
What exactly is the Online Schema Change Problem ?
Traditionally Changing a table's schema on the go has been one of the most challenging problems in relational databases, In today's fast paced applications & agile dev cycles, Database crew often find that they need to make changes to the schema frequently & sometimes on a weekly basis. Running an Alter Table or any DDL statement will put the table in an inaccessible state, including reads. This is the kind of downtime which most applications cannot simply afford to have. That drives the need for a no downtime Online schema solution.
CockroachDB's Online Schema Change Overview
CockroachDB was actually architected from ground-up to be highly available & Resilient for all OLTP needs and while we had the chance to address this Online Schema changes Problem, we agreed that we want to provide a simpler way to update the schema using any DDL statements and make sure the system doesn't suffer any negative consequences during this change. The schema change engine is a built-in feature requiring no additional tools, resources, or ad-hoc sequencing of operations.
For instance, when you run Alter on a table in CRDB, a background job gets kicked off in the background and CRDB engine seamlessly takes care of converting the old schema with the new changes without holding locks on the underlying table data.
So basically, Your application's queries can run normally without affecting any read/write latency and the data is in a consistent state throughout the entire schema change process allowing you to access the old data until the new changes are rolled out.
For detailed Information of how this is done internally you can checkout our
Official documentation
Testing out Online Schema Changes with CRDB's Dedicated cloud
Now, lets see how cockroach DB can handle online schema changes in reality. For the exercise here, the goal is to make changes to the schema in an active system and see if CRDB engine can handle the changes gracefully with no downtime.
Pre-work before the exercise
- Created a Dedicated Cluster in CRDB with the below configuration
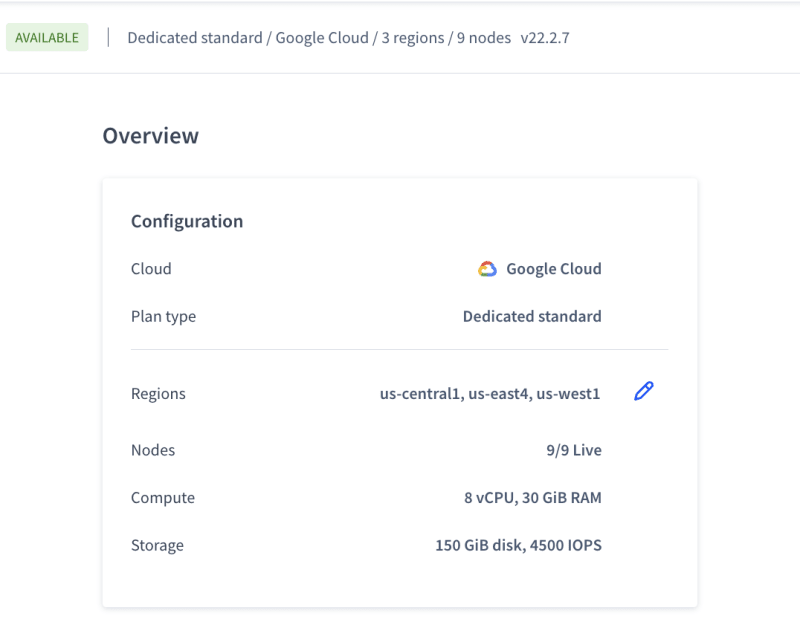
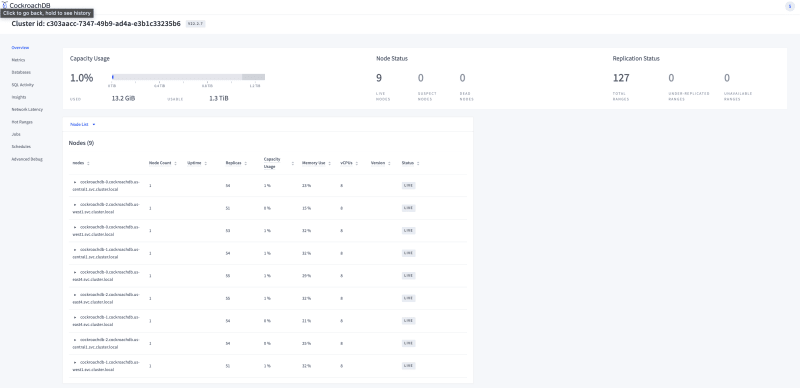
Created a new user management schema with some relational tables like User, Appointments, Locations etc and loaded the tables with at-least 1M records per table.
