
Related GitHub Repo
https://github.com/ssghost/JITS_tests
Abstract
just-in-time (JIT) compilation is a way of executing computer code that involves compilation during execution of a program (at run time) rather than before execution. As the industry of designing Deep-learning frameworks stride forward into the so-called "Roman Times" (2019 - 2020), most of the mainstream frameworks have engaged their own JIT compilations into their backends in their latest installation packages. This phenomenon might be described as an intense armament competition of various JIT compilers.
So why not we make a benchmark to measure the actual efficiencies of those JIT compilers to draw a brief illustration of the over-all mechanism under those different implementations of JIT?
The idea is simple, we have two metrics to measure, the performance time and the result accuracy (in this case we use the proximity to the value of pi). The former is shorter, the latter is higher, the compiler is better, and vice versa.
The participants are also shown in the cover image, which are : Numba, JAX, Tensorflow, Triton.
The function that will be identically executed by those 4 JIT backends on my laptop CPUs is Monte Carlo Pi Approximation, which can approximately approach the actual value of pi.
Write the Decorators
Before we start, the functions to implement the measurement of those metrics must be well designed. Python has a powerful inherent toolkit called "Decorator", which is an elegant way to wrap up our measurement procedures. Here we wrote two decorator functions, they have the same structure as below:
def benchmark_metric(func: Callable[..., Any]) -> Callable[..., Any]:
@functools.wraps(func)
def wrapper(*args: Any, **kwargs: Any) -> Any:
value = func(*args, **kwargs)
metric = f(value)
logging.info(f"Function {func.__name__}'s metric value is {metric:.2f}")
return value
return wrapper
Your JIT calling function will be wrapped up into and execute inside this decorator, a metric value will be computed synchronously and displayed as a logging information in the terminal window.
Afterwards, All your need to do is just to put an "@" statement before your JIT calling functions.
Write the Calling Functions
As we can see in the follow pseudo-codes, interestingly, all the 4 types of JIT compiler's backends are also decorators. Consequently every calling function will have at least 3 layers of decorators, 2 for benchmarks, 1 for calling JIT backends.
Firstly, we might consider the situation that we are not using the JIT backends, just implement the Monte Carlo Pi Approximation in a plain Python function, and the pseudo-code for this algorithm gonna be like below:
def monte_carlo_pi(ln: int):
acc = 0
for _ in range(ln):
x = random.random()
y = random.random()
if (x**2 + y**2) < 1.0:
acc += 1
return 4.0 * acc / ln
Obviously, it is a loop based approach which means we should repeat this procedure with many many times to get an optimized result, the more times we repeat, the more accuracy we will acquire. The repeat times will be a "Large Number" (ln). A plotted chart to depict this procedure is somehow like this:
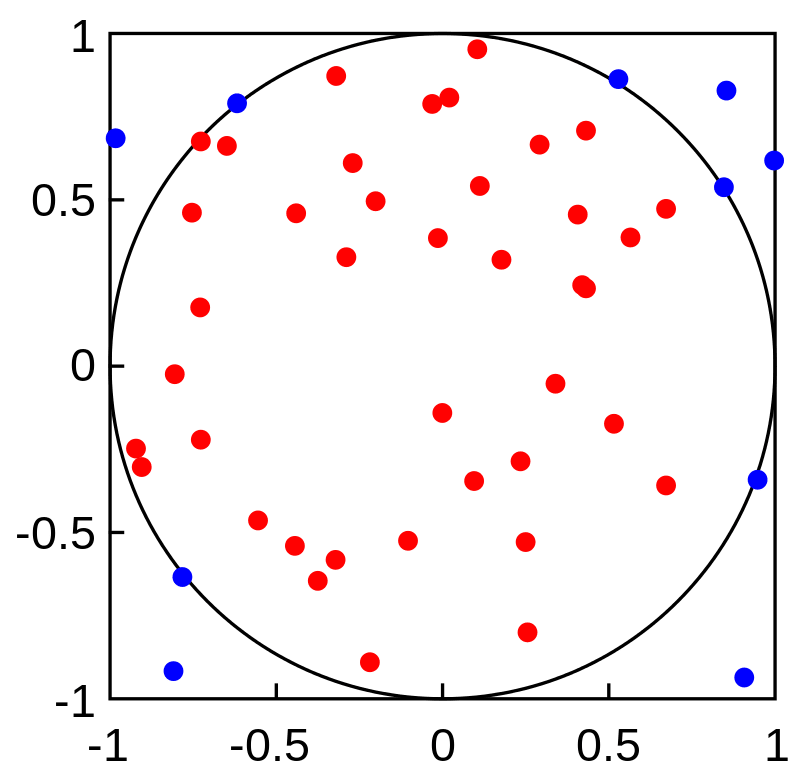
As we repeated nearly infinite times, the ratio of red dots over the sum of red and blue dots will be approximately equal to the ratio of the area of the circle over the area of the square. And hence we can eventually compute the value of pi based on this ratio.
For Numba, a significant difference is that we no more need to call Numpy or some Numpy-like packages to pre-processing (or more specifically, "compressing") your data into a structured vector space. So surprisingly, we can just copy and paste our pseudo-code under the @ statements and it will run correctly as we expected. That's why I put Numba as the first participant of our competition.
But for the other 3 JIT backends, things gonna be a little complicated. We have to do some regular pre-processing for our data. Fortunately, JAX and Tensorflow both have there own integrated Numpy module, we can just import and call them to compress our data into Numpy arrays and do all the computations with those Numpy arrays (that means, all other data types are not modified to feed into their JIT backends).
For Triton, although Triton doesn't have a Numpy-like package, its language module itself can do the similar compressing process as Numpy arrays did. Unlike Numpy arrays, Triton's inherent data structure involved a concept of offset rather than array shapes to demonstrate the quantities of higher dimensions.
Results
As to describe the results of our JIT competition, Matplotlib should be a neat choice. We will plot 8 charts, 2 metrics for each participants, with an array of input variable - the repeating times. Let's go directly to check out these charts.
Well, at my first glance of these 4 pairs of charts, I might say their shapes appeared almost identical. Only Numba had acquired a trivial enhancement in the metric of perf_time. To save the reading time, here I finally decided to post the two metrics results of Numba as a typical example:


Conclusions
Modern DL frameworks have constructed almost identical efficient JIT compilation backends with their own data structure designing.
A key-point to enhance the performance of JIT backends running in a CPU-only environment is to optimize the data compressing procedures.
There might be a best trade-off point between perf_time and value_acc which is near 10^6 to 10^7 according to my result charts, that may infer a trivial hint for further explorations.





Top comments (0)