As many others did before and regretted later, we’ve decided to move a big part of our workload from long-running processes to Lambda. That said, we haven’t regretted it a bit. It’s been a breeze so far, even if there are a few shortcomings of Lambda, which are just annoying.
In this blog post, I’ll describe the positive sides, the negatives, and the approach we’ve taken that allowed us to radically simplify our setup, as well as clarify common misconceptions you might have about AWS Lambda development.
But first of all, let’s take a look at…
Our Architecture
Our backend is based on two main constructs:
- The server, which exposes GraphQL and REST APIs to the outside world.
- The drain, which consumes a bunch of SQS queues to handle asynchronous jobs. Each SQS queue transports several event types, based on a logical separation (webhooks, async jobs, cronjobs, etc.)
We have a very asynchronous architecture. The server often emits async jobs instead of doing something by itself, and the drain often emits new events when handling existing ones.
Because we’re a CI/CD system, our traffic patterns are very unevenly distributed. Sometimes there are few jobs, at other times, somebody creates an avalanche of them.
Until recently, the drain was a long-running process on ECS, reading from multiple SQS queues. Autoscaling in such a situation is fairly hard. The simplest option is to have a separate process per SQS queue, with each process scaled independently. Even doing this would have resulted in paying too much for periods of low traffic, along with handling spikes in traffic too slowly. The diagram below describes that architecture visually:

Also, everything on the backend is written in Go, no exceptions.
Changing Our Codebase for Lambda
Many people think that moving to Lambda requires huge codebase changes and has to result in having a lot of binaries, one for each Lambda Function. That’s actually not necessary. Yes, Lambda does only call the binary without any arguments (and there’s no way to change that to my knowledge – I tried), but you can provide arbitrary environment variables.
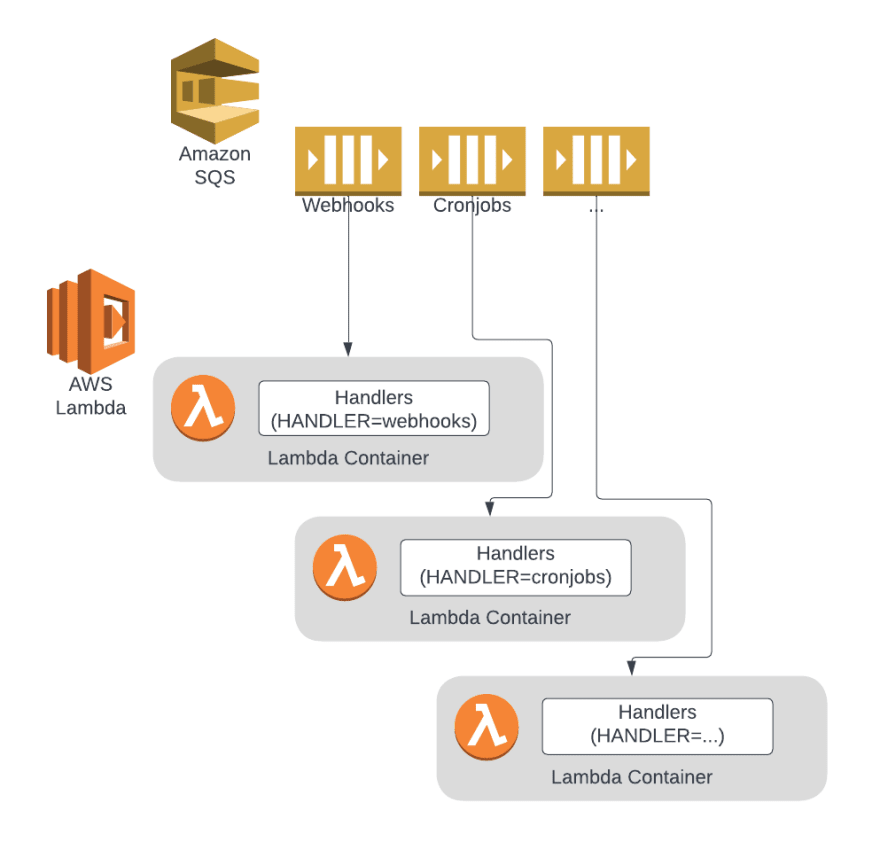
In our case, we have a single spacelift binary that will run the server process if called as spacelift backend server, but if called as plain spacelift, then it assumes it’s being run as a Lambda handler and will take a look into the HANDLER environment variable to deduce which handler to actually run. This way, we can keep using a single binary for everything, and operational simplicity ensues. The following diagram shows the new setup:
Local Development
Lambda can also be quite annoying for local development. The way we solve this is by having all of our handlers – as you’ve seen above – fronted by SQS queues. This way we can run the handlers locally, and have a shim that polls the SQS queue (a copy the given developer has), translates it into the Lambda-native SQS message format, and passes that to the handler. Very similar to the way the original setup worked, but just for local development.
In practice, this means we have a spacelift backend local-drain command that just runs all handlers with their respective SQS queue pollers. That gets recompiled on each code change, so the feedback loop from code change to locally deployed new binary is around 5 seconds and you can easily attach a debugger to it.