We inserted data using the patterns adopted from the reference blog by my co-author @jhatcher9999 :To simulate the db to behave as an active system with constant reads/writes, we used CRDB's open source tool Workload tool- QueryBench(tailored to this schema).
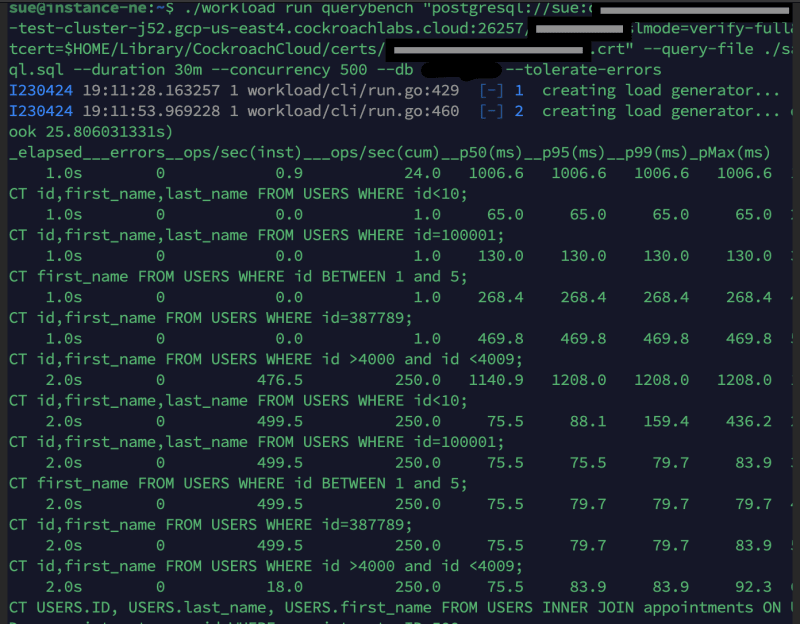
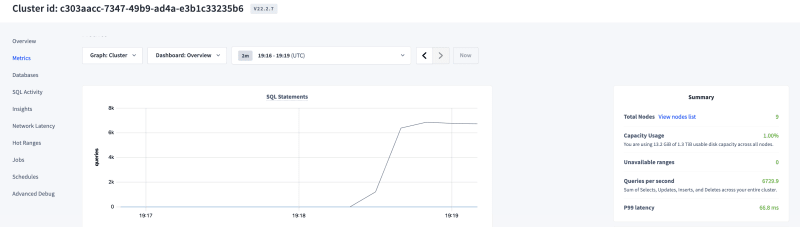
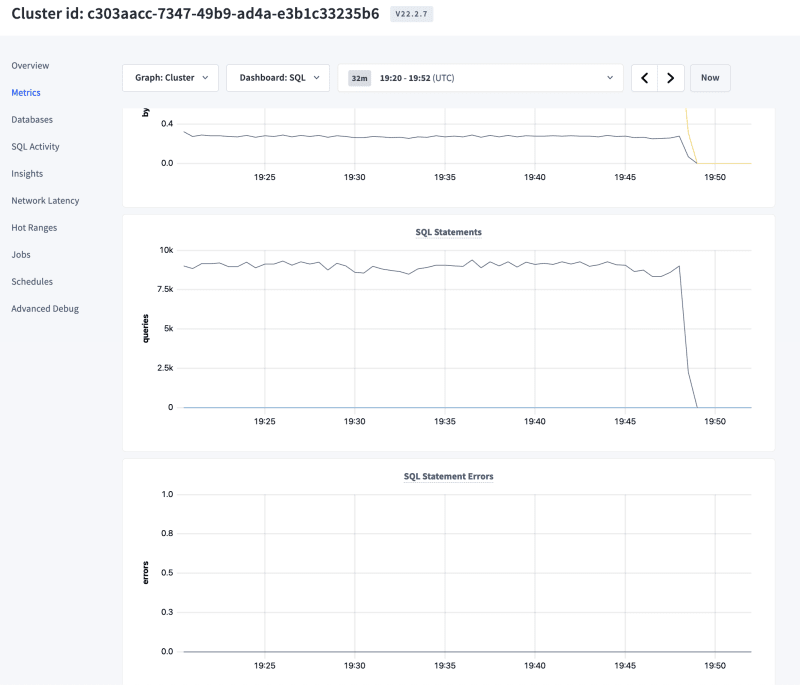
In the above Database Console, you can notice the QPS is about 10K & the system is now active by accepting both reads/writes through the workload tool, Query Bench.
