solutions for these processes can save businesses resources.
Difference Between Crawling and Web Scraping
The crawling and scraping are two different processes that can be used together for more automation and achieving better results. Crawling is finding the information online and indexing it, essentially making users aware it is there. Scraping is filtering out the required information from the found sources, structuring the data in an actionable format, and downloading it into the device.
Let's finish by summing up the key differences between web crawling and web scraping:

This post was originally published on SOAX blog





Top comments (3)
Awesome article thats a good comparison of the differences. Love using Python for this stuff.
Awesome! Tag me in the article if you ever decide to write one about web scraping / crawling using Python :)
Wow that's amazing how this blog explains the differences between web crawling and web scraping simply and understandably. It's really helpful for anyone who wants to learn about collecting information from the Internet. Plus, if you're looking for a tool to make web scraping easier, you should check out Crawlbase. Keep up the good work in making complex topics easy to understand!