Handling Secrets
On ECS, the system we moved from, you can just specify a list of environment variables and mark their sources as “to be taken from SecretsManager”. With Lambda, that’s not possible. However, we wanted to keep dependency injection uniform across the codebase, so we wanted to have the same flow in Lambda as before.
Thus, we just pass a plain environment variable with the list of objects to get from SecretsManager. The Lambda binary will get those objects from SecretsManager, iterate over all key values in each, and set them as environment variables on the current process. This happens first-thing after starting, so the rest of our initialization process is oblivious to it. This might sound like a hack, but it’s simple, and it does the job.
for _, secret := range strings.Split(os.Getenv("SECRETS_MANAGER_ENVIRONMENT_VARIABLE_KEYS"), ",") {
value, err := sm.GetSecretValue(&secretsmanager.GetSecretValueInput{
SecretId: aws.String(secret),
})
if err != nil {
log.Fatal(err)
}
var data []byte
if value.SecretBinary != nil {
data = value.SecretBinary
} else {
data = []byte(*value.SecretString)
}
var pairs map[string]string
if err := json.Unmarshal(data, &pairs); err != nil {
log.Fatal(err)
}
for k, v := range pairs {
if err := os.Setenv(k, v); err != nil {
log.Fatal(err)
}
}
}
Container Images vs. Zip Archives
Another misconception about Lambda is that Container Image support means it can take arbitrary Docker images and run them as-is. Unfortunately, that’s not true.
Container Images in Lambda basically work as a glorified file archive, nothing more, nothing less. Your binary still has to adhere to the Lambda communication protocol, Although you can still use Docker to build your image. The main difference is that thanks to the improved caching story, they let you use 10 GB images instead of just 50 MB for ZIP archives.
Another difference is that with Container Images you can’t configure Lambda layers to be used through the AWS console, as you can with ZIP archives. That said, you can easily copy layers into your Container Image:
COPY --from=public.ecr.aws/datadog/lambda-extension:21 /opt/extensions/ /opt/extensions
Function Lifecycle and Asynchronous Goroutines
The way your Lambda Function works is that it gets spun up, launches your binary, which can do any setup it wants and then starts polling for jobs from the Lambda runtime. Then, when the Lambda is not needed anymore (scaling down) it gets terminated.
So, you can use goroutines to do some async tasks in your Lambdas while they’re running, right? Well, no.
The Lambda Runtime will actually freeze your process between invocations. This means that if you have an async process doing work between invocations, it might be frozen right after it tries to do an IO operation and be woken up 30 seconds later, which makes the IO operation time out immediately.
In other words, you can’t safely use async processes in your Lambda binaries – at least not outside a single invocation’s timespan. Also, make sure that your database doesn’t terminate connections if it didn’t get a keepalive in 30 seconds, in case you’re connecting to it directly (which btw. was not an issue for us).
The Lambda SQS Connector
It’s not ideal.
With Lambdas, there is a concept of throttling. It happens when you try to invoke a lot of Lambdas at once, but they can’t scale fast enough. Lambda will then return a 429 error.
So, if you suddenly have lots of SQS messages, the SQS connector will scale up and send lots of invocations which might fail with the 429 error. So, the SQS connector will slow down and retry them in a second, right?
Well, no. Instead of retrying with those most recent messages a moment later, it will actually fail the message handling and put it back to SQS to be handled again after the visibility timeout passes (which might take several minutes). That is not great and can introduce additional delays in times of high traffic.
That said, we haven’t encountered this issue again since setting up high reserved concurrent execution numbers on the Lambda functions. Based on the last few months of usage, this has been a non-issue to us.
Resetting a Lambda
With most systems, often “turn it off and back on again” is a quite good incident recovery mechanism. Your code gets into an unexpected state, and this way you reset it.
With Lambda, however, there’s no obvious way to invalidate all the current warm Lambda runtimes. So, if you need this, the way to go is actually to add a useless environment variable, so that you have a change, and then deploy it. Deploying will invalidate old Lambda runtime versions, and effectively “turn it off and back on again”.
Cost and Scalability
As described in the beginning, we often encounter load spikes, which required us to have many machines on standby before moving to Lambda. With Lambda, this works beautifully out of the box. Whenever we get a huge amount of events at a moment’s notice, Lambda is able to scale up to 10x the capacity, quickly handle all the events, and then scale down.
Moreover, we achieve all of this while having drastically reduced the cost of the whole setup. Lambdas for asynchronous event processing are very cost-effective. I’m not sure I’d recommend them for synchronous HTTP services, but here they definitely do shine.
Operational Simplicity
Lambdas deploy instantaneously. They have perfect isolation – we don’t have to worry about one Function’s execution influencing any other Function, by starving resources or something similar. Cold starts are very short with Go, warm starts are basically instant. So as far as these considerations are concerned, we’re very happy.
After migrating to Lambdas, they required very little upkeep, and haven’t been a source of incidents.
Summary
Overall, we’re very satisfied with our new setup. I hope the above lessons learned can be useful to somebody else considering the same switch, or planning their greenfield project on Lambda.





Top comments (0)