After the pre-work is completed, You can use one of many ways to connect to the clusters' sql shell to test the different scenarios for Altering the schema.
Alter Table to Add a New Column
For the first scenario, let's add a column to an existing table 'users' and see how the db handles it.
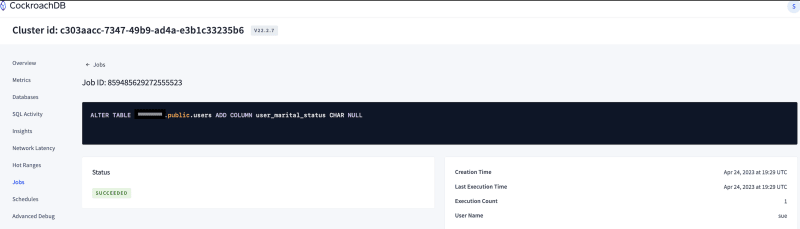
ALTER TABLE USERS ADD COLUMN user_marital_status CHAR(1) NULL;
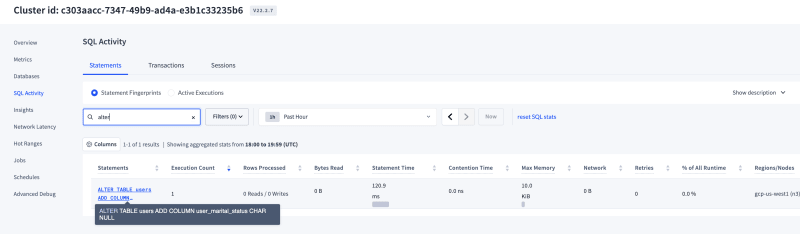
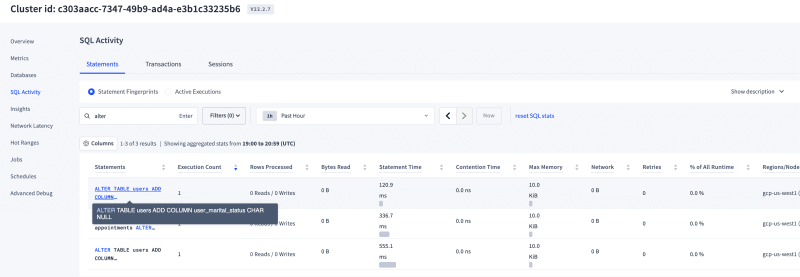
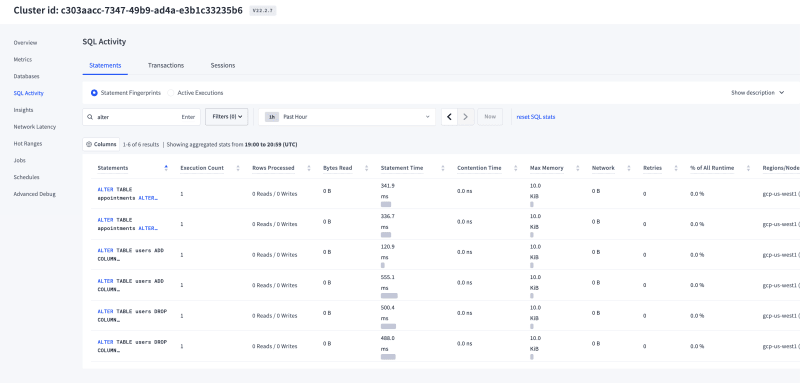
- Observations:The total time for executing the
alterwas around 120ms and as soon as the alter command was issued, a background job was created under thejobssection in the console & you could monitor the status of this DDL statement from here.

Alter Table to Add a New Column with Backfill
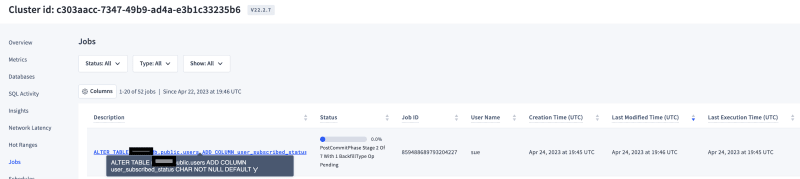
For this second scenario, we are adding a column to users table with a backfill.
ALTER TABLE USERS ADD COLUMN user_subscribed_status CHAR(1) NOT NULL DEFAULT 'y';
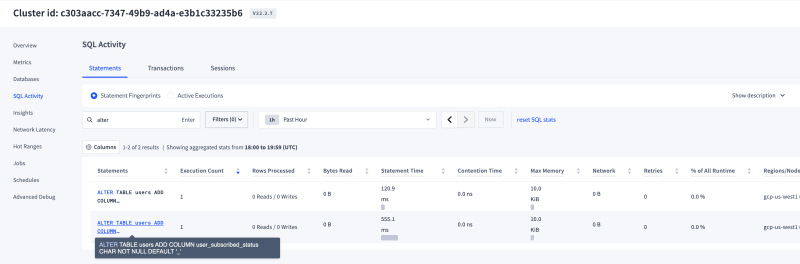
- Observations: Users table has 6M records and Adding a column with backfill to this table took a little longer than the previous scenario & I noticed that the background job was created for this statement as well and I could monitor/manage the status through the console. Also, the active reads/writes to the system were never affected during this change as you can see in the image below from the DB console.

Alter the Table's Primary Key
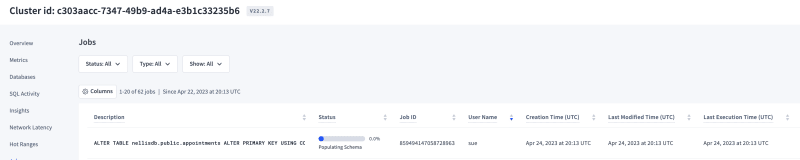
For this scenario, We'll be testing how the system reacts to changing a primary key for the table while the system is actively taking requests for reads/writes.
ALTER TABLE appointments ALTER PRIMARY KEY USING COLUMNS (id, userid);
- Observations: Altering the primary key was almost instantaneous & seamless. Total time of execution was under 120ms.There was a background job which took care of the changes under the covers & none of the reads/writes were affected while doing so.

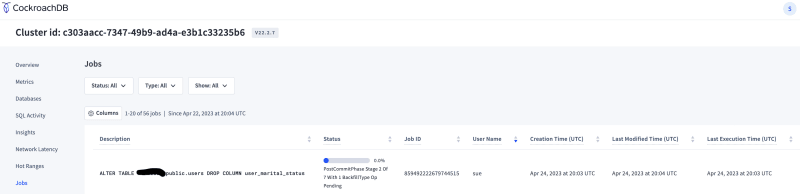
Drop the newly added columns in the table
This scenario is just to test dropping any unused columns form the table. In our case, we wanted to drop the two columns which we just added, one without a backfill & the other with a backfill.
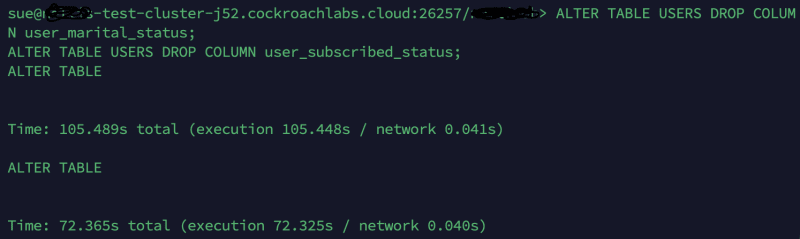
ALTER TABLE USERS DROP COLUMN user_marital_status;
ALTER TABLE USERS DROP COLUMN user_subscribed_status;
- Observations: We ran both the commands back to back & the system did create a job on the background to monitor the statement and did not notice any errors while the columns were being dropped and the requested were still served without any issues by the DB.
Revert the primary key to original
For the final scenario, we just reverted the primary key to go back to using just the Id for the appointments table.
ALTER TABLE appointments ALTER PRIMARY KEY USING COLUMNS (id);
- Observations: After running the
Alter, I immediately noticed that a background job was created for processing the changes & the sql shell returned as soon the changes were completed. There were no errors in serving the reads/writes for this scenario as well.

Conclusion
Overall, we ran the above scenarios and the database handled them exceptionally well. We did not run into any errors or retries for the reads/writes from the workload, so the system was continuously able to handle requests during the schema changes. Also, these jobs that were being created for these DDL statements in the background can be both monitored & managed so that you can pause/resume them on the go.
you can refer to the below screenshots for total list of statements with their execution timings and notice zero sql errors during execution. so, that's how the online schema change problem was resolved for good by CockroachDB & the entire DB kingdom lived happily ever after.
Special Thanks to my friend @jhatcher9999 for collaborating on this article with me and making this exercise more fun & exciting.





Top comments (